标签:不同 关系 数据 bugs shuff 它的 如何 local stage
概述
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
示例代码如下:
def main(args: Array[String]): Unit = { val sc: SparkContext = new SparkContext(new SparkConf() .setMaster("local[*]").setAppName("spark"))
val f: RDD[(String, Int)] = sc.parallelize(Array("hello,spark", "hello,scala", "hello,world")) .flatMap(_.split(" ")) .map((_, 1))
print(f.toDebugString)//查看依赖信息 println(f.dependencies)//查看依赖类型 }
它的依赖信息如下:
(8) MapPartitionsRDD[2] at map at Lineage.scala:11 []
| MapPartitionsRDD[1] at flatMap at Lineage.scala:10 []
| ParallelCollectionRDD[0] at parallelize at Lineage.scala:9 []
从上往下,依次是RDD的转换过程。通过这些信息,当链条中的任意一个RDD的部分分区数据丢失时,它可以根据这些信息重新进行运算,恢复丢失的分区数据。
窄依赖、宽依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用。窄依赖我们形象的比喻为独生子女。
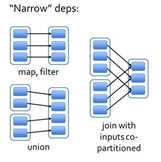
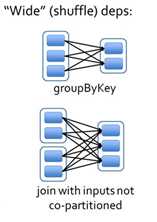
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle.宽依赖我们形象的比喻为超生
任务划分
RDD任务切分分为:Application、Job、Stage和Task
1)Application:初始化一个SparkContext即生成一个ApplicationMaster
2)Job:一个Action算子就会生成一个Job
3)Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖(shuffle)则划分一个Stage。
对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
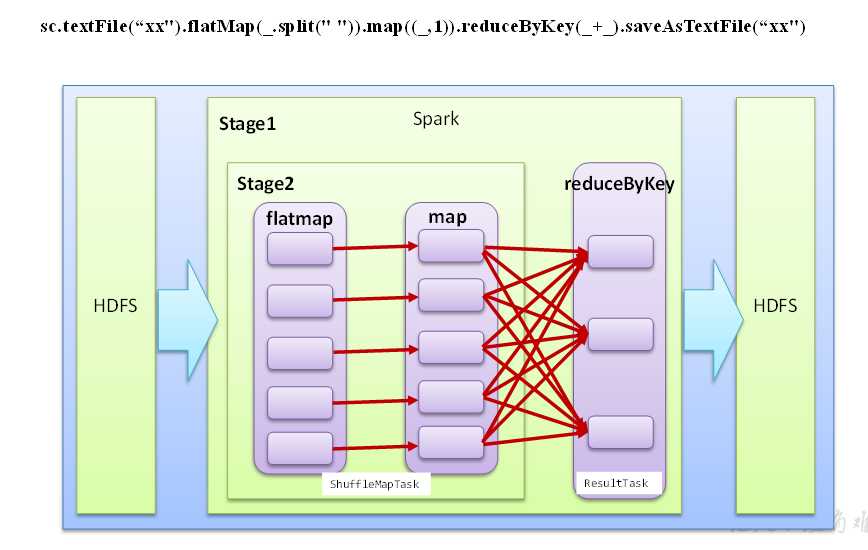
阶段划分过程如下:
首先无论如何要有一个阶段,这是一个总体的阶段。然后再看中间有多少个shuffle过程,遇到一个shuffle,则切分出一个阶段。
textFile方法从HDFS文件系统读取数据;flatMap,map方法均没有shuffle过程,不能形成阶段;reduceByKey有shuffle过程,可以形成阶段。总共有两个阶段。
标签:不同 关系 数据 bugs shuff 它的 如何 local stage
原文地址:https://www.cnblogs.com/chxyshaodiao/p/12329811.html