标签:clu span 判断 不变性 problem 控制 str ini ring
Abstract
• 从图正则数据重构方面处理无监督特征选择;
• 模型的思想是所选特征不仅通过图正则保留了原始数据的局部结构,也通过线性组合重构了每个数据点;
• 所以重构误差成为判断所选特征质量的自然标准。
• 通过最小化重构误差,选择最好保留相似性和判别信息的特征;
1 Introduction
• 目前有两大类无监督特征选择算法:Similarity preserving 和 clustering performance maximization;Similarity preserving 算法选择最好保留原始数据的局部结构的代表性特征。例如,如果数据点在原始空间分布很近,那么在选择的特征上也应该分布很近;clustering performance maximization 选择能最大化某个聚类标准的判别特征。例如,引入伪标签选择最大化数据聚类效果的判别特征。
• 模型的目标是选择能同时最好保留数据在原始空间的局部结构和判别信息的特征。
• highlight:
(1)从图正则数据重构的角度考虑无监督特征选择问题。通过最小化图正则重构误差,我们选择了最好保留数据结构和判别信息的特征;
(2)通过在混合目标函数上的稀疏学习考虑特征选择问题。引入了一个 l1-norm 稀疏项作用于特征选择矩阵,特征选择矩阵的稀疏性减少了冗余和噪声特征;
(3)提出了一个迭代梯度算法。
2 Related Work
2.1 Similarity Preserving Based Feature Selection
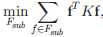
f 是特征向量,K 是预先定义的 Affinity 矩阵。因此,与流形结构相一致的特征被认为是重要的。
2.2 Clustering Based Feature Selection
clustering based feature selection 目标是选择判别特征
3 The Problem Of Graph Regularized Feature Selection With Data Reconstruction
进行了一些符号说明
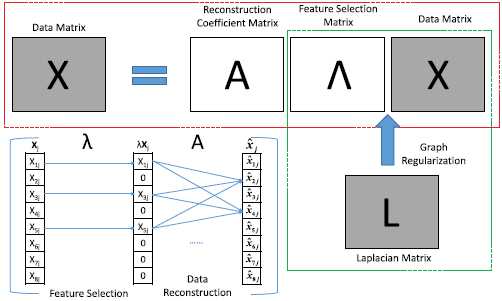
特征选择矩阵的学习同时保留了数据重构过程和图正则化过程。
4 The Objective Function
• 我们希望原始数据在所选特征上有一个紧致的表示,即 信息损失最小以及数据的局部结构也得到保留;
• 从所选特征上重构原始数据第 i 维的信息损失表示为:
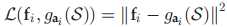
全局数据重构误差为:
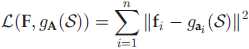
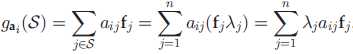
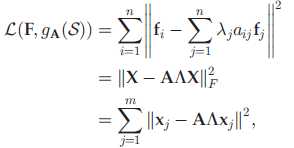 • 进一步,局部不变性。如果两个数据点在原始空间距离相近,那么在所选特征的投影上距离也相近。
• 进一步,局部不变性。如果两个数据点在原始空间距离相近,那么在所选特征的投影上距离也相近。
通过最小化下式,保留数据在所选特征上的局部几何信息:
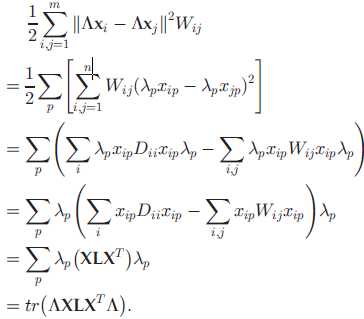
• 模型为:
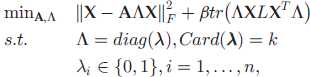
但是上述模型难以求解,需要分支定界法。于是将约束放松
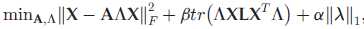
beta 是平衡对判别信息和相似性的保留。当 beta 较大时,保留相似性。当 beta 较小时,保留判别信息;alpha 控制所选特征的数目。
5 The Optimization
6 Experiment Results
7 Conclusion
判别信息通过最小化数据重构误差保留,相似性通过图正则保留。
Graph Regularized Feature Selection with Data Reconstruction
标签:clu span 判断 不变性 problem 控制 str ini ring
原文地址:https://www.cnblogs.com/klw6/p/12339762.html