标签:爬虫 def slist sep for pre nss guid 打开
获取淘宝搜索页面信息,提取商品名称和价格
1、 淘宝搜索接口
2、 翻页处理
import requests
import re
## 获取页面
def getHTMLText(url):
kv = {
‘cookie‘: ‘miid=421313831459957575; _samesite_flag_=true; cookie2=1cd225d128b8f915414ca1d56e99dd42; t=5b4306b92a563cc96ffb9e39037350b4; _tb_token_=587ae39b3e1b8; cna=DmpEFqOo1zMCAdpqkRZ0xo79; unb=643110845; uc3=nk2=30mP%2BxQ%3D&id2=VWsrWqauorhP&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dBxdz4jRii0h%2Bs3pw%3D; csg=f54462ca; lgc=%5Cu5939zhi; cookie17=VWsrWqauorhP; dnk=%5Cu5939zhi; skt=906cb7efa634723b; existShop=MTU4MjI5Mjk4NQ%3D%3D; uc4=id4=0%40V8o%2FAfalcPHRLJCDGtb%2Fdp1gVzM%3D&nk4=0%403b07vSmMRqc2uEhDugyrBg%3D%3D; publishItemObj=Ng%3D%3D; tracknick=%5Cu5939zhi; _cc_=UIHiLt3xSw%3D%3D; tg=0; _l_g_=Ug%3D%3D; sg=i54; _nk_=%5Cu5939zhi; cookie1=AnPBkeBRJ7RXH1lHWy9jEkFiHPof0dsM6sKE2hraCKY%3D; enc=gTfBHQmDAXUW0nTwDZWT%2BXlVfPmDqVQdFSKTby%2BoWsATGTG4yqih%2FJwqG7BvGfl1N%2Bc1FeptT%2BWNjgCnd3%2FX9Q%3D%3D; __guid=154677242.2334981537288746500.1582292984682.7253; mt=ci=25_1; v=0; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; JSESSIONID=6A1CD727C830F88997EE7A11C795F670; uc1=cookie14=UoTUOLFGTPNtWQ%3D%3D&lng=zh_CN&cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D&existShop=false&cookie21=URm48syIYn73&tag=8&cookie15=URm48syIIVrSKA%3D%3D&pas=0; monitor_count=4; isg=BGRk121i5pgW-RJU8ZZzF7W5NWJW_Yhn96AFLn6F6C_yKQXzpgzI9-XL6IExt8C_; l=cBjv7QE7QsWpTNssBOCiNQhfh1_t7IRf6uSJcRmMi_5p21T_QV7OoWj0Ve96DjWhTFLB4IFj7TyTxeW_JsuKHdGJ4AadZ‘,
‘user-agent‘: "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"}
try:
r = requests.get(url, headers=kv, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
## 解析页面信息
def parsePage(ilt, html):
try:
ptl = re.findall(r‘\"view_price\"\:\"[\d\.]*\"‘, html) ## 价格 "view_price":"23.00"
tlt = re.findall(r‘\"raw_title\"\:\".*?\"‘, html) ## 商品名称 "raw_title":"苹果数据线短iphone充电线6六8pl"
slt = re.findall(r‘\"nick\"\:\".*?\"‘, html) ## 店铺名称 "nick":"普雷达旗舰店"
for i in range(len(ptl)):
price = eval(ptl[i].split(‘:‘)[1])
title = eval(tlt[i].split(‘:‘)[1])
nick = eval(slt[i].split(‘:‘)[1])
ilt.append([price, title, nick])
except:
print(‘解析失败‘)
## 输出商品信息
def printGoodsList(ilt):
tplt = ‘{0:4}\t{1:8}\t{2:<100}\t{3:<8}‘
print(tplt.format(‘序号‘,‘价格‘,‘商品名称‘,‘店铺名称‘))
count = 0
for g in ilt:
count += 1
print(tplt.format(count, g[0], g[1], g[2]))
def main():
goods = ‘数据线‘
depth = 2 #设定向下一页爬取地深度
start_url = ‘https://s.taobao.com/search?q=‘ + goods
infoList = []
for i in range(depth):
try:
url = start_url + ‘&s=‘ + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
结果【排版有点问题】:

爬取不到任何内容处理:
原因:由于淘宝的设置,虽然可以requests爬取页面内容,但正则表达式会匹配不到任何内容;
解决:替换headers,模拟浏览器向服务器发起请求
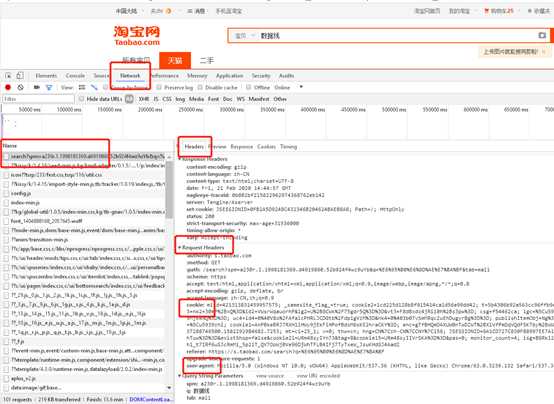
1、 查找浏览器headers(360浏览器)
先打开需要爬取的淘宝页面
F12进入开发者工具
选择Network—Name—第一条请求—Headers—Request Headers—复制cookie和user-agent
2、将复制的cookie和user-agent作为程序的Headers
def getHTMLText(url):
kv = {
‘cookie‘: ‘miid=421313831459957575; _samesite_flag_=true; cookie2=1cd225d128b8f915414ca1d56e99dd42; t=5b4306b92a563cc96ffb9e39037350b4; _tb_token_=587ae39b3e1b8; cna=DmpEFqOo1zMCAdpqkRZ0xo79; unb=643110845; uc3=nk2=30mP%2BxQ%3D&id2=VWsrWqauorhP&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dBxdz4jRii0h%2Bs3pw%3D; csg=f54462ca; lgc=%5Cu5939zhi; cookie17=VWsrWqauorhP; dnk=%5Cu5939zhi; skt=906cb7efa634723b; existShop=MTU4MjI5Mjk4NQ%3D%3D; uc4=id4=0%40V8o%2FAfalcPHRLJCDGtb%2Fdp1gVzM%3D&nk4=0%403b07vSmMRqc2uEhDugyrBg%3D%3D; publishItemObj=Ng%3D%3D; tracknick=%5Cu5939zhi; _cc_=UIHiLt3xSw%3D%3D; tg=0; _l_g_=Ug%3D%3D; sg=i54; _nk_=%5Cu5939zhi; cookie1=AnPBkeBRJ7RXH1lHWy9jEkFiHPof0dsM6sKE2hraCKY%3D; enc=gTfBHQmDAXUW0nTwDZWT%2BXlVfPmDqVQdFSKTby%2BoWsATGTG4yqih%2FJwqG7BvGfl1N%2Bc1FeptT%2BWNjgCnd3%2FX9Q%3D%3D; __guid=154677242.2334981537288746500.1582292984682.7253; mt=ci=25_1; v=0; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; JSESSIONID=6A1CD727C830F88997EE7A11C795F670; uc1=cookie14=UoTUOLFGTPNtWQ%3D%3D&lng=zh_CN&cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D&existShop=false&cookie21=URm48syIYn73&tag=8&cookie15=URm48syIIVrSKA%3D%3D&pas=0; monitor_count=4; isg=BGRk121i5pgW-RJU8ZZzF7W5NWJW_Yhn96AFLn6F6C_yKQXzpgzI9-XL6IExt8C_; l=cBjv7QE7QsWpTNssBOCiNQhfh1_t7IRf6uSJcRmMi_5p21T_QV7OoWj0Ve96DjWhTFLB4IFj7TyTxeW_JsuKHdGJ4AadZ‘,
‘user-agent‘: "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"}
try:
r = requests.get(url, headers=kv, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
标签:爬虫 def slist sep for pre nss guid 打开
原文地址:https://www.cnblogs.com/motoharu/p/12343758.html