标签:amp 卡尔 二叉树 带来 判断 树根 它的 例题 return
有点特定的知识点,不过还是需要补的
模板:

int ls[N],rs[N]; int val[N],dis[N],fa[N]; //将根为x,y的两个堆合并 返回合并后的根 int merge(int x,int y) { if(!x || !y) return x+y; //此为小根堆 记得对于pair等类型在此处重载比较 if(val[x]>val[y]) swap(x,y); int &L=ls[x],&R=rs[x]; R=merge(R,y); fa[R]=x; if(dis[L]<dis[R]) swap(L,R); dis[x]=dis[R]+1; return x; } //将根为x的堆弹出堆顶 void pop(int x) { val[x]=-1; fa[ls[x]]=ls[x],fa[rs[x]]=rs[x]; fa[x]=merge(ls[x],rs[x]); } int find(int a) { if(fa[a]==a) return a; return fa[a]=find(fa[a]); }
~ 简介 ~
支持快速合并的堆;单次合并复杂度$O(logn)$
~ 左偏 ~
堆的性质就不加赘述了,但是左偏的性质还是有点意思的
左偏指的是:对于每个节点,都保证 其左儿子到叶节点的最短距离 大于等于 其右儿子到叶节点的最短距离
这能保证一个性质:从根节点一直向右走到叶节点的这条链,长度是不超过$logn$的
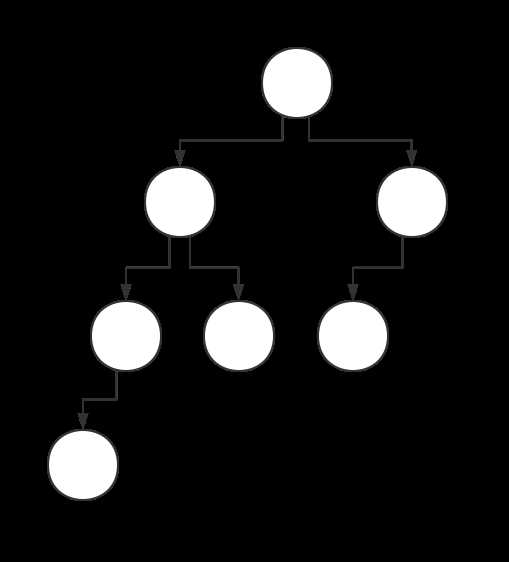
证明比较显然:若要保证树左偏,那么将树按照最右链的深度横着切一刀,应该是一棵满二叉树,则总节点数为$2^{\text{深度}}$
~ 合并 ~
最右链的深度为$logn$的性质有助于我们将两棵左偏树合并
我们考虑每次将两个树的根相比(默认位小根堆),将较小的那个置为合并后的根;然后将另一个根递归下去,与较小根的右儿子进行比较
一直这样比下去,那么在过程中可能选为子树根的的元素只有可能出现在原来两树的最右链上,而这两个最右链上的元素是$logn$级别的,故总时间复杂度为$O(logn)$
不过这样一次合并后的树不一定满足左偏的性质了,故在回溯的过程中要对合并后的树进行调整
调整的过程不复杂:若左儿子到叶节点的最短距离 小于 右儿子到叶节点的最短距离,交换左右儿子即可
//将根为x,y的两个堆合并 返回合并后的根 int merge(int x,int y) { if(!x || !y) return x+y; //此处为小根堆 if(val[x]>val[y]) swap(x,y); int &L=ls[x],&R=rs[x]; R=merge(R,y); fa[R]=x;//fa的作用后面会涉及 if(dis[L]<dis[R]) swap(L,R); dis[x]=dis[R]+1; return x; }
利用merge函数,也可以轻松的完成插入与弹出
插入比较简单,将待插入节点初始化、赋值后merge到希望插入的堆中就行了
弹出堆顶,将根的左右儿子合并即可
//将根为x的堆弹出堆顶 void pop(int x) { val[x]=-1; fa[ls[x]]=ls[x],fa[rs[x]]=rs[x]; fa[x]=merge(ls[x],rs[x]); }
在上面的merge与pop函数中都出现了$fa$数组,它有什么意义呢?
如果简简单单将两棵左偏树合并,那么我们并不能维护每个元素在合并后处于哪一棵树中
所以可以考虑用树的根来作为处于哪一棵树中的判断依据:如果两个节点所在树的根相同,它们显然在同一棵树中
这个合并、维护根的过程,很容易让我们联想到一种简单高效的数据结构——并查集
$fa[i]$表示节点$i$的父亲,一直往父亲走就可以知道根是哪个了
不过,左偏的性质仅仅能保证最右链的深度不会很大,整棵树中仍有可能存在很深的节点:一棵一直向左延伸的树也满足左偏的要求
所以我们不能满足于暴力向上爬,必须使用其它技巧
首先想到的就是路径压缩
不过我们在pop函数中,需要将一个元素从堆中弹出,这是否会影响路径压缩的正确性呢?因为正常的路径压缩是不能删边的
其实不会
我们弹出一个元素,是让它不能通过$ls,rs$来访问,但这并不意味着我们不能继续利用它的$fa$:我们可以将这个元素当做一个虚拟节点
假设在弹出堆顶以后,左儿子将作为新的根,那么我们将被弹出元素的$fa$指向左儿子,这显然会让指向原来堆顶的元素转而最终指向左儿子,并不会带来任何问题
不过在pop函数中需要先将两个儿子的$fa$都设成自己
(在pop调用的merge之中,会将合并后非根节点的$fa$指向新根,再加上虚拟节点的帮助,所有节点最终都能指向新根)
int find(int a) { if(fa[a]==a) return a; return fa[a]=find(fa[a]); }
~ 例题 ~
Luogu P3377 (【模板】左偏树(可并堆))
需要利用$fa$来判断每个数属于哪个堆,$val[i]=-1$表示已被删除
#include <cstdio> #include <cstring> #include <algorithm> using namespace std; const int N=100005; int ls[N],rs[N]; int val[N],dis[N],fa[N]; //将根为x,y的两个堆合并 返回合并后的根 int merge(int x,int y) { if(!x || !y) return x+y; //此处为小根堆 if(val[x]>val[y]) swap(x,y); int &L=ls[x],&R=rs[x]; R=merge(R,y); fa[R]=x; if(dis[L]<dis[R]) swap(L,R); dis[x]=dis[R]+1; return x; } //将根为x的堆弹出堆顶 void pop(int x) { val[x]=-1; fa[ls[x]]=ls[x],fa[rs[x]]=rs[x]; fa[x]=merge(ls[x],rs[x]); } int find(int a) { if(fa[a]==a) return a; return fa[a]=find(fa[a]); } int n,m; int main() { scanf("%d%d",&n,&m); for(int i=1;i<=n;i++) scanf("%d",&val[i]),fa[i]=i; while(m--) { int opt,x,y; scanf("%d%d",&opt,&x); if(opt==1) { scanf("%d",&y); if(val[x]<0 || val[y]<0) continue; x=find(x),y=find(y); if(x!=y) merge(x,y); } else { if(val[x]>0) x=find(x); printf("%d\n",val[x]); if(val[x]>0) pop(x); } } return 0; }
Luogu P1152 (派遣,$APIO2012$)
显然可以尝试让每个忍者都成为管理者,那么问题就转化成了求一个子树内最多能选出多少个人
最优的情况是选出子树中薪水最少的人
那么我们就需要动态地维护薪水最少、且总薪水不超过$m$的节点的集合;这可以通过大根堆来实现
对于当前节点,我们将其儿子的堆都合并上去,那么总薪水可能就超过$m$了,于是不停地将最大的节点弹出、直到总薪水小于等于$m$就可以了
#include <cstdio> #include <vector> #include <cstring> #include <algorithm> using namespace std; typedef long long ll; const int N=100005; int ls[N],rs[N]; int val[N],dis[N],fa[N]; //将根为x,y的两个堆合并 返回合并后的根 int merge(int x,int y) { if(!x || !y) return x+y; //此处为大根堆 if(val[x]<val[y]) swap(x,y); int &L=ls[x],&R=rs[x]; R=merge(R,y); fa[R]=x; if(dis[L]<dis[R]) swap(L,R); dis[x]=dis[R]+1; return x; } //将根为x的堆弹出堆顶 void pop(int x) { val[x]=-1; fa[ls[x]]=ls[x],fa[rs[x]]=rs[x]; fa[x]=merge(ls[x],rs[x]); } int find(int a) { if(fa[a]==a) return a; return fa[a]=find(fa[a]); } int n,m,root; int mul[N],num[N],sum[N]; vector<int> v[N]; ll ans; void dfs(int x) { for(int i=0;i<v[x].size();i++) { int y=v[x][i]; dfs(y); merge(find(x),find(y)); num[x]+=num[y]; sum[x]+=sum[y]; while(sum[x]>m) { sum[x]-=val[find(x)]; num[x]--; pop(find(x)); } } ans=max(ans,1LL*mul[x]*num[x]); } int main() { scanf("%d%d",&n,&m); for(int i=1;i<=n;i++) { int x; scanf("%d%d%d",&x,&val[i],&mul[i]); fa[i]=i,num[i]=1,sum[i]=val[i]; if(!x) root=i; else v[x].push_back(i); } dfs(root); printf("%lld\n",ans); return 0; }
HDU 5575 ($Discover\ Water\ Tank$,$2015ICPC$上海)
之前用的是笛卡尔树+倍增,确实比左偏树麻烦太多...
我们按照隔板高度从小到大来合并相邻两个区间,并计算不灌满/灌满该区间(灌满指的是灌到隔板的高度)所能满足的最多query数$dp[i][0],dp[i][1]$
转移比较显然:$dp[i][0]=dp[L][0]+dp[R][0]$,$dp[i][1]=dp[L][1]+dp[R][1]$
考虑在一开始将所有的query扔到所在的格子中,那么一开始只有$z=0$的query被满足
对于枚举出的隔板,我们考虑对左右两侧分别灌水,初始的当前满足qeury数为$dp[i][1]$(若子区间没被灌满就不能继续灌水了),若遇到一个$z=0$的查询就让$cur--$,否则$cur++$;不停的用$cur$来更新答案
需要注意的一个细节是,对于$y$相同的query,需要将$z=0$的放在前面;因为按理说这些query需要同时被处理,但是我们先处理$z=0$的并不会影响答案的正确性,但若先处理$z=1$的可能会使$cur$变得过大
维护隔板隔开的区间需要再整一个并查集
这题中,为了确定某一个格子对应的是哪一个左偏树,我的做法是先给每个格子一个节点,$val$赋为$INF$,再将query跟这些节点合并;这样处理就不用什么特判了
#include <cstdio> #include <cstring> #include <algorithm> using namespace std; const int N=300005; const int INF=1<<30; int tot,ls[N],rs[N]; int val[N],tag[N],dis[N],fa[N]; //将根为x,y的两个堆合并 返回合并后的根 int merge(int x,int y) { if(!x || !y) return x+y; //此处为小根堆 if(val[x]>val[y] || (val[x]==val[y] && tag[x]>tag[y])) swap(x,y); int &L=ls[x],&R=rs[x]; R=merge(R,y); fa[R]=x; if(dis[L]<dis[R]) swap(L,R); dis[x]=dis[R]+1; return x; } //将根为x的堆弹出堆顶 void pop(int x) { val[x]=-1; fa[ls[x]]=ls[x],fa[rs[x]]=rs[x]; fa[x]=merge(ls[x],rs[x]); } int find(int a) { if(fa[a]==a) return a; return fa[a]=find(fa[a]); } int n,m; int h[N],ord[N]; inline bool cmp(int x,int y) { return h[x]<h[y]; } int lmost[N],dp[N][2]; int Find(int x) { if(lmost[x]==x) return x; return lmost[x]=Find(lmost[x]); } void solve(int x,int lim) { int cur=dp[x][1],tmp=max(dp[x][0],dp[x][1]); while(val[find(x)]<=lim) { cur+=tag[find(x)]; tmp=max(tmp,cur); pop(find(x)); } dp[x][0]=tmp,dp[x][1]=cur; } int main() { int T; scanf("%d",&T); for(int kase=1;kase<=T;kase++) { for(int i=1;i<=n+m;i++) ls[i]=rs[i]=0; scanf("%d%d",&n,&m); tot=n; for(int i=1;i<=n;i++) { val[i]=INF; lmost[i]=fa[i]=i; dp[i][0]=dp[i][1]=0; } for(int i=1;i<n;i++) { scanf("%d",&h[i]); ord[i]=i; } for(int i=1;i<=m;i++) { int x,y,z; scanf("%d%d%d",&x,&y,&z); ++tot; dp[x][1]+=1-z; val[tot]=++y,tag[tot]=(!z?-1:1),fa[tot]=tot; merge(find(x),tot); } sort(ord+1,ord+n,cmp); for(int i=1;i<n;i++) { int id=ord[i]; int L=Find(id),R=id+1; solve(L,h[id]),solve(R,h[id]); dp[L][0]+=dp[R][0]; dp[L][1]+=dp[R][1]; merge(find(L),find(R)); lmost[R]=L; } solve(1,INF-1); printf("Case #%d: %d\n",kase,dp[1][0]); } return 0; }
个人感觉是不太容易碰到...?
(完)
标签:amp 卡尔 二叉树 带来 判断 树根 它的 例题 return
原文地址:https://www.cnblogs.com/LiuRunky/p/Leftist_Tree.html
