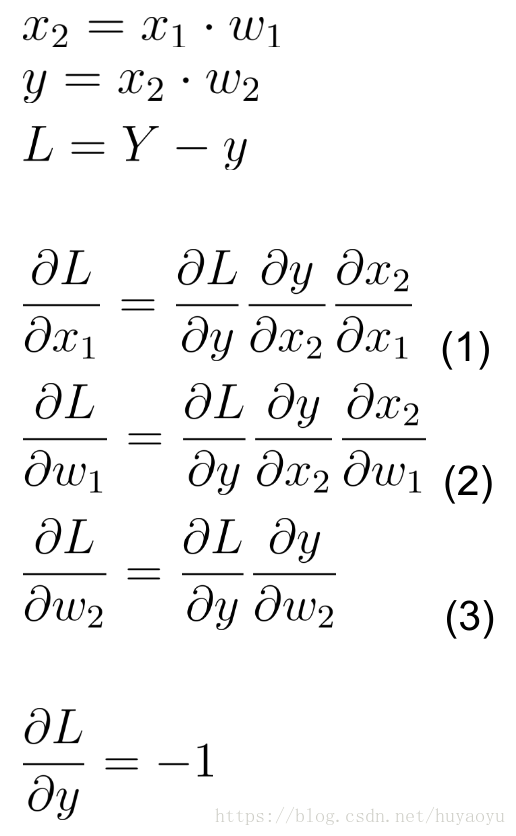标签:nes code str 神经网络 作用 ack 特定 赋值 nump
Pytorch在梯度方面提供的功能,大多是为神经网络而设计的。而官方文档给出的定义和解释比较抽象。以下将结合实例,总结一下自己对Pytorch中梯度计算backward函数的理解。
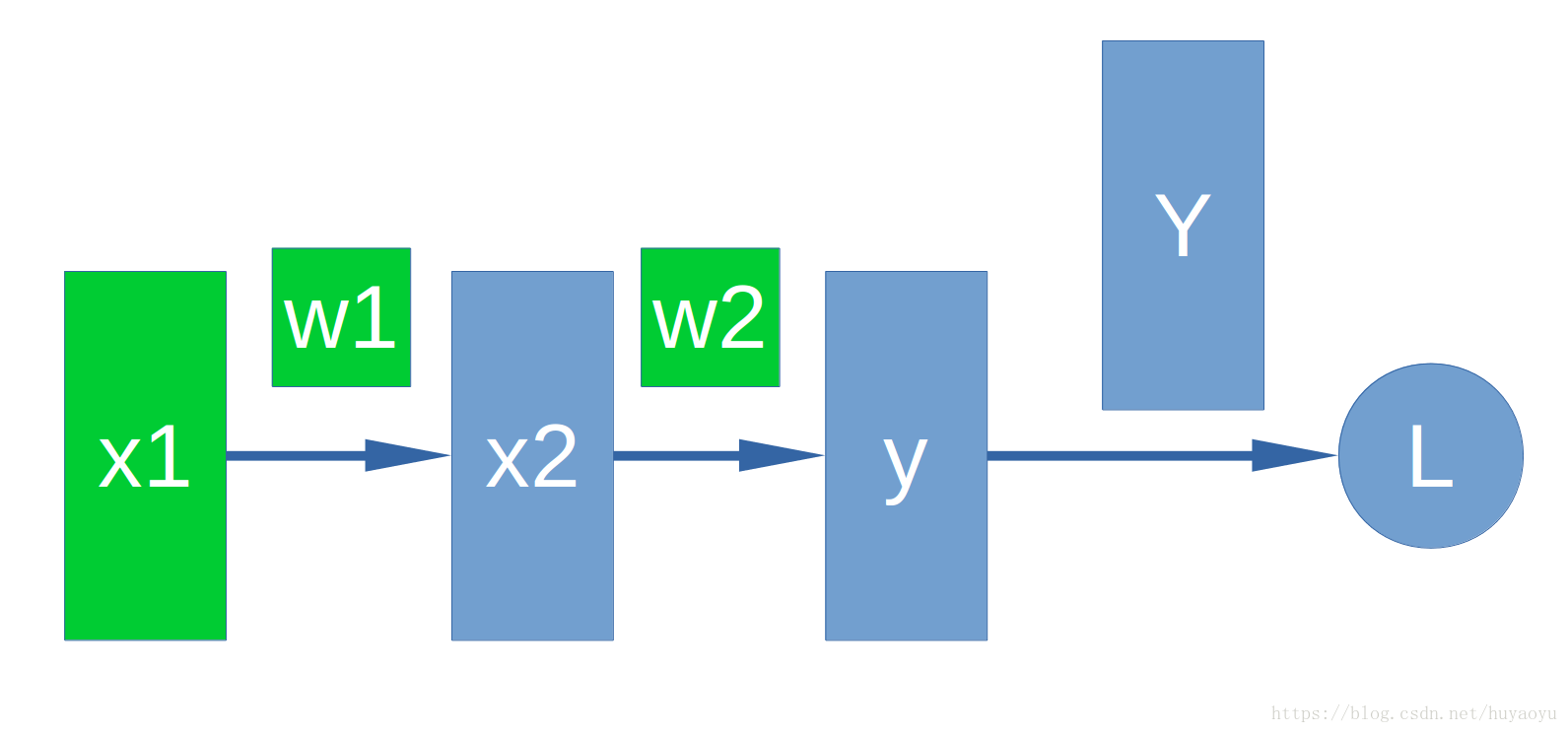
首先我们看一个非常简单的神经网络。
假设x1,x2是神经网络的中间层,y是我们的输出层,Y是真实值,L是loss。w1和w2是对应于x1和x2的weight。
上图用数学公式表示为:
通常我们会把x1,w1,w2,x2,y使用PyTorch的Tensor进行表示。L也可以用Tensor表示(维度可能与其他Tensor不同)。
其中,我们把需要自己设定的Tensor(即不是通过其他Tensor计算得来的)叫做叶子Tensor。比如x1,w1和w2就是所谓的叶子Tensor。
在pytorch中,我们把上述模型表示出来。
import torch
import numpy as np
x1 = torch.from_numpy( 2*np.ones((2, 2), dtype=np.float32) )
x1.requires_grad_(True) #设置该tensor可被记录操作用于梯度计算
w1 = torch.from_numpy( 5*np.ones((2, 2), dtype=np.float32) )
w1.requires_grad_(True)
print("x1 =", x1)
print("w1 =", w1)
x2 = x1 * w1
w2 = torch.from_numpy( 6*np.ones((2,2), dtype=np.float32) )
w2.requires_grad_(True)
print("x2 =", x2)
print("w2 =", w2)
y = x2 * w2
Y = torch.from_numpy( 10*np.ones((2,2), dtype=np.float32) )
print("y =", y)
print("Y =", Y)
L = Y - yx1 = tensor([[2., 2.],
[2., 2.]], requires_grad=True)
w1 = tensor([[5., 5.],
[5., 5.]], requires_grad=True)
x2 = tensor([[10., 10.],
[10., 10.]], grad_fn=<MulBackward0>)
w2 = tensor([[6., 6.],
[6., 6.]], requires_grad=True)
y = tensor([[60., 60.],
[60., 60.]], grad_fn=<MulBackward0>)
Y = tensor([[10., 10.],
[10., 10.]])上述代码注意:
上述前向传播计算完成后,想要计算反向传播(BP)的梯度。基本原理即为求导的链式法则。上述网络的求导即为:
PyTorch提供了backward函数用于计算梯度 ,这一求解过程变为:
L.backward(torch.ones(2, 2, dtype=torch.float))对于最后的Tensor L执行backward()函数,会计算之前参与运算并生成当前Tensor的叶子Tensor的梯度。其梯度值会保存在叶子Tensor的.grad属性中。
比如上述网络中,x1,w1和w2就是所谓的叶子Tensor。
print(x1.grad) # 查看L对于x1的梯度
print(w1.grad) # L对于w1的梯度
print(w2.grad)tensor([[-30., -30.],
[-30., -30.]])
tensor([[-12., -12.],
[-12., -12.]])
tensor([[-10., -10.],
[-10., -10.]])gradient 在PyTorch的官方文档上解释的比较晦涩,我理解这个参数表示的是网络的输出tensor对于调用backward()函数的Tensor的导数。
(1) 比如在我上述的模型输出tensor为L,当前要计算backward的tensor也为为L,则gradient表示为\(\frac{\partial L}{\partial L}=1\),也就是element全为1的Tensor。gradient维度需要调用backward()函数的Tensor的维度相同。即L.backward(torch.ones(2, 2, dtype=torch.float))。
(2) 又比如,假设我们不知道L关于y的函数表示,但知道L关于y的梯度(即\(\frac{\partial L}{\partial y}=-1\))时,我们可以通过y.backward(-1 * torch.ones(2, 2, dtype=torch.float))来完成BP过程。 这样的设计通过链式法则,可以在特定位置求梯度值。
(3) 对于L为标量(常数)的情况,可不指定任何参数,默认参数为torch.tensor(1)。对于L为高于1维的情况,则需要明确指定backward()的第一个参数。
(1) 默认同一个运算得到的Tensor仅能进行一次backward()。若要再次进行backward(),则要再次运算得到的Tesnor。
(2) 当多个Tensor从相同的源Tensor运算得到,这些运算得到的Tensor的backwards()方法将向源Tensor的grad属性中进行数值累加。
比如上述实例中,假设有另一个tensor L2是通过对x1的运算得到的,那么L2.backward()执行后梯度结果将累加到x1.grad中。
print("x1.grad =",x1.grad) # 原来x1的梯度
L2 = x1 * x1
L2.backward(torch.ones(2, 2, dtype=torch.float))
print("x1.grad =", x1.grad) # 计算L2的backward后梯度结果将累加到x1.grad中x1.grad = tensor([[-26., -26.],
[-26., -26.]])
x1.grad = tensor([[-22., -22.],
[-22., -22.]])(3) 只有叶子tensor(自己创建不是通过其他Tensor计算得来的)才能计算梯度。否则对于非叶子的x1执行L.backwar()后,x1.grad将为None。定义叶子节点时需注意要直接用torch创建且不能经过tensor计算。例如将实例中的x1定义改为x1 = 2 * torch.ones(2, 2, requires_grad=True, dtype=torch.float) 其实它已经做了tensor计算,x1将不再是叶子,表达式中torch.ones()才是叶子。
标签:nes code str 神经网络 作用 ack 特定 赋值 nump
原文地址:https://www.cnblogs.com/laiyaling/p/12343844.html