标签:cal 随机梯度 提高 参数文件 最小值 tar var final state
train.py:
# -*- coding: UTF-8 -*- """ 训练神经网络模型 大家之后可以加上各种的 name_scope(命名空间) 用 TensorBoard 来可视化 ==== 一些术语的概念 ==== # Batch size : 批次(样本)数目。一次迭代(Forword 运算(用于得到损失函数)以及 BackPropagation 运算(用于更新神经网络参数))所用的样本数目。Batch size 越大,所需的内存就越大 # Iteration : 迭代。每一次迭代更新一次权重(网络参数),每一次权重更新需要 Batch size 个数据进行 Forward 运算,再进行 BP 运算 # Epoch : 纪元/时代。所有的训练样本完成一次迭代 # 假如 : 训练集有 1000 个样本,Batch_size=10 # 那么 : 训练完整个样本集需要: 100 次 Iteration,1 个 Epoch # 但一般我们都不止训练一个 Epoch ==== 超参数(Hyper parameter)==== init_scale : 权重参数(Weights)的初始取值跨度,一开始取小一些比较利于训练 learning_rate : 学习率,训练时初始为 1.0 num_layers : LSTM 层的数目(默认是 2) num_steps : LSTM 展开的步(step)数,相当于每个批次输入单词的数目(默认是 35) hidden_size : LSTM 层的神经元数目,也是词向量的维度(默认是 650) max_lr_epoch : 用初始学习率训练的 Epoch 数目(默认是 10) dropout : 在 Dropout 层的留存率(默认是 0.5) lr_decay : 在过了 max_lr_epoch 之后每一个 Epoch 的学习率的衰减率,训练时初始为 0.93。让学习率逐渐衰减是提高训练效率的有效方法 batch_size : 批次(样本)数目。一次迭代(Forword 运算(用于得到损失函数)以及 BackPropagation 运算(用于更新神经网络参数))所用的样本数目 (batch_size 默认是 20。取比较小的 batch_size 更有利于 Stochastic Gradient Descent(随机梯度下降),防止被困在局部最小值) """ from utils import * from network import * def train(train_data, vocab_size, num_layers, num_epochs, batch_size, model_save_name, learning_rate=1.0, max_lr_epoch=10, lr_decay=0.93, print_iter=50): # 训练的输入 training_input = Input(batch_size=batch_size, num_steps=35, data=train_data) # 创建训练的模型 m = Model(training_input, is_training=True, hidden_size=650, vocab_size=vocab_size, num_layers=num_layers) # 初始化变量的操作 init_op = tf.global_variables_initializer() # 初始的学习率(learning rate)的衰减率 orig_decay = lr_decay with tf.Session() as sess: sess.run(init_op) # 初始化所有变量 # Coordinator(协调器),用于协调线程的运行 coord = tf.train.Coordinator() # 启动线程 threads = tf.train.start_queue_runners(coord=coord) # 为了用 Saver 来保存模型的变量 saver = tf.train.Saver() # max_to_keep 默认是 5, 只保存最近的 5 个模型参数文件 # 开始 Epoch 的训练 for epoch in range(num_epochs): # 只有 Epoch 数大于 max_lr_epoch(设置为 10)后,才会使学习率衰减 # 也就是说前 10 个 Epoch 的学习率一直是 1, 之后每个 Epoch 学习率都会衰减 new_lr_decay = orig_decay ** max(epoch + 1 - max_lr_epoch, 0) m.assign_lr(sess, learning_rate * new_lr_decay) # 当前的状态 # 第二维是 2 是因为对每一个 LSTM 单元有两个来自上一单元的输入: # 一个是 前一时刻 LSTM 的输出 h(t-1) # 一个是 前一时刻的单元状态 C(t-1) current_state = np.zeros((num_layers, 2, batch_size, m.hidden_size)) # 获取当前时间,以便打印日志时用 curr_time = datetime.datetime.now() for step in range(training_input.epoch_size): # train_op 操作:计算被修剪(clipping)过的梯度,并最小化 cost(误差) # state 操作:返回时间维度上展开的最后 LSTM 单元的输出(C(t) 和 h(t)),作为下一个 Batch 的输入状态 if step % print_iter != 0: cost, _, current_state = sess.run([m.cost, m.train_op, m.state], feed_dict={m.init_state: current_state}) else: seconds = (float((datetime.datetime.now() - curr_time).seconds) / print_iter) curr_time = datetime.datetime.now() cost, _, current_state, acc = sess.run([m.cost, m.train_op, m.state, m.accuracy], feed_dict={m.init_state: current_state}) # 每 print_iter(默认是 50)打印当下的 Cost(误差/损失)和 Accuracy(精度) print("Epoch {}, 第 {} 步, 损失: {:.3f}, 精度: {:.3f}, 每步所用秒数: {:.2f}".format(epoch, step, cost, acc, seconds)) # 保存一个模型的变量的 checkpoint 文件 saver.save(sess, save_path + ‘/‘ + model_save_name, global_step=epoch) # 对模型做一次总的保存 saver.save(sess, save_path + ‘/‘ + model_save_name + ‘-final‘) # 关闭线程 coord.request_stop() coord.join(threads) if __name__ == "__main__": if args.data_path: data_path = args.data_path train_data, valid_data, test_data, vocab_size, id_to_word = load_data(data_path) train(train_data, vocab_size, num_layers=2, num_epochs=70, batch_size=20, model_save_name=‘train-checkpoint‘)
运行结果(省去了一部分):
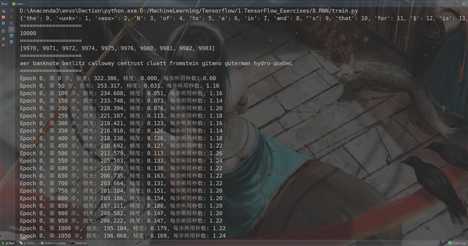
标签:cal 随机梯度 提高 参数文件 最小值 tar var final state
原文地址:https://www.cnblogs.com/SCCQ/p/12347120.html