标签:流式 enc syntax datanode end map family mon 配置
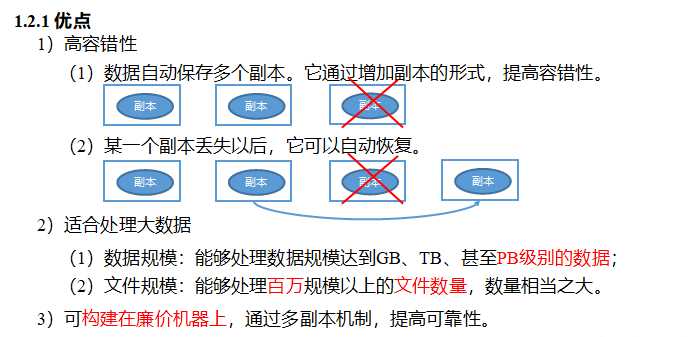
HDFS(Hadoop Distributed File System)是hadoop生态系统的一个重要组成部分,是hadoop中的的存储组件,在整个Hadoop中的地位非同一般,是最基础的一部分,因为它涉及到数据存储,MapReduce等计算模型都要依赖于存储在HDFS中的数据。HDFS是一个分布式文件系统,以流式数据访问模式存储超大文件,将数据分块存储到一个商业硬件集群内的不同机器上。
这里重点介绍其中涉及到的几个概念:(1)超大文件。目前的hadoop集群能够存储几百TB甚至PB级的数据。(2)流式数据访问。HDFS的访问模式是:一次写入,多次读取,更加关注的是读取整个数据集的整体时间。(3)商用硬件。HDFS集群的设备不需要多么昂贵和特殊,只要是一些日常使用的普通硬件即可,正因为如此,hdfs节点故障的可能性还是很高的,所以必须要有机制来处理这种单点故障,保证数据的可靠。(4)不支持低时间延迟的数据访问。hdfs关心的是高数据吞吐量,不适合那些要求低时间延迟数据访问的应用。(5)单用户写入,不支持任意修改。hdfs的数据以读为主,只支持单个写入者,并且写操作总是以添加的形式在文末追加,不支持在任意位置进行修改。

bin/hadoop fs 具体命令 或者 bin/hdfs dfs 具体命令
下面是常用的几个命令
(0)启动Hadoop集群(方便后续的测试)
$ sbin/start-dfs.sh
$ sbin/start-yarn.sh
(1)-help:输出这个命令参数
$ hadoop fs -help rm
(2)-ls: 显示目录信息
$ hadoop fs -ls /
(3)-mkdir:在HDFS上创建目录
$ hadoop fs -mkdir -p /sanguo/shuguo
(4)-moveFromLocal:从本地剪切粘贴到HDFS
$ touch kongming.txt
$ hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo
(5)-appendToFile:追加一个文件到已经存在的文件末尾
$ touch liubei.txt
$ vi liubei.txt
输入
san gu mao lu
执行
$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
(6)-cat:显示文件内容
$ hadoop fs -cat /sanguo/shuguo/kongming.txt
(7)-chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
$ hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt $ hadoop fs -chown atguigu:atguigu /sanguo/shuguo/kongming.txt
(8)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
$ hadoop fs -copyFromLocal README.txt /
(9)-copyToLocal:从HDFS拷贝到本地
$ hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./
(10)-cp :从HDFS的一个路径拷贝到HDFS的另一个路径
$ hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt
(11)-mv:在HDFS目录中移动文件
$ hadoop fs -mv /zhuge.txt /sanguo/shuguo/
(12)-get:等同于copyToLocal,就是从HDFS下载文件到本地
$ hadoop fs -get /sanguo/shuguo/kongming.txt ./
(13)-getmerge:合并下载多个文件,比如HDFS的目录 /user/atguigu/test下有多个文件:log.1, log.2,log.3,...
$ hadoop fs -getmerge /user/atguigu/test/* ./zaiyiqi.txt
(14)-put:等同于copyFromLocal
$ hadoop fs -put ./zaiyiqi.txt /user/atguigu/test/
(15)-tail:显示一个文件的末尾
$ hadoop fs -tail /sanguo/shuguo/kongming.txt
(16)-rm:删除文件或文件夹
$ hadoop fs -rm /user/atguigu/test/jinlian2.txt
(17)-rmdir:删除空目录
$ hadoop fs -mkdir /test
$ hadoop fs -rmdir /test
(18)-du统计文件夹的大小信息
$ hadoop fs -du -s -h /user/atguigu/test
2.7 K /user/atguigu/test
$ hadoop fs -du -h /user/atguigu/test
1.3 K /user/atguigu/test/README.txt
15 /user/atguigu/test/jinlian.txt
1.4 K /user/atguigu/test/zaiyiqi.txt
(19)-setrep:设置HDFS中文件的副本数量
$ hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt
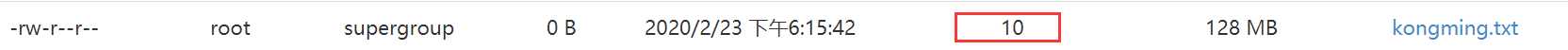
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
首先需要在本地电脑配制好hadoop的环境变量才可以
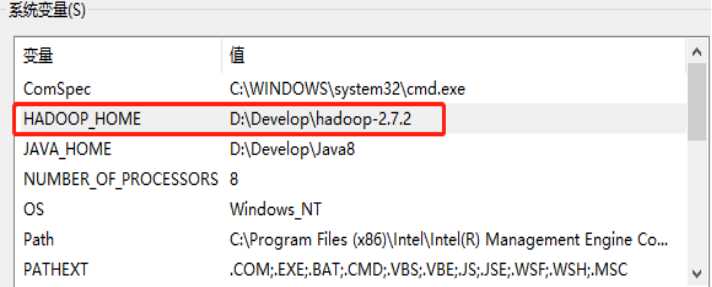
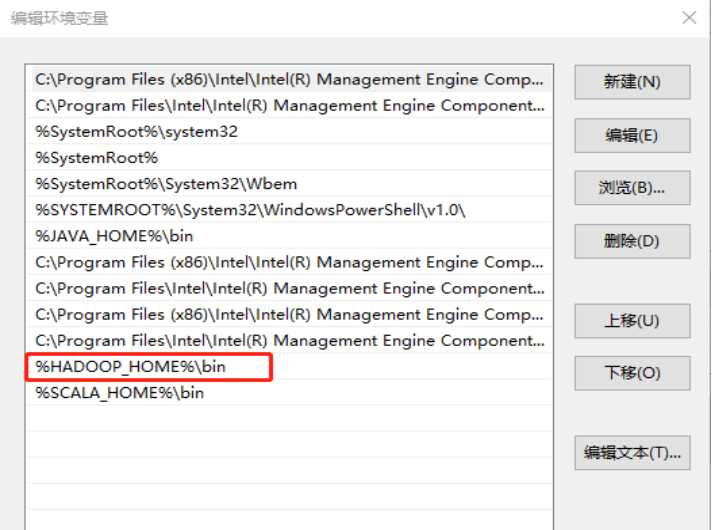
使用idea创建一个空的Maven项目,添加已下坐标
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
本次导入的坐标时间较长,需要耐心等待
需要在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
创建文件夹↓
@Test public void testMkdirs() throws IOException, InterruptedException, URISyntaxException { // 1 获取文件系统 Configuration configuration = new Configuration(); // 配置在集群上运行 // configuration.set("fs.defaultFS", "hdfs://hadoop102:9000"); // FileSystem fs = FileSystem.get(configuration); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root"); // 2 创建目录 fs.mkdirs(new Path("/1108/daxian/banzhang")); // 3 关闭资源 fs.close(); }
从本地上传文件↓
@Test public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException { // 1 获取文件系统 Configuration configuration = new Configuration(); configuration.set("dfs.replication", "2"); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root"); // 2 上传文件 fs.copyFromLocalFile(new Path("D:/banzhang.txt"), new Path("/banzhang.txt")); // 3 关闭资源 fs.close(); System.out.println("over"); }
标签:流式 enc syntax datanode end map family mon 配置
原文地址:https://www.cnblogs.com/g-cl/p/12348681.html