标签:git info elastic shu match mamicode sea its operator
https://blog.csdn.net/timothytt/article/details/86775114
es中match_phrase和term区别
原创7im0thyZhang 最后发布于2019-02-08 14:40:11 阅读数 2202 收藏
term是将传入的文本原封不动地(不分词)拿去查询。
match会对输入进行分词处理后再去查询,部分命中的结果也会按照评分由高到低显示出来。
match_phrase是按短语查询,只有存在这个短语的文档才会被显示出来。
也就是说,term和match_phrase都可以用于精确匹配,而match用于模糊匹配。
之前我以为match_phrase不会被分词,看来理解错了,其官方解释如下:
Like the match query, the match_phrase query first analyzes the query string to produce a list of terms. It then searches for all the terms, but keeps only documents that contain all of the search terms, in the same positions relative to each other.
总结下,这段话的3个要点:
match_phrase还是分词后去搜的
目标文档需要包含分词后的所有词
目标文档还要保持这些词的相对顺序和文档中的一致
只有当这三个条件满足,才会命中文档!
那么,term和match_phrase都可以实现按短语搜索,二者在实际使用中有啥区别呢。
【发现问题】
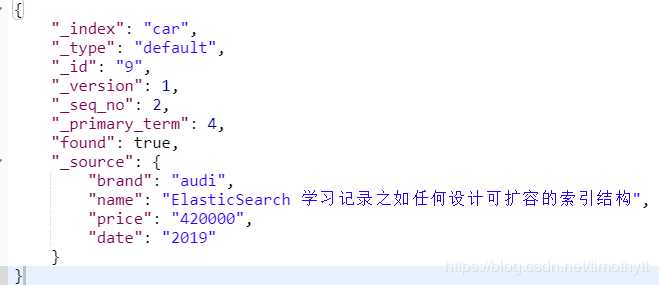
1.我们先放入一个文档:
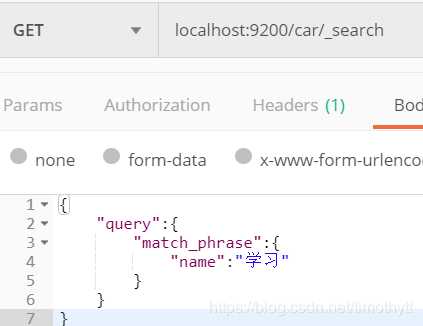
2.然后使用match_phrase搜索:
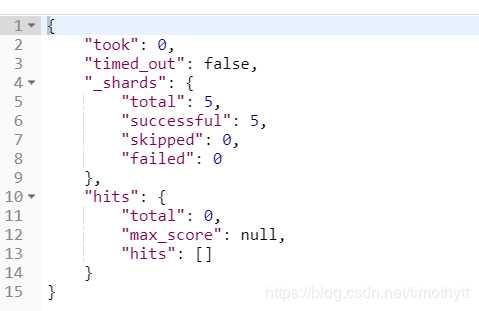
嗯,不出所料,搜索到了。
3.然后我们用term试试
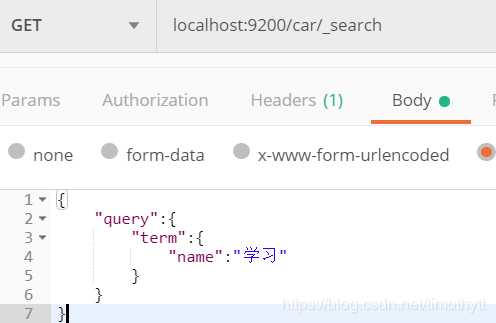
纳尼!!!居然没有?那么全句带进去搜总行了吧

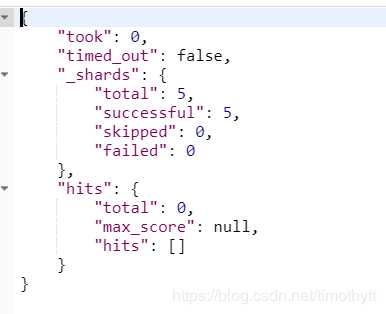
居然还是不行!!这就奇怪了。
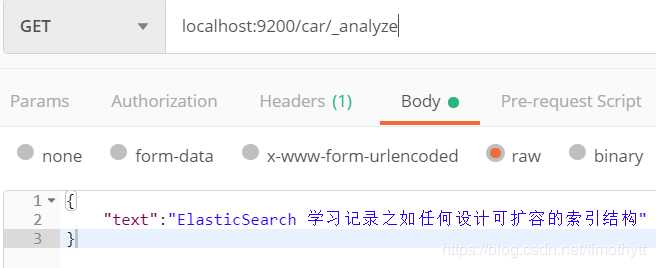
【问题分析】我们来看看这句话的分词结果:
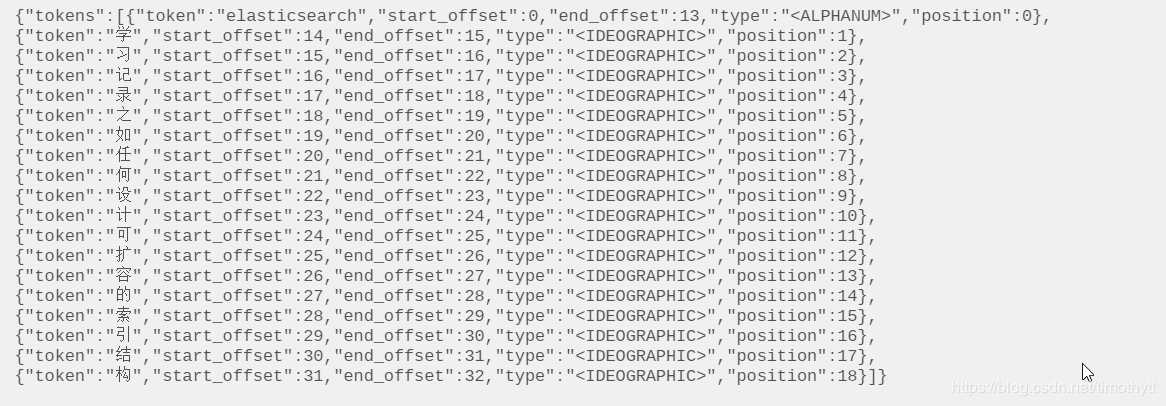
我们会发现,中文竟然被默认分词器分词单个字了!尴尬啊!!!
这就不难理解为啥term搜“学习”搜不到,搜全文也搜不到,因为存的是“学”和“习”。
【总结】如果使用term查询,要确保字段是no analyzed的。建索引的时候要注意。
————————————————
版权声明:本文为CSDN博主「7im0thyZhang」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/timothytt/article/details/86775114
{
"note":"东北大学在秦皇岛设立的分校。 东北大学秦皇岛分校是经教育部正式批准成立.",
"value":"岛设fff"
}
{
"note":"东北大学秦皇岛分校是经教育部正式批准成立,在东北大学统一规划下",
"value":"岛设"
}
对应的mapping
{
"ik-test": {
"mappings": {
"weibo": {
"properties": {
"note": {
"type": "string",
"analyzer": "ik"
},
"value": {
"type": "string",
"index": "not_analyzed",
"analyzer": "ik"
}
}
}
}
}
}
value不进行分析
{
"query":{
"match":{"note":"岛设"}
},
"highlight":{
"pre_tags":["<tag1>","<tag2>"],
"post_tags":["</tag1>","</tag2>"],
"fields":{
"note":{}
}
}
}
能匹配以上两个文档
{
"highlight": {
"note": [
"东北大学在秦皇<tag1>岛</tag1>设立的分校。 东北大学秦皇<tag1>岛</tag1>分校是经教育部正式批准成立."
]
}
}
和
{
"highlight": {
"note": [
"东北大学秦皇<tag1>岛</tag1>分校是经教育部正式批准成立,在东北大学统一规划下."
]
}
}
{
"query":{
"match_phrase":{"note":"岛设"}
},
"highlight":{
"pre_tags":["<tag1>","<tag2>"],
"post_tags":["</tag1>","</tag2>"],
"fields":{
"note":{}
}
}
}
则没有匹配任何内容
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
{
"query":{
"term":{"note":"岛设"}
},
"highlight":{
"pre_tags":["<tag1>","<tag2>"],
"post_tags":["</tag1>","</tag2>"],
"fields":{
"note":{}
}
}
}
则没有匹配任何内容,因为“岛设”没有作为一个词被分词
但是“东北大学”是有作为词被分词的,可以匹配到
{
"query":{
"term":{"note":"东北大学"}
},
"highlight":{
"pre_tags":["<tag1>","<tag2>"],
"post_tags":["</tag1>","</tag2>"],
"fields":{
"note":{}
}
}
}
{
"highlight": {
"note": [
"<tag1>东北大学</tag1>在秦皇岛设立的分校。 <tag1>东北大学</tag1>秦皇岛分校是经教育部正式批准成立."
]
}
}
和
{
"highlight": {
"note": [
"<tag1>东北大学</tag1>秦皇岛分校是经教育部正式批准成立,在<tag1>东北大学</tag1>统一规划下."
]
}
}
对于value没有进行分析器分析的,是完整的内容
{
"query":{
"match":{"value":"岛设"}
},
"highlight":{
"pre_tags":["<tag1>","<tag2>"],
"post_tags":["</tag1>","</tag2>"],
"fields":{
"value":{}
}
}
}
匹配不到任何内容,但是使用term可以匹配一条
{
"query":{
"term":{"value":"岛设"}
},
"highlight":{
"pre_tags":["<tag1>","<tag2>"],
"post_tags":["</tag1>","</tag2>"],
"fields":{
"value":{}
}
}
}
匹配结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.6931472,
"hits": [
{
"_index": "ik-test",
"_type": "weibo",
"_id": "12",
"_score": 1.6931472,
"_source": {
"note": "东北大学秦皇岛分校是经教育部正式批准成立,在东北大学统一规划下",
"value": "岛设"
}
}
]
}
}
标签:git info elastic shu match mamicode sea its operator
原文地址:https://www.cnblogs.com/kelelipeng/p/12357385.html