标签:hash char span master park 应该 gate 示例 make
这里所有算子均只适用于pairRDD。pairRDD的数据类型是(k,v)形式的键值对;
PartitionBy(Partitioner)
对pairRDD进行分区操作,如果原有的partioner和现有的partioer是一致的话就不进行分区, 否则会生成ShuffleRDD,即会产生shuffle过程。注意:这里的RDD是tuple;
def main(args: Array[String]): Unit = {
val sc: SparkContext = new SparkContext(new SparkConf() .setMaster("local[*]").setAppName("spark")) val raw: RDD[(Int,String)] = sc.parallelize(Array((1,"a"), (2,"b"), (3,"c"), (4,"d")),2) println(raw.partitioner) raw.saveAsTextFile("E:/idea/spark2/out/partition_before") val partitioned: RDD[(Int,String)] = raw.partitionBy(new HashPartitioner(2)) partitioned.saveAsTextFile("E:/idea/spark2/out/partition_after") println(partitioned.partitioner.get) }
前后的分区器分别是:None,org.apache.spark.HashPartitioner@2
分区前后文件中的内容分别为:
前:(1,a 2,b),(3,c 4,d)
后:(1,a 3,c),(2,b 4,d)
拓展:单值数据类型的RDD不可以调用PartitinBy,它的RDD不提供这种算子;
多值数据(一个tuple内包含多个元素)类型的RDD也不可以调用PartitionBy,它的RDD不提供这种算子。
groupByKey
groupByKey把key相同的数据元素,聚合成一个新的kv对,key是以前的key,value是以前相同key的所有value的一个集合。
def main(args: Array[String]): Unit = { val sc: SparkContext = new SparkContext(new SparkConf() .setMaster("local[*]").setAppName("spark")) val raw: RDD[String] = sc.parallelize(Array("one", "two", "one", "one", "three", "two"),2) val kv: RDD[(String, Int)] = raw.map(x => (x, 1)) kv.saveAsTextFile("E:/idea/spark2/out/group_before") val groups: RDD[(String, Iterable[Int])] = kv.groupByKey() groups.saveAsTextFile("E:/idea/spark2/out/group_after") }
调用groupByKey之后,文件中的内容如下:
(two,CompactBuffer(1, 1))
(one,CompactBuffer(1, 1, 1))
(three,CompactBuffer(1))
reduceByKey(func, [numTasks])
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的func函数,将相同key的值聚合到一起,聚合的方式由func决定,例如可以相加、相乘reduce任务的个数可以通过第二个可选的参数来设置。
示例代码演示了:计算相同key的value之和;
def main(args: Array[String]): Unit = { val sc: SparkContext = new SparkContext(new SparkConf() .setMaster("local[*]").setAppName("spark")) val raw: RDD[String] = sc.parallelize(Array("one", "two", "one", "one", "three", "two"),2) val kv: RDD[(String, Int)] = raw.map(x => (x, 1)) val sum: RDD[(String, Int)] = kv.reduceByKey(_ + _) sum.saveAsTextFile("E:/idea/spark2/out/reducebykey") }
文件中的内容如下:
(two,2)
(one,3)
(three,1)
1.reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合,在每个分区内部先进行聚合)操作,,这样极大地减少了数据量,返回结果是RDD[k,v].
2. groupByKey:按照key进行分组,直接进行shuffle。
3. 开发指导:reduceByKey比groupByKey效率更高,建议使用。但是需要注意是否会影响业务逻辑。
aggregateByKey
参数:(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U)
1. 作用:在kv对的RDD中,按key将value进行分组合并,合并时,将每个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。
(1)zeroValue:给每一个分区中的每一个key一个初始值;
(2)seqOp:函数用于在每一个分区中用初始值逐步迭代value;
(3)combOp:函数用于合并每个分区中的结果。
aggregateByKey部分原码如下
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)] = self.withScope { aggregateByKey(zeroValue, defaultPartitioner(self))(seqOp, combOp) } //seqOp和combOp都仅对相同key的v来进行操作,不对key操作。
示例代码创建了一个pairRDD,取出每个分区相同key对应值的最大值,然后相加并输出。
val sc: SparkContext = new SparkContext(new SparkConf()
.setMaster("local[*]").setAppName("spark"))
val raw: RDD[(String, Int)] = sc.parallelize(Array(("a", 3), ("a", 2),
("c", 4), ("b", 3), ("c", 6), ("c", 8)),2)
//注意:由于这里所有所有的value均大于0而且求最大值,所以可以设为0;
//初值的确定要保证不影响seqOp函数的计算
val processed: RDD[(String, Int)] = raw.aggregateByKey(0)(Math.max(_, _), _ + _)
processed.saveAsTextFile("")
分区前两个分区中的内容分别如下:
(a,3)
(a,2)
(c,4)
----
(b,3)
(c,6)
(c,8)
调用aggregateby函数后,结果分别如下:
(a,3)
(c,12)
(b,3)
运行结果印证了函数的运算逻辑;
foldByKey案例
aggregateByKey的简化操作,seqop和combop相同,查看其原码:
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)] = self.withScope { oldByKey(zeroValue, defaultPartitioner(self))(func) } def foldByKey( ... combineByKeyWithClassTag[V]((v: V) => cleanedFunc(createZero(), v),cleanedFunc, cleanedFunc, partitioner) ) //在对比aggreageByKey对应位置的的源代码 combineByKeyWithClassTag[U]((v: V) => cleanedSeqOp(createZero(), v),cleanedSeqOp, combOp, partitioner)
//发现对应位置的combOp函数被cleanedFunc替代
combineByKey
参数:(createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C)
作用:对相同K,把V合并成一个集合。
参数描述:
(1)createCombiner: combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果这是一个新的元素,combineByKey()会使用一个叫作createCombiner()的函数来来创建那个键对应的累加器的初始值。
(2)mergeValue: 如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并
(3)mergeCombiners: 由于每个分区都是独立处理的, 因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器, 就需要使用用户提供的 mergeCombiners() 方法将各个分区的结果进行合并
示例代码演示了:创建一个pairRDD,根据key计算每种key的均值。(先计算每个key出现的次数以及可以对应值的总和,再相除得到结果)
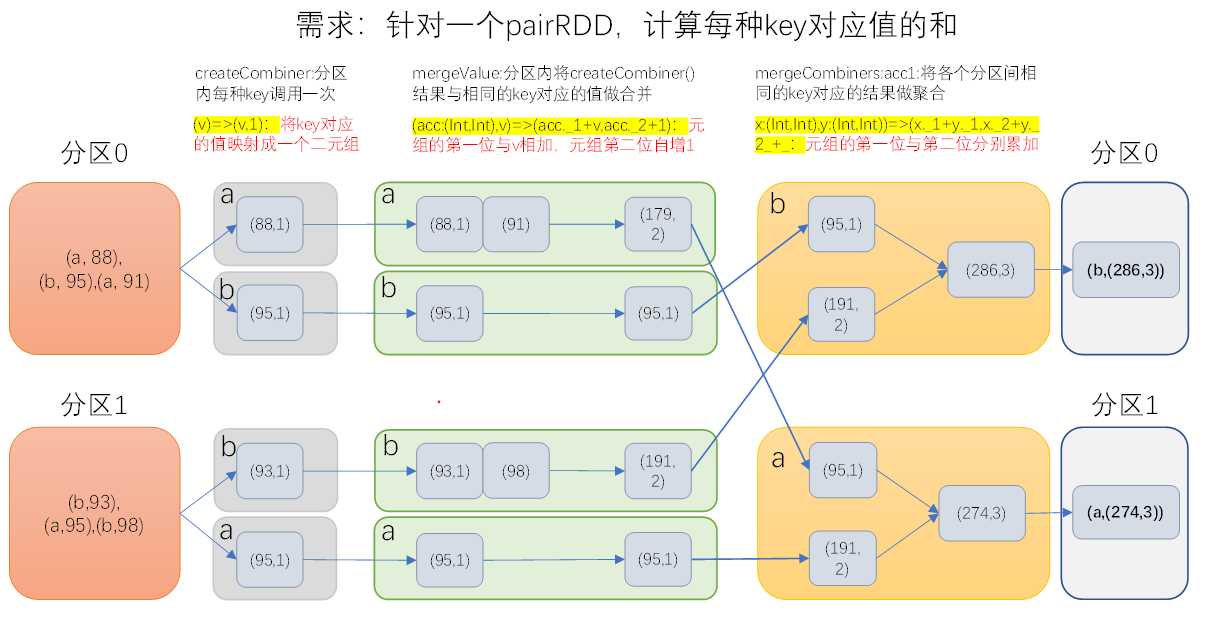
代码如下:
val sc: SparkContext = new SparkContext(new SparkConf() .setMaster("local[*]").setAppName("spark")) val raw: RDD[(String, Int)] = sc.parallelize(Array(("a", 3), ("a", 2), ("c", 4), ("b", 3), ("c", 6), ("c", 8)),2) val processed3: RDD[(String, (Int, Int))] = raw.combineByKey((_, 1), (x: (Int, Int), v: Int) => (x._1 + v, x._2 + 1), (x: (Int, Int), y: (Int, Int)) => (x._1 + y._1, x._2 + y._2)) val processed4: RDD[(String, Double)] = processed3.map { case (key, value) => (key, value._1 / value._2.toDouble) } processed4.saveAsTextFile("E:/idea/spark2/out/combinebykey") }
运行结果如下:
(b,3.0)
(a,2.5)(c,6.0)
运行结果印证了函数的运算逻辑;
sortByKey([ascending], [numTasks])
作用:在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
mapValues
针对于(K,V)形式的类型只对V进行操作,示例代码如下:
def main(args: Array[String]): Unit = { val sc: SparkContext = new SparkContext(new SparkConf(). setMaster("local[*]").setAppName("spark")) val raw: RDD[(Int, String)] = sc.makeRDD(Array((1, "spark"), (2, "scala")), 2) val value: RDD[(Int, String)] = raw.mapValues(x => x + "extra") value.saveAsTextFile("E:/idea/spark2/out/mapvalue") }
运行结果如下:
(1,sparkextra)
(2,scalaextra)
join(otherDataset, [numTasks])
作用:在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素组合在一起的(K,(V,W))的RDD
示例代码如下:
def main(args: Array[String]): Unit = { val sc: SparkContext = new SparkContext(new SparkConf(). setMaster("local[*]").setAppName("spark")) val raw1: RDD[(Int, String)] = sc.makeRDD(Array((1, "one"), (2, "two"), (1, "secondone")),3) val raw2: RDD[(Int, String)] = sc.makeRDD(Array((2, "mytwo"), (1, "myone")),2) raw1.join(raw2).saveAsTextFile("E:/idea/spark2/out/join") }
打印结果如下:
(1,(one,myone))
(1,(secondone,myone))
(2,(two,mytwo))
并且分布于三个不同的分区;
从中我们可得出如下结论:
1)最终的分区数应该由两个分区中最大的分区数来决定;
2)在调用者的RDD中,相同的k出现了不止一次,那么,在结果RDD中,k将分别与这个重复的k进行组合;
因此,无论是分区数还是join的结果,都与调用的顺序(A调用join连接B,或者B调用join连接A)无关。
cogroup(otherDataset, [numTasks])
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD
def main(args: Array[String]): Unit = { val sc: SparkContext = new SparkContext(new SparkConf(). setMaster("local[*]").setAppName("spark"))
val raw1: RDD[(Int, String)] = sc.makeRDD(Array((1, "one"), (2, "two"), (1, "secondone")),3) val raw2: RDD[(Int, Char)] = sc.makeRDD(Array((2, ‘2‘), (1, ‘1‘)),2) val value: RDD[(Int, (Iterable[String], Iterable[Char]))] = raw1.cogroup(raw2) val tuples: Array[(Int, (Iterable[String], Iterable[Char]))] = value.collect() for(i <- 0 until tuples.length){ println(tuples(i)._1) tuples(i)._2._1.foreach(print) println() tuples(i)._2._2.foreach(print) println() println("=======") } }
运行结果如下:
1
onesecondone
1
=======
2
two
2
=======
标签:hash char span master park 应该 gate 示例 make
原文地址:https://www.cnblogs.com/chxyshaodiao/p/12357977.html