标签:manager code info cat mapred str shell containe 完成
spark为什么比mapreduce快
mapreduce的数据处理过程是:把数据从磁盘读到内存,在内存中完成计算,再写回磁盘。下一个mr程序要继续对这批数据进行处理,又要重复这一过程。有多少个mr程序,就有多少次读磁盘和写磁盘的过程,效率低下。
spark的数据处理过程是:把数据读到内存之后,在多个RDD之间形成转换流,而RDD借助于exector的缓存,是可以在内存中完成计算。因此只需要一次读和一次写磁盘的过程。
spark计算模型与Hadoop计算模型的比较
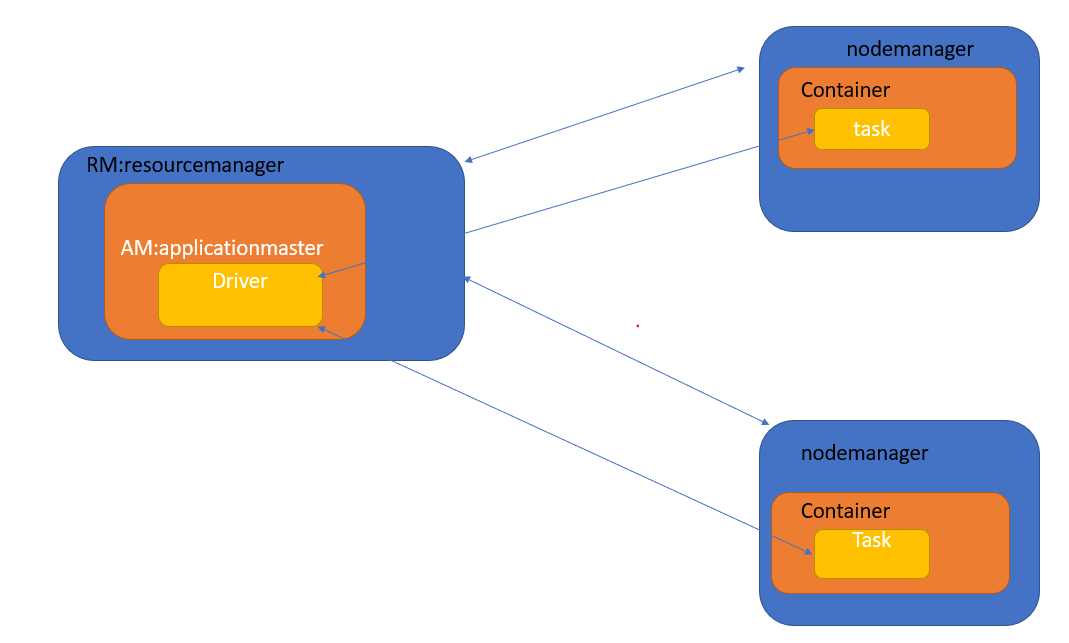
rm,nm:资源层面
driver,tasks:计算层面
am,container:利于实现可插拔,将上层的计算与下层的资源管理实现解耦,task在容器中运行,am被赋予一个id。
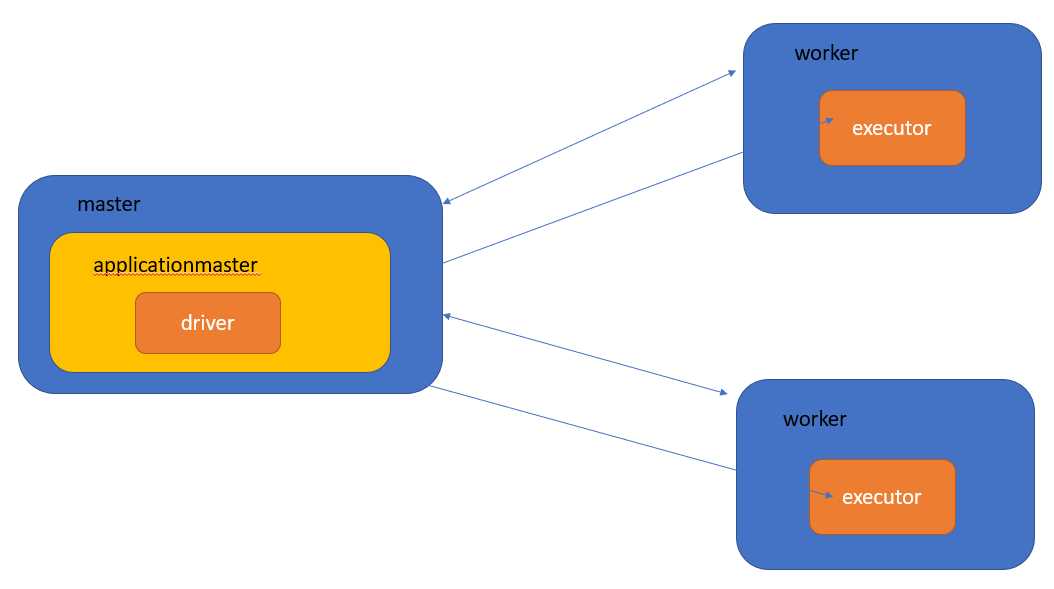
同样地:
master,workers:资源层面,只有在spark原生的调度器才有这两个概念,它们分别对应yarn中的的rm,nm
driver,execurot:计算层面
如果把spark的计算框架部署到yarn(常用),则模型如下:
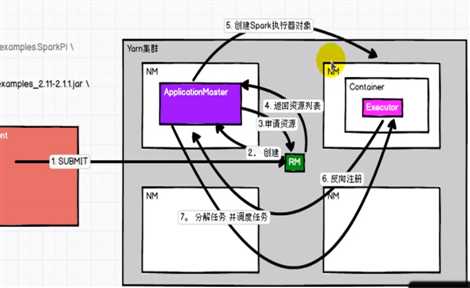
1.driver向rm提交作业。
2.rm创建一个applicationmaster
3.am向rm申请资源
4.rm返回可用的资源列表
5.am据此创建executor对象
6.executor向am进行反向注册,告知哪些executor注册成功,可以执行任务,为rm后续的am调度任务提供依据
7.am分解任务,并调度任务。
8.executor执行任务并返回结果
9.driver执行结束,am撤销。
这一执行过程,充分体现了applicationmaster在资源与计算之间的解耦作用。
driver与executor
Spark的驱动器是执行开发程序中的main方法的进程。它负责开发人员编写的用来创建SparkContext、创建RDD,以及进行RDD的行动操作代码的执行。如果你是用spark shell,那么当你启动Spark shell的时候,系统后台自启了一个Spark驱动器程序,就是在Spark shell中预加载的一个叫作 sc的SparkContext对象。如果驱动器程序终止,那么Spark应用也就结束了。
主要负责:
1)把用户程序转为作业(JOB)
2)跟踪Executor的运行状况
3)为执行器节点调度任务
4)UI展示应用运行状况
executor(执行器)
Spark Executor是一个工作进程,负责在 Spark 作业中运行任务,任务间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。主要负责:
1)负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程;
2)通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
标签:manager code info cat mapred str shell containe 完成
原文地址:https://www.cnblogs.com/chxyshaodiao/p/12360985.html