标签:代码 进入 建议 实践 数据 同步 两种 范式 数据处理
有数据逻辑,结构化思维,商业认知能力,这是成为一个优秀数据分析师的必备技能。简单来说,就是对运营,数据,工具这三种能力的综合运用。
数据库三范式
一般来说的数据库三范式都是指的关系型数据库,范式指的就是规范的意思,三范式指的就是利用关系型数据库进行建表时候普遍需要遵循的三个规范(即1NF,2NF,3NF);
1NF:建表时要保证列的原子性(即不可分割性);
2NF:第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或记录必须可以被唯一地区分。
3NF:第三范式(3NF)是第二范式(2NF)的一个子集,即满足第三范式(3NF)必须满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个关系中不包含已在其它关系已包含的非主关键字信息。
增量表和全量表优缺点
1. 全量表:每天的所有的最新状态的数据, 2. 增量表:每天的新增数据,增量数据是上次导出之后的新数据。 3. 拉链表:维护历史状态,以及最新状态数据的一种表,拉链表根据拉链粒度的不同,实际上相当于快照,只不过做了优化,去除了一部分不变的记录而已,通过拉链表可以很方便的还原出拉链时点的客户记录。 4. 流水表: 对于表的每一个修改都会记录,可以用于反映实际记录的变更。 拉链表通常是对账户信息的历史变动进行处理保留的结果,流水表是每天的交易形成的历史; 流水表用于统计业务相关情况,拉链表用于统计账户及客户的情况 数据仓库之拉链表(原理、设计以及在Hive中的实现)
内部表和外部表区别
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
区别:
内部表数据由Hive自身管理,外部表数据由HDFS管理;
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里);
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
数据倾斜了怎么办
1:什么是数据倾斜?
前面提到分布式计算,是一个集群共同承担计算任务,理想状态下,每个计算节点应该承担相近数据量的计算任务,然而实际情况通常不会这么理想,数据分配严重不均就会产生数据倾斜。我们先来给数据倾斜下个明确点的定义。
数据倾斜,指的是并行处理的过程中,某些分区或节点处理的数据,显著高于其他分区或节点,导致这部分的数据处理任务比其他任务要大很多,从而成为这个阶段执行最慢的部分,进而成为整个作业执行的瓶颈,甚至直接导致作业失败。
举个实际发生的例子说明下,一个spark作业,其中有个stage是由200个partition组成,在实际执行中,有198个partition在10秒内就完成了,但是有两个partition执行了3分钟都没有完成,并且在执行5分钟后失败了。这便是典型的数据倾斜场景,通过观察SparkUI发现这两个partition要处理的数据是其他partition的30多倍,属于比较严重的数据倾斜。
2:数据倾斜的危害
知道了什么是数据倾斜,那么它到底有什么危害,让大家这么痛恨它的同时,又很畏惧它呢。
数据倾斜主要有三点危害:
危害一:任务长时间挂起,资源利用率下降
计算作业通常是分阶段进行的,阶段与阶段之间通常存在数据上的依赖关系,也就是说后一阶段需要等前一阶段执行完才能开始。
举个例子,Stage1在Stage0之后执行,假如Stage1依赖Stage0产生的数据结果,那么Stage1必须等待Stage0执行完成后才能开始,如果这时Stage0因为数据倾斜问题,导致任务执行时长过长,或者直接挂起,那么Stage1将一直处于等待状态,整个作业也就一直挂起。这个时候,资源被这个作业占据,但是却只有极少数task在执行,造成计算资源的严重浪费,利用率下降。
危害二:由引发内存溢出,导致任务失败
数据发生倾斜时,可能导致大量数据集中在少数几个节点上,在计算执行中由于要处理的数据超出了单个节点的能力范围,最终导致内存被撑爆,报OOM异常,直接导致任务失败。
危害三:作业执行时间超出预期,导致后续依赖数据结果的作业出错
有时候作业与作业之间,并没有构建强依赖关系,而是通过执行时间的前后时间差来调度,当前置作业未在预期时间范围内完成执行,那么当后续作业启动时便无法读取到其所需要的最新数据,从而导致连续出错。
可以看出,数据倾斜问题,就像是一个隐藏的杀手,潜伏在数据处理与分析的过程中,只要一出手,非死即伤。那么它又是如何产生的呢?想要解决它,我们就要先了解它。
3:为什么会产生数据倾斜?
3.1:读入数据的时候就是倾斜的
读入数据是计算任务的开始,但是往往这个阶段就可能已经开始出现问题了。
对于一些本身就可能倾斜的数据源,在读入阶段就可能出现个别partition执行时长过长或直接失败,如读取id分布跨度较大的mysql数据、partition分配不均的kafka数据或不可分割的压缩文件。
这些场景下,数据在读取阶段或者读取后的第一个计算阶段,就会容易执行过慢或报错。
3.2:shuffle产生倾斜
在shuffle阶段造成倾斜,在实际的工作中更加常见,比如特定key值数量过多,导致join发生时,大量数据涌向一个节点,导致数据严重倾斜,个别节点的读写压力是其他节点的好几倍,容易引发OOM错误。
3.3:过滤导致倾斜
有些场景下,数据原本是均衡的,但是由于进行了一系列的数据剔除操作,可能在过滤掉大量数据后,造成数据的倾斜。
例如,大部分节点都被过滤掉了很多数据,只剩下少量数据,但是个别节点的数据被过滤掉的很少,保留着大部分的数据。这种情况下,一般不会OOM,但是倾斜的数据可能会随着计算逐渐累积,最终引发问题。
4:怎么预防或解决数据倾斜问题?
4.1.尽量保证数据源是均衡的
程序读入的数据源通常是上个阶段其他作业产生的,那么我们在上个阶段作业生成数据时,就要注意这个问题,尽量不要给下游作业埋坑。
如果所有作业都注意到并谨慎处理了这个问题,那么出现读入时倾斜的可能性会大大降低。
这个有个小建议,在程序输出写文件时,尽量不要用coalesce,而是用repartition,这样写出的数据,各文件大小往往是均衡的。
4.2.对大数据集做过滤,结束后做repartition
对比较大的数据集做完过滤后,如果过滤掉了绝大部分数据,在进行下一步操作前,最好可以做一次repartition,让数据重回均匀分布的状态,否则失衡的数据集,在进行后续计算时,可能会逐渐累积倾斜的状态,容易产生错误。
4.3.对小表进行广播
如果两个数据量差异较大的表做join时,发生数据倾斜的常见解决方法,是将小表广播到每个节点去,这样就可以实现map端join,从而省掉shuffle,避免了大量数据在个别节点上的汇聚,执行效率也大大提升。
4.4.编码时要注意,不要人为造成倾斜
在写代码时,也要多加注意不要使用容易出问题的算子,如上文提到的coalesce。
另外,也要注意不要人为造成倾斜,如作者一次在帮别人排查倾斜问题时发现,他在代码中使用开窗函数,其中写到over (partition by 1),这样就把所有数据分配到一个分区内,人为造成了倾斜。
4.5.join前优化
个别场景下,两个表join,某些特殊key值可能很多,很容易产生数据倾斜,这时可以根据实际计算进行join前优化。
如计算是先join后根据key聚合,那可以改为先根据key聚合然后再join。又如,需求是join后做distinct操作,在不影响结果的前提下,可以改为先distinct,然后再join。这些措施都是可以有效避免重复key过多导致join时倾斜。
4.6.具体问题具体分析
某些具体问题或者解决方案,不具备普遍性,但是也可以作为一种思路参考。
例如,读入mysql数据时倾斜,这通常是由于mysql的id分布严重不均,中间存在跨度很大的区间造成的。解决方法有两种,一是加大读取时的分区数,将倾斜的区间划分开;另一种是,先把id取出来进行等宽切割,确保每个区段的id数量一致,之后再对各区间进行数据读取。
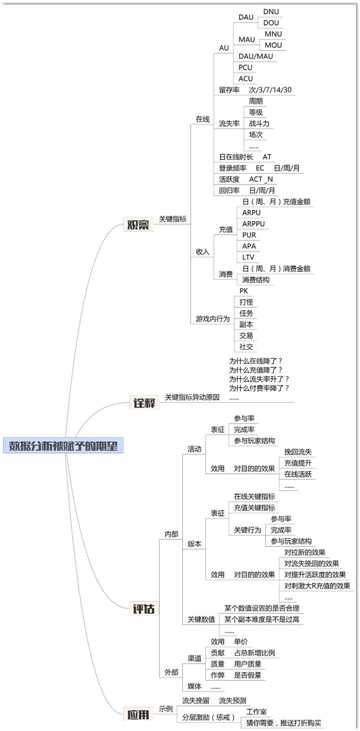
游戏数据分析的流程
(1) 方法论
这个阶段决定如何进行数据埋点,如何设计分析指标,如何采集,组织数据
有两点需要重点关注:业务需求(埋点,如何进行埋点及数据分析可见《移动游戏运营数据指标白皮书》)及指标体系(AARRR模型,BI系统)
(2) 数据加工
主要解决:
业务理解(充分理解需求和标准定义)
技术开发(程序方,在客户端植入统计分析SDK,或在服务端完成数据的采集)
(3) 统计分析
是BI的一个方面,还包括决策支持系统(DSS),查询和报告,在线分析处理(OLAP),预测和数据挖掘。
(4) 提炼演绎
游戏数据分析模块:流量分析,留存分析,充值分析,等级分析,关卡分析,消费分析,设备分析,转化分析
游戏数据采集标准接口设计:用户账户(定义账户类型,姓名,级别,性别,年龄,区服),充值信息(充值请求,成功或失败),消费购买(如道具,VIP等),关卡任务(任务,关卡或副本情况),成长体系,个性分析
(5) 建议方案
利用分析结果在于获取用户和经营用户两个方面
比如一款游戏,如果一个活跃用户连续3天不进入游戏,则从游戏中流失的概率就增加10%,此时我们就需要精准定义这一人群,进行目标用户的营销和召回计划。
采用什么样的召回方式可采用AB测
二 游戏数据分析师的定位
分为玩家,分析师,策划
书目推荐:《数据分析:企业的贤内助》
(1)玩家-游戏用户:
基本的体验要素有:注册模块,加载模块,输入法调用,网络连通性,文字情感,弹窗能力,推送能力,按钮UI设计,触摸设计,流畅性设计,这些可以基于数据追踪来完成数据采集和分析。产品体验分析的目的不是获取新用户,而是影响已经进行游戏的用户,吸引二次打开或登陆游戏。
(2)分析师:
客观运用数据进行理论分析,提供决策和解决方案。分析师能力分为:
A专业的数据解读,需要关注的顶层目标和分析需求:
成功的游戏由游戏人气,游戏收益组成。如用户规模(活跃用户,新增用户,流失用户,用户行为分析,用户规模分析),收益能力(付费用户分析,付费转化效果,收入能力分析,ARPU分析,付费潜力挖掘),营销效果(渠道(留存用户分析,玩家价值分析),投放(转化率分析))
B 数据分析探索
可以分为两方面:一是可以探索源自对数据本身特征和分布的探索,此点更多的是数据本身层面的和摸索。二是基于一定的业务场景,进行一些具有前瞻性的数据分析。比如对于公会核心成员与普通成员游戏时间的分析,了解社交关系是否会影响游戏流失及活跃度。
C 理论知识的学习
漏斗模型。比如一个支付操作只需4步就能完成,但在设计时需要5步,多了一步支付流程,就多了一步用户的转化流失。
主要探索2点:
A 问题分析的思路及方法
B 跨领域知识的运用实践:比如贝叶斯理论在产品生命周期的管理,用户生命周期的管理,游戏用户CRM系统的建立等。
(3)策划-游戏设计者
数据策划需要:
理解游戏的核心玩法
游戏体验设计原则
游戏类型设计原则
游戏消费设计原则
游戏等级关卡设计
制定业务指标体系
设计问题解决方案
数据进行版本规划
竞品游戏学习调研
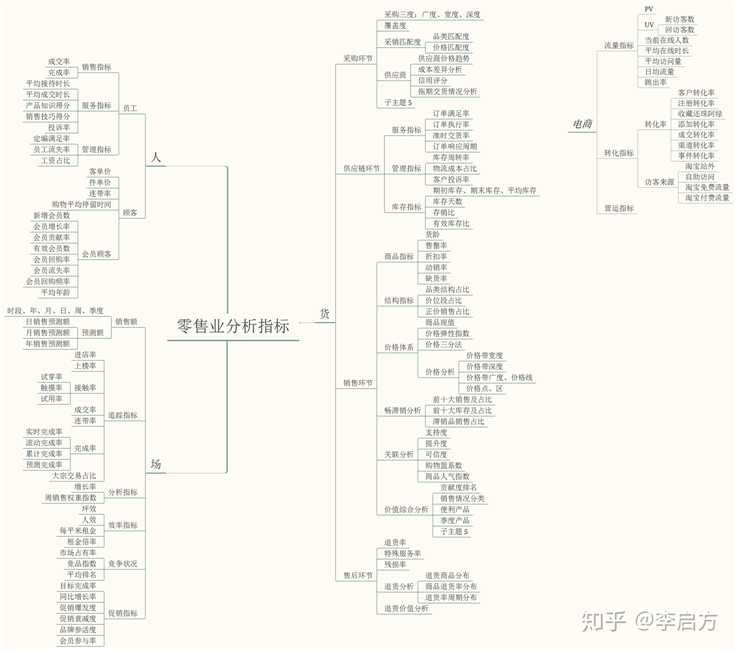
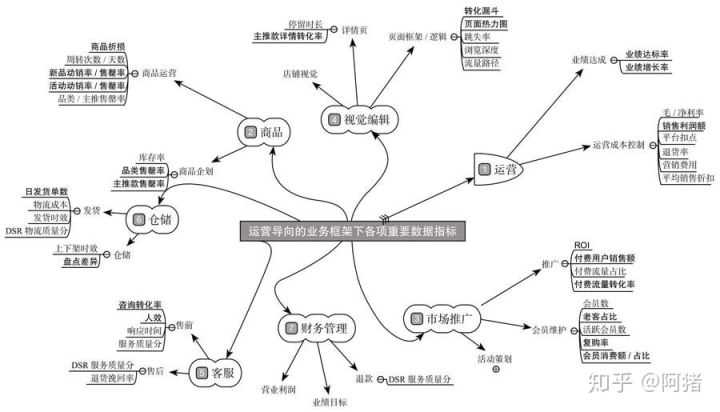
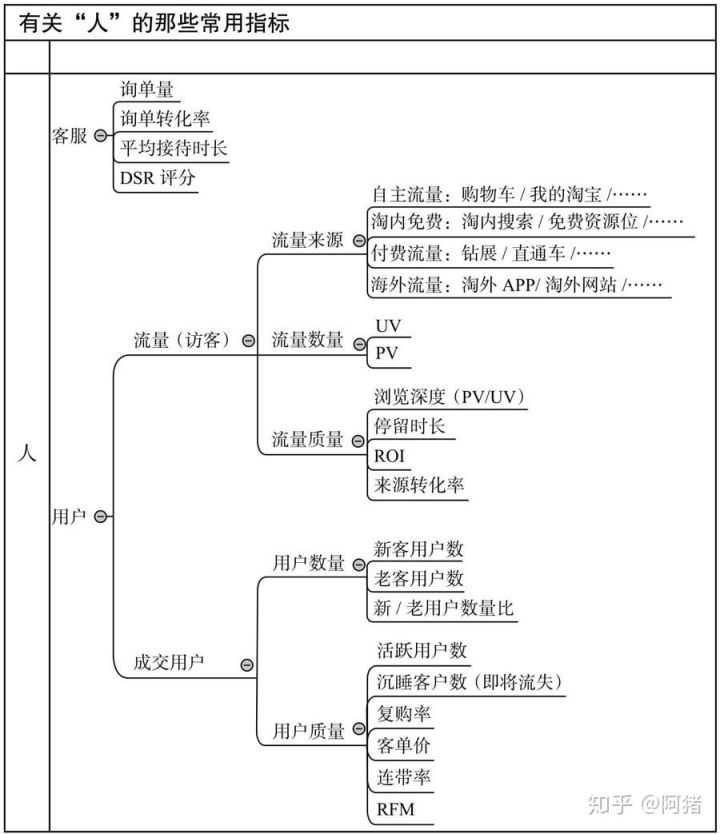
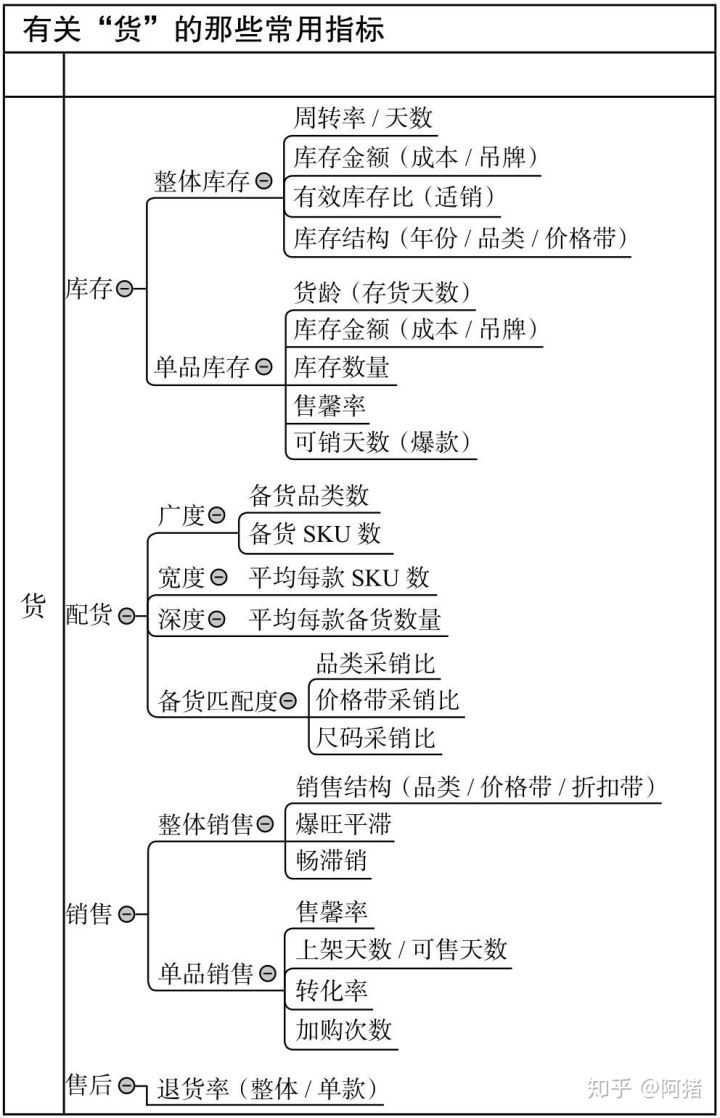
电商数据分析
先说电商,也就是电商运营,不管是淘宝、拼多多、京东,还是其他电商平台,底层的运营逻辑都是相同的。无非就是市场及竞争分析、店铺运营规划、爆品打造、社群淘客、seo搜索优化与竞价付费推广等
数据分析,则是融入在具体的业务中,主要是提升这些指标——点击率、点击量、收藏加购率、页面访问深度、转化率、销售额等。
电商运营主要包括8个模块:单品分析、店铺运营规划、竞争分析、市场分析、客户分析、活动策划、直通车、淘宝客,熟悉各项核心指标
标签:代码 进入 建议 实践 数据 同步 两种 范式 数据处理
原文地址:https://www.cnblogs.com/daoren/p/12360768.html