标签:code 目标 target 算法 应用 照片 src option 比较
深度学习算法对训练数据的胃口很大,当你收集到足够多的带标签数据构成训练集时,算法效果最好。
这导致很多团队用尽一切方法收集数据,然后把它们堆到训练集里,让训练的数据量更大。但是有些数据,甚至是大部分数据,都来自和开发集和测试集不同的分布。
所以深度学习时代,越来越多的团队都用和dev set、test set分布不同的数据来训练。
这里有一些微妙的地方,一些最佳做法来处理训练集training set和测试集test set存在差异的情况。
以一个实际例子为例进行分析:我们想要设计一个能分辨用户上传的图片是不是猫的神经网络。现有的用户上传的猫的图片有10000个,样本太少,网络上猫的照片很多,有200000 所以需要利用网络上的猫图进行训练。但是有一个问题,网络上的猫图很清晰,而用户上传的猫图比较模糊。如果我们将网络上的图片当训练集的话,会使训练、测试集有不同的分布,但优点是样本多;如果我们将用户上传的图片当训练集的话,会使训练、测试集有相同的分布,但缺点是样本太少了。目前主要有以下两种解决方法:
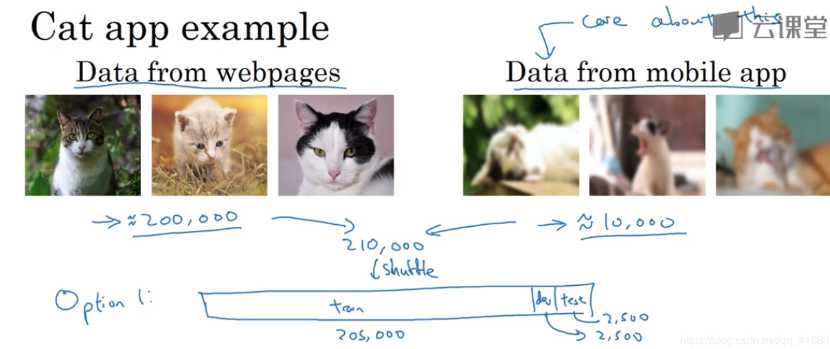
面对不同分布的图片,一个做法是把他们放到一起打乱,然后随机分配的训练集、开发集和测试集。
这样做的优点是:这样三者就来自同一分布,这样更好管理。
这样做的缺点是(缺点还不小):如果你观察开发集,看这2500个样本,它们其中很多图片都来自网页下载,而不是我们真正关心的数据分布。要记住:设立开发集的目的你告诉你的团队where to aim the target. 而你瞄准目标的方式,你的大部分精力都在优化网页下载的图片,而这并不是我们想要的。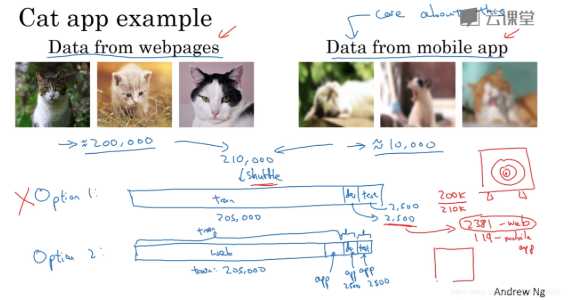
option2(推荐):
在这里,我们将200000张网页下载的图片和5000张来自应用的图片组成训练集,然后各用2500张来自应用的图片组成开发集、测试集。
这样划分训练集、开发集和测试集的好处在于:现在你瞄准的目标就是你想要处理的目标。你告诉你的团队,我的开发集包含的数据全部来自手机上传,而这是我真正关心的图片分布。
这样划分训练集、开发集和测试集的坏处在于:现在你的训练集分布,和开发集和测试集的分布并不一样。
但事实证明,这样把数据分成训练集、开发集和测试集,在长期能给你带来更好的系统性能。
再看另一个例子:
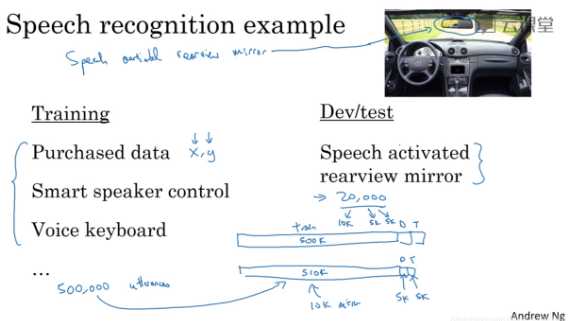
划分数据的方式还是和上面的option2一样。
在开发集和测试集中数据全部来自我们想要优化的目标数据,在训练集中数据选用其他(大量)数据和目标数据的组合。
标签:code 目标 target 算法 应用 照片 src option 比较
原文地址:https://www.cnblogs.com/lau1997/p/12361358.html