标签:cat 调整 ini 删除 最小 集合 相对 error 通过
1. Bias-Variance Decomposition

irreducible error无法被减小,而reducible error可以通过对model的调整将其最小化
2. 一般情况下而言,model越复杂,bias越小,而variance越高,故而我们要找到一个平衡使MSE最小
3. categorical variables
indicator变量指那些取值为0或1的变量,如将服用药剂以及不服用药剂的病人分成两种情况讨论
4. 三种方法对简化model的复杂性
a) subset-selection,大集合分散成小集合,每个小集合都有自己的model
找到最主要的features,去掉冗余的部分,这个步骤叫做stepwise regression(三个贪心算法可以实现):
aa. 从没有variable开始,一步步加入影响最大的variable
ab. 从全部variables都在开始,一点点去掉影响最小的
ac. 一点点尝试每一个variable保留或者删除
b) shrinkage,将不重要的系数设置为0,只关注重要的
c) dimensionality-reduction,将点投影到较低纬度空间中
5. classification分为两类
a) generative learning algorithm:按照类别分析model
b) discriminative algorithm:focus on decision boundary

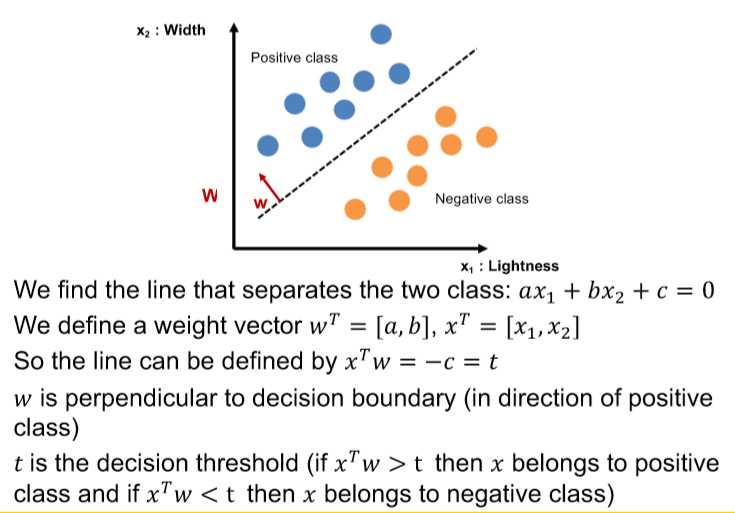
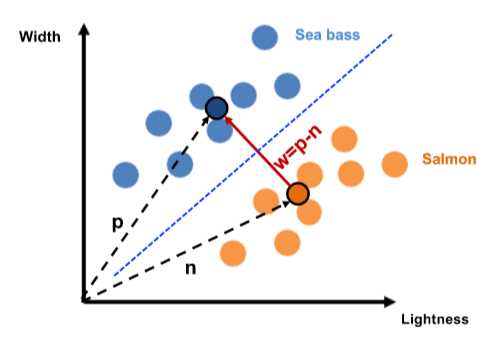

6. 算法需要在学习前将全部的training data准备好:batch learning或offline learning
如果在新的data加入后还能继续学习教online learning
7. 如果model有固定数量的parameters,则为parametric;若parameters的数量随着training data的数量增加,则为non-parametric,更加灵活
8. deduction:推论,从整体情况预测某一现象;
consequences:归纳,从特定情况推断整体
9. cross-validation
用validation set得到一些特定parameter
a) holdout method: 直接从中间分开,记住train test之间是独立的
b) leave-one-out cross validation(LOOCV): 每个iteration中选择一个
c) K-fold cross validation: 分成K份
b c区别?
10. data types
a) numerical--categorical(not numbers)
b) irrelevant: 数字或string,与output无关
nominal:不同类别之间没有数值关系的离散值(如动物类型)
binary:只有两个可能性
ordinal:可以排序的离散整数,但无法定义两个数字之间的相对距离
count
time:周期性重复的连续数据形式(天,周)
interval:我们可以对两个值之间的差距进行测量的数据
11. binary classification task在binary classification中,我们希望将给定集合的数据分为两组,通常一组为positive一组negative,有时这些组同等重要,有时某一类对错误的容忍度会更高
12. evaluation metrics
前面的true或者false表示预测结果是否正确,后面的positive或者negative代表预测的结果;也称为confusion matrix
13. classification accuracy
14. 其他evaluation metrics

除了上述两种方法还有F1,对于F1而言,precision与recall被赋予了同等重要性,有些时候是不允许,故而我们需要自行判断什么最重要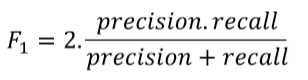
最主要的方法之一是AUC-ROC

最好的model就是AUC=1,越靠近越好;越靠近0越不好
标签:cat 调整 ini 删除 最小 集合 相对 error 通过
原文地址:https://www.cnblogs.com/eleni/p/12363267.html