标签:一个 最大的 解决 决定 图片 最大 size 机器学习 一点
单变量线性回归
单变量线性回归指的是只有一个自变量;
线性回归是一种有监督学习,解决的是自变量和因变量之间的关系;
回归指的是因变量是连续性的,而如果因变量是离散型的,则是分类问题。
监督学习算法的工作方式可以用如下这张图表示:
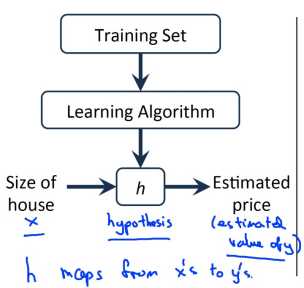
将训练集喂给机器学习算法,输出一个假设函数 h,然后新输入一个自变 x 到假设函数内,然后输出一个因变量 y 值。
以房价预测为列,特征为房子的大小,因变量是房价。那么对于一个新的房子的大小,我们如何根据历史的数据来预测出来该房子的价格呢?
?θ(x)= θ0+θ 1,因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
梯度下降
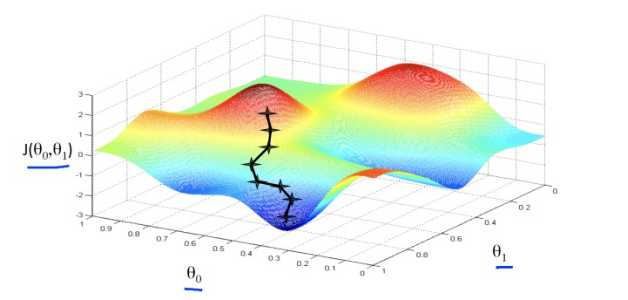
描述:对赋值,使得按梯度下降最快方向进行,一直迭代下去,最终得到局部最小值。其中是a学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方 向向下迈出的步子有多大。
a 是学习率,控制着梯度下降算法移动的大小,如果 a过小,那么梯度下降算法就一点点地移动,那么可能需要很长的时间才能够找到全局最小值;如果 a 过大,那么又有可能会导致梯度下降算法找不到最小值,甚至导致代价函数无法收敛。
梯度下降算法的步骤:
1.先预设一个初始的参数值;
2.然后一直不断地改变这个参数值,来减小代价函数;
3.直到最后代价函数达到一个最小值或者局部最优解。
标签:一个 最大的 解决 决定 图片 最大 size 机器学习 一点
原文地址:https://www.cnblogs.com/xfbestgood/p/12367529.html