标签:point 任务 enc 平滑 过滤 而不是 拼接 over 固定
一. 背景介绍
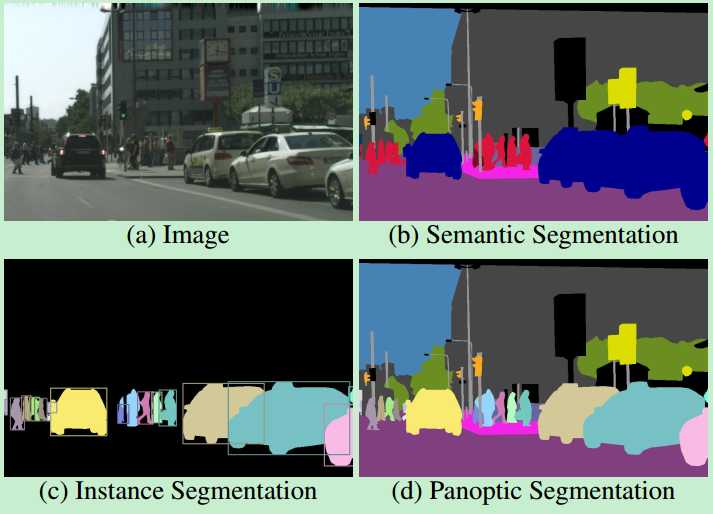
语义分割(Semantic Segmentation):对一张图片上的所有像素点进行分类,同一物体的不同实例不需要单独分割出来。
实例分割(Instance Segmentation):目标检测(比b-box更精确到边缘)和语义分割(标出同类不同个体)的结合。
全景分割(Panoramic Segmentation):语义分割和实例分割的结合,背景也要检测和分割。
图像分割是图像理解的重要基石,在自动驾驶、无人机、工业质检等应用中都有着举足轻重的地位。缺陷检测论文现在好多都是借助语义分割方法做的迁移应用到实际的工业现场等,比如国外知名的VIDI软件、国内一些检测软件。
二. 语义分割
1. 【UNet】
结构:
Unet主要针对生物医学图像分割。继承FCN的思想。整体结构就是先编码(下采样),对图像的低级局域像素值进行归类与分析,从而获得高阶语义信息; 再解码(上采样),收集这些语义信息,并将同一物体对应到相应的像素点上,回归到跟原始图像一样大小的像素点的分类。
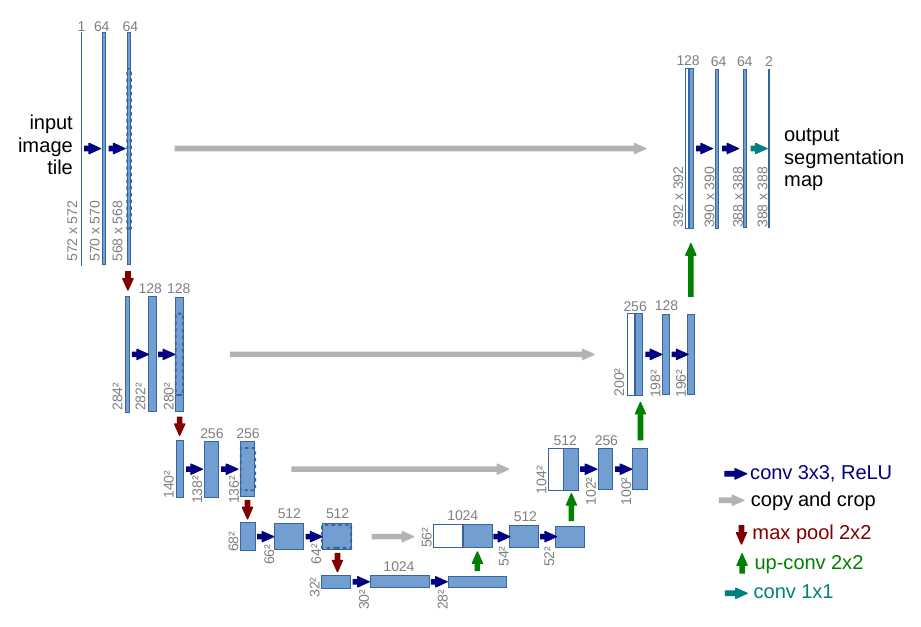
encoder的基本单元是:两个valid卷积层(图像size会减小)接一个max pooling(2x2)下采样(1/2);
decoder的基本单元是:[up-conv(2x2)+skip connection]接两个valid卷积层。
U-Net的skip connection不同于FCN的对应像素求和,是对channel的concat(拼接)过程。Unet上采样部分可以用上采样或转置卷积,这里详细解释下up-conv转置卷积。
 实际在计算机中,并不是逐像素滑动计算,效率太低。而是将卷积核转换成等效的矩阵,通过输入向量和卷积核矩阵相乘获得输出向量。如图,input:4x4,Kernel:3x3,Padding/Stride:0,output:2x2,卷积核要在输入的不同位置卷积4次,通过补零将卷积核分别置于一个4x4矩阵的四个角落,这样输入可以直接和这四个4x4的矩阵进行卷积,取代了滑窗操作。将输入展开为[16,1]向量X,输出矩阵记作Y([4,1]),四个4x4卷积核分别展开并拼接成卷积矩阵C([16,4])。普通的卷积运算可表示为矩阵运算:XT * C = YT。
实际在计算机中,并不是逐像素滑动计算,效率太低。而是将卷积核转换成等效的矩阵,通过输入向量和卷积核矩阵相乘获得输出向量。如图,input:4x4,Kernel:3x3,Padding/Stride:0,output:2x2,卷积核要在输入的不同位置卷积4次,通过补零将卷积核分别置于一个4x4矩阵的四个角落,这样输入可以直接和这四个4x4的矩阵进行卷积,取代了滑窗操作。将输入展开为[16,1]向量X,输出矩阵记作Y([4,1]),四个4x4卷积核分别展开并拼接成卷积矩阵C([16,4])。普通的卷积运算可表示为矩阵运算:XT * C = YT。
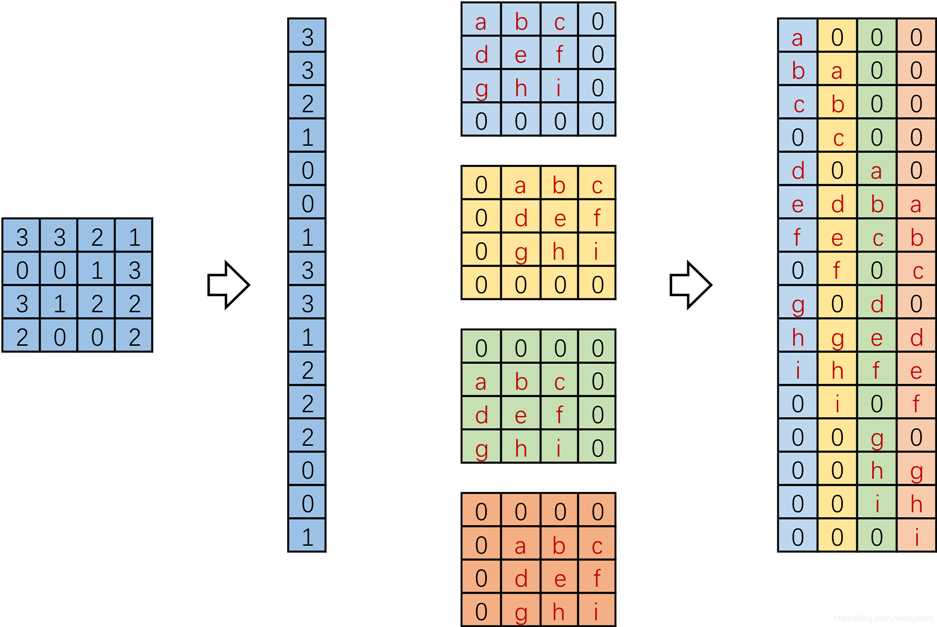
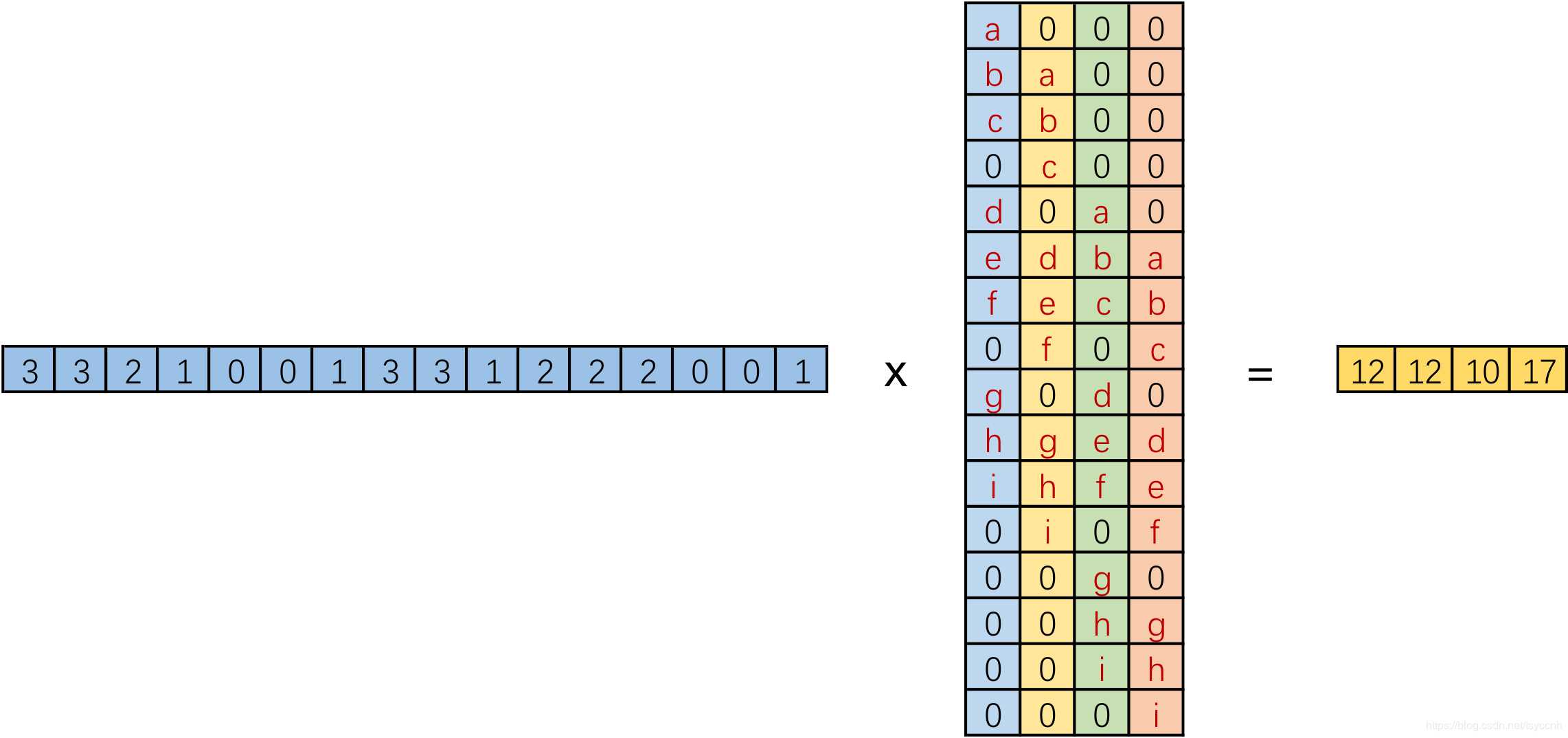
我们将一个1x16的行向量乘以16x4的矩阵,得到了1x4的行向量。反过来,在需要输入一个小的特征,输出更大尺寸的特征时,将一个1x4的向量乘以一个4x16的矩阵就能得到一个1x16的行向量,这就是转置卷积的思想。根据普通卷积,公式改写为:YT * CT = XT。
 普通卷积和转置卷积这两个操作不可逆,同一个卷积核在转置卷积操作之后不能恢复原始数值,只恢复形状。相同的形状就足够了,在训练中我们可以学习卷积核对应的权值来还原图像。
普通卷积和转置卷积这两个操作不可逆,同一个卷积核在转置卷积操作之后不能恢复原始数值,只恢复形状。相同的形状就足够了,在训练中我们可以学习卷积核对应的权值来还原图像。
关键策略:
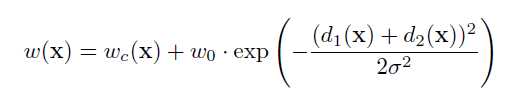
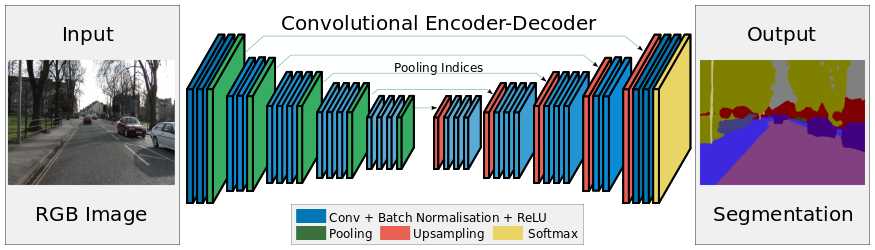
encoder的基本单元是:2-3个same卷积层(图像size不变,BN对训练图像的分布归一化,加速学习)接一个max pooling(2x2)下采样;
decoder的基本单元是:upsampling接2-3个same卷积层,卷积为上采样放大的图像丰富信息,使池化过程丢失的信息被重建。
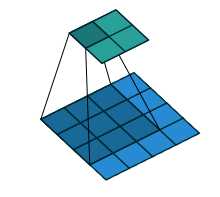
SegNet在pooling上有个创新,引入了index功能。这里详细解释下。
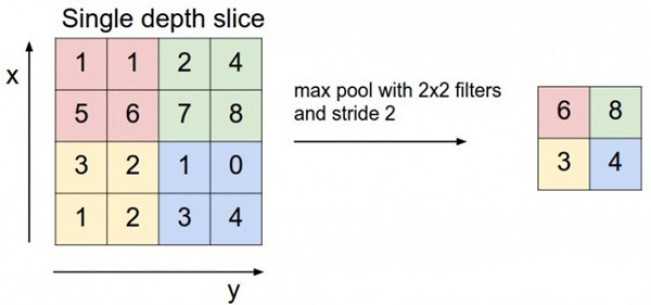
如上图,每次pooling,都会保存通过max选出的权值在2x2 filter中的相对位置,6在粉色2x2 filter中的位置为(1,1)(index从0开始),黄色的3的index为(0,0)。同时,从网络结构图可以看到绿色的pooling与红色的upsampling通过pooling indices相连,表示pooling后的indices输出到对应的upsampling层。upsampling中先对输入的特征图放大两倍,然后把输入特征图的数据根据pooling indices放入,如下图所示。
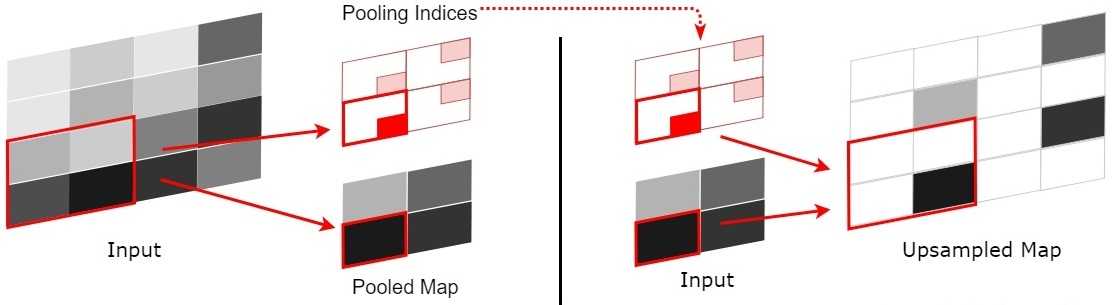
2x2的输入变成4x4的图,除了被记住位置的pooling indices,其他位置的权值为0,因为数据已经被pooling走了。因此,SegNet使用卷积来填充缺失的内容。
(2).分类策略。
在网络框架中,SegNet最后一个卷积层会输出所有的类别(包括其他类),网络最后加上一个softmax层,由于是端到端,所以softmax需要求出每一个像素在所有类别最大的概率,作为该像素的label,最终完成图像像素级别的分类。
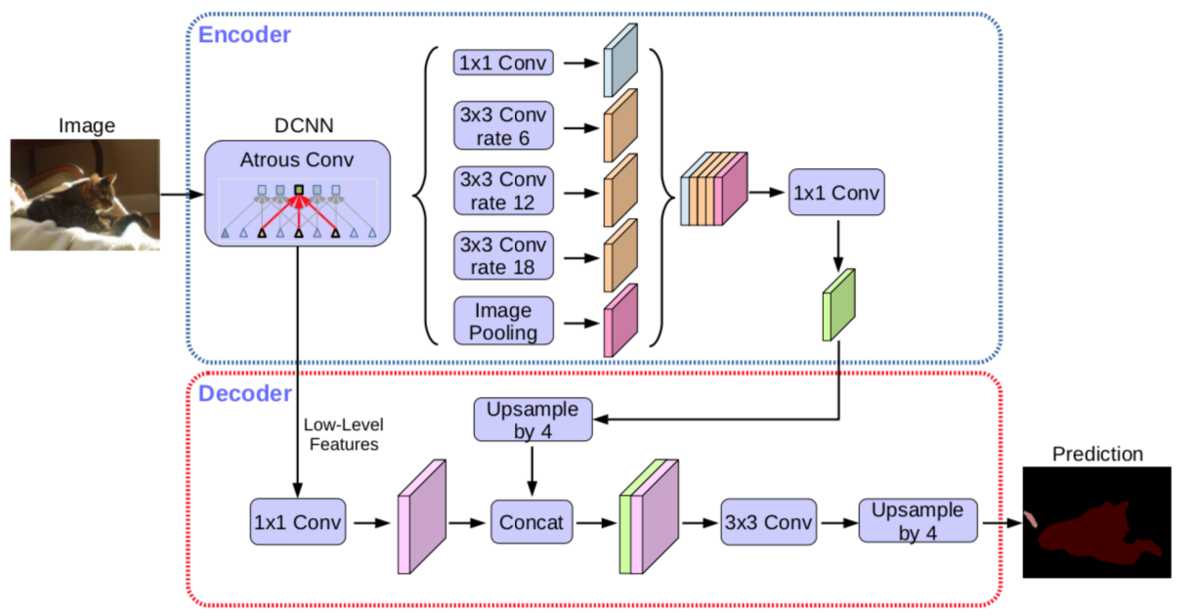
encoder: 原DeepLabv3作为encoder,ASPP有四个不同的rate,额外一个全局平均池化;
decoder: 先把encoder的结果上采样4倍,然后与resnet中下采样前的特征(先1x1卷积降通道数)concat,再进行3x3的卷积,最后上采样4倍输出结果。
关键策略:
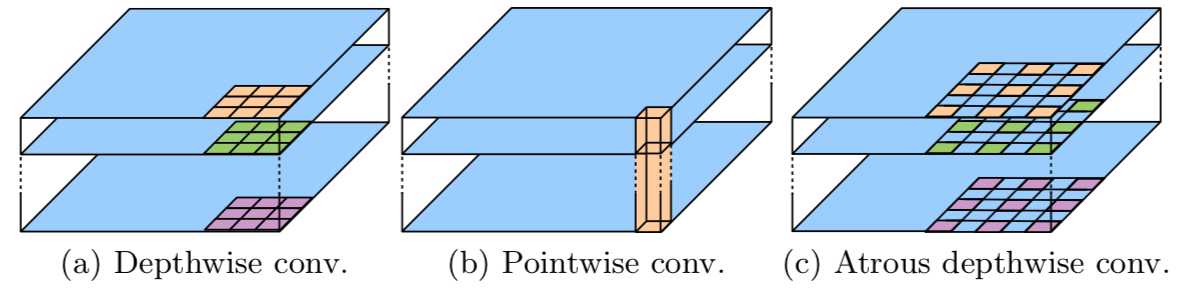
(1).深度可分离卷积(Depthwise separable convolution)。
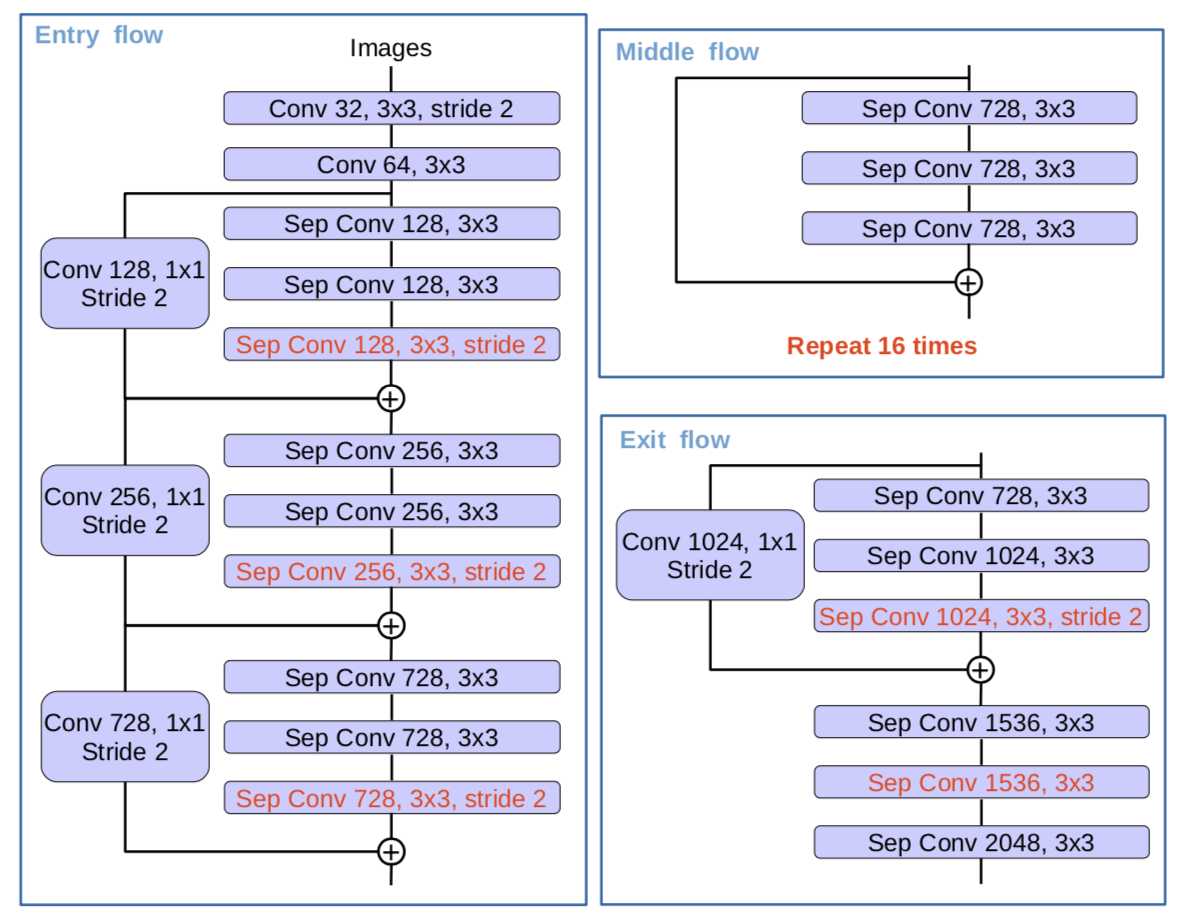
encoder的主干网络Xception中引入的深度可分离卷积: depthwise_separable_convolution = depthwise_convolution(先每个通道上独自进行空间卷积) + pointwise_convolution(再用1x1卷积核组合前面dep_conv得到的特征),在保持网络性能的同时,大幅减少参数量。
(2).空洞卷积(dilated convolution)。
又叫膨胀卷积,是通过增加一个超参数dilation rate(kernel的间隔数量),在标准的卷积图里注入空洞来增加感受野,有效避免了upsampling和pooling设计的缺陷:参数不可学习、内部数据结构及空间层级化信息丢失、小物体信息无法重建。
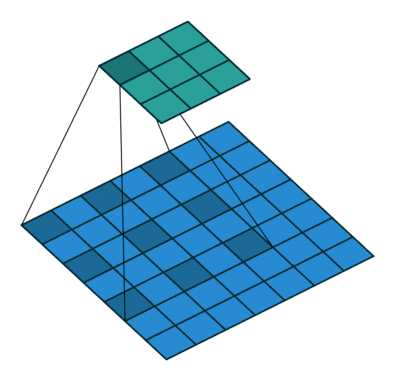
但是,Gridding Effect(kernel不连续,不是所有的pixel都用来计算)会使膨胀卷积损失信息的连续性,另外,单凭大dilation rate获得的信息可能对小物体分割没效果。通向标准化设计,Hybrid Dilated Convolution(HDC)因此被引入。HDC有三个特征:叠加卷积的dilation rate不能有大于1的公约数;将dilation rate设计成锯齿状结构,如[1, 2, 5, 1, 2, 5]循环结构;第2层的最大dilation rate M2 <= kernel size(k),至少可以用dilation rate 1(标准卷积)来覆盖掉所有洞。
(3).ASPP(astrous spatial pyramid pooling)。
ASPP通过不同的rate构建不同感受野的卷积核,捕获多尺度信息,并联(串联)不同膨胀率的空洞卷积,来获取更多上下文信息。
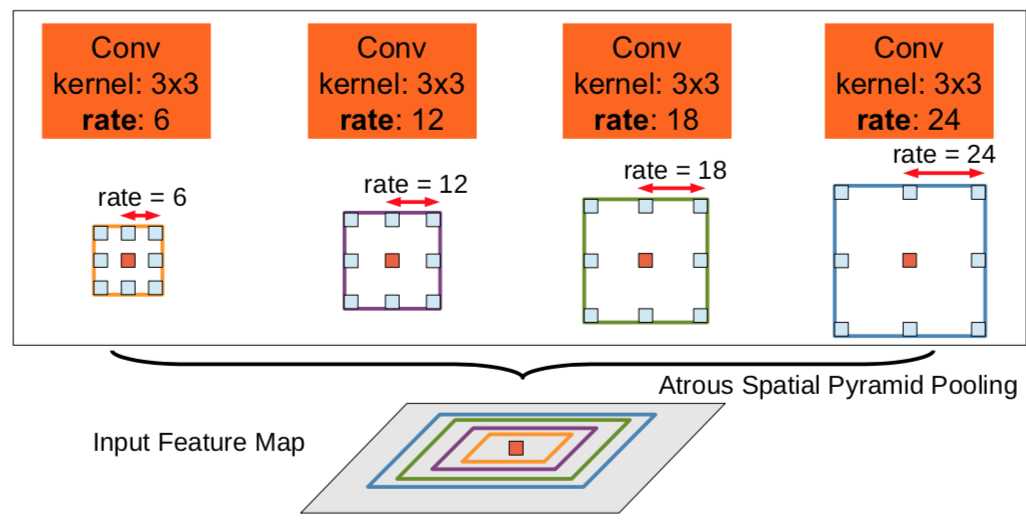
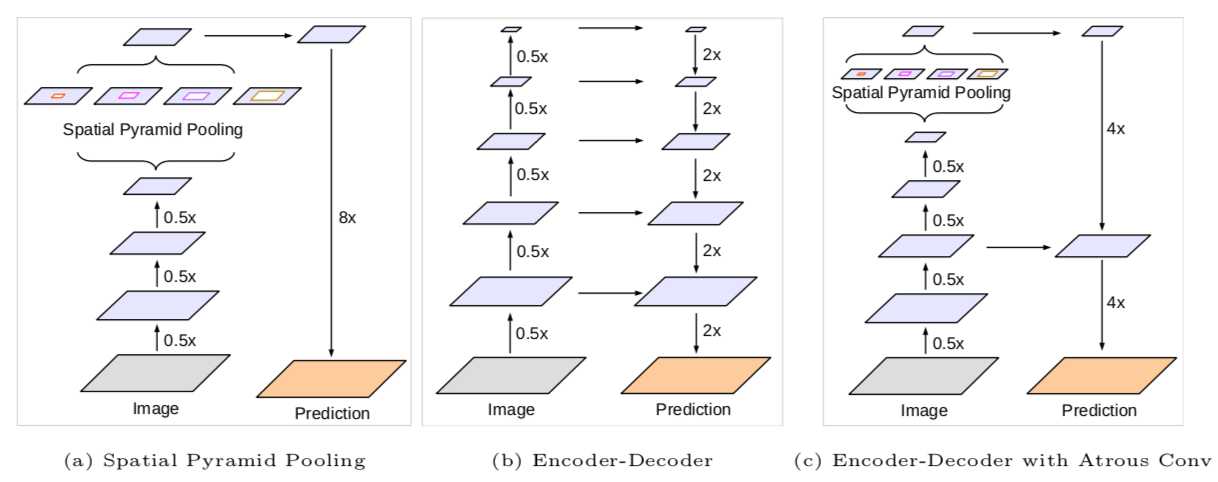
(4).encoder-decoder结构。
把ASPP模块和encoder-decoder结合在一起,encoder-decoder结构可以更好的地恢复物体的边缘信息。
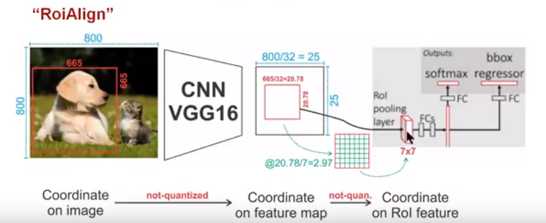
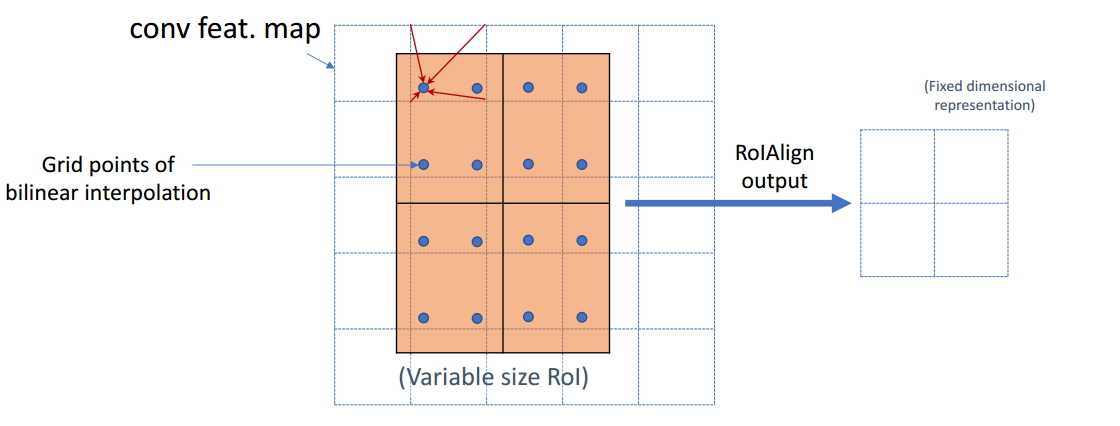
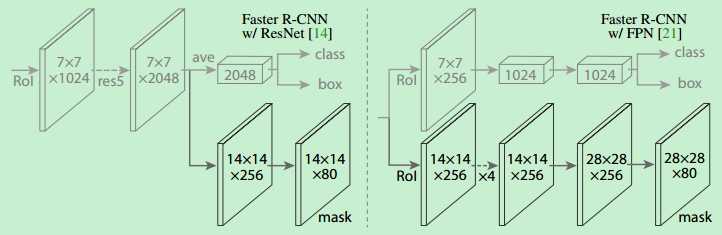
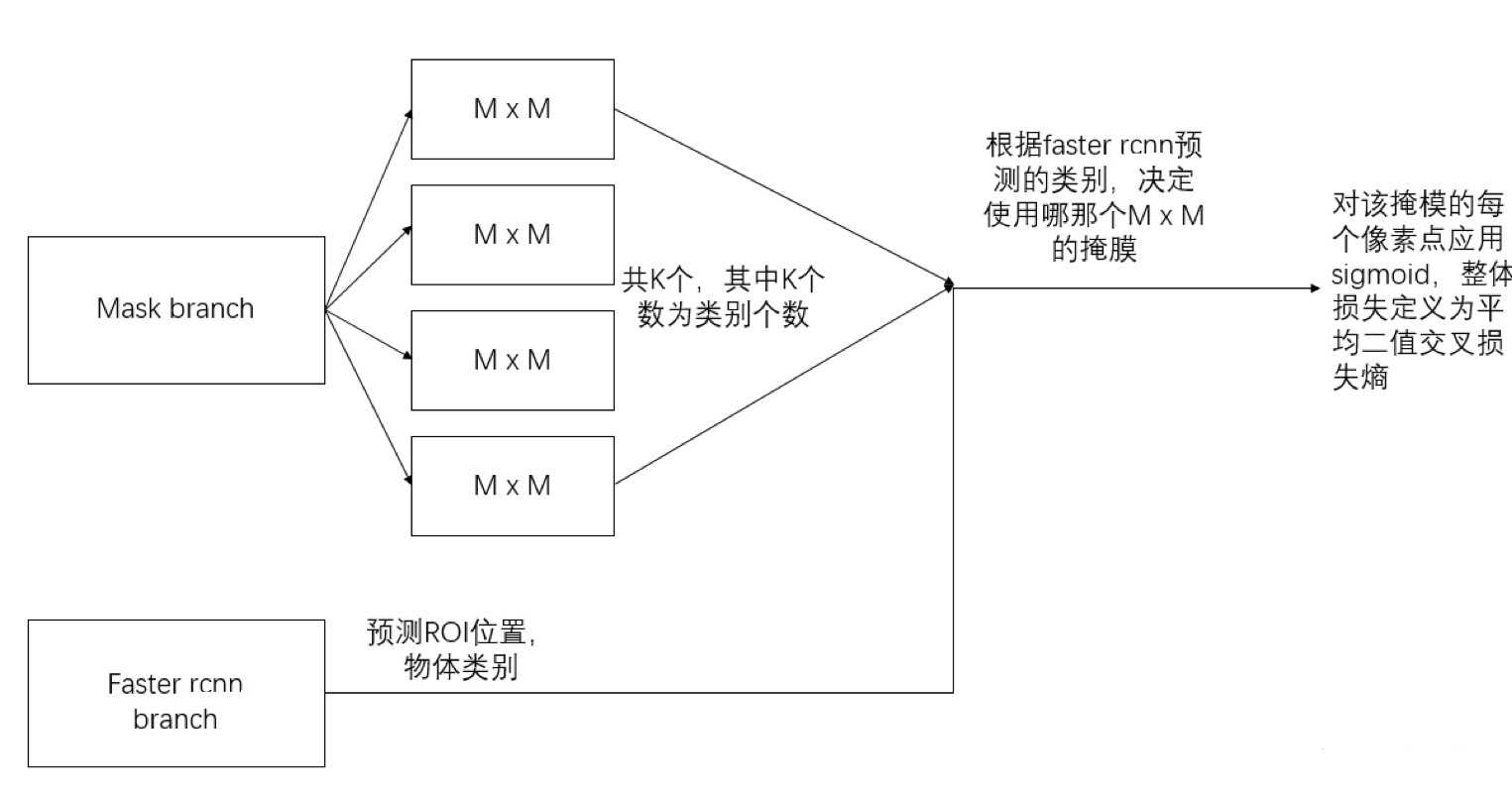
图像分割:Semantic/Instance/Panoramic Segmentation
标签:point 任务 enc 平滑 过滤 而不是 拼接 over 固定
原文地址:https://www.cnblogs.com/lh2n18/p/12340120.html