标签:金融行业 切片 表结构 鲁棒性 就是 时序数据 enter 构建 ali
时序数据是指时间序列数据。时间序列数据是同一指标按时间顺序记录的数据列。在同一数据列中的各个数据必须是同类的,要求具有可比性。简单的来说,就是按照时间为索引的数据列。
对时间序列分析的目的是通过找出样本内时间序列的统计特性和发展规律性,基于规律构建时间序列模型,进行样本预测。
那么对于时序数据,我们通常会去分析数据的极值,中值,偏差,方差,同比,环比以及数据的周期性等特点,从而去总结数据的一些特征,进而对数据有一个大致的认识。
同时,我们还可以使用滑窗统计,即按照时间的顺序对每一个时间段的数据进行统计,从而得到每个时间段内目标体现的特征,进而从连续的时间片段中,通过对同一特征在不同时间维度下的分析,可以得到数据的变化趋势。
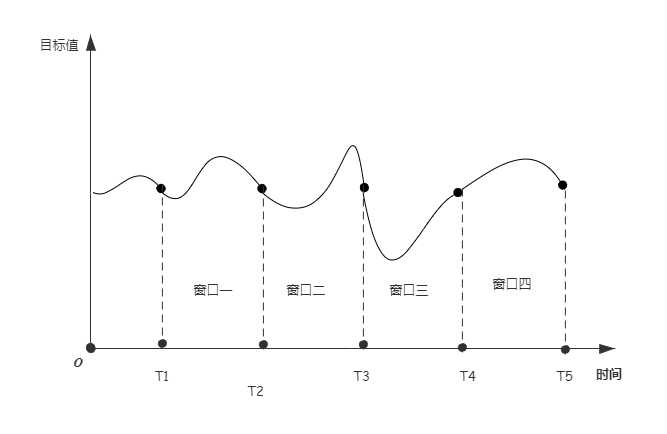
滑动窗口图片
从上图可以看出,滑动窗口便是按照将目标值按照时间进行排序,接着划定每个窗口长度以及大小,计算每个窗口内的特征,便可以得到目标值的变化趋势
在金融行业中,通常获取的表有两种,流水表和切片表,
流水表的定义:流水表对于表的每一个修改都会记录,可以用于反映实际记录的变更。通常用于记录数据变更。
切片表的定义:切片表往往只反映某一个维度的相应数据。其表结构往往只有某一维度,或者某一个事实条件的数据,通常来说,切片分为按天切片,按月切片,按年切片,不同的切片反应了数据在不同时间跨度上的变化。
对于流水表,按照上述方法进行滑窗,即在一段时间窗口内进行特征统计,对不同窗口进行分析即可以得到数据的内在变化趋势。
对于切片表,由于其已经进行了切片,因此其滑窗只能按照最小切片间隔的整数倍进行滑窗
所谓时间穿越,即用到了未来的数据。如下图所示,如果在统计窗口一的同时加入了窗口二内的数据,这就造成了穿越。
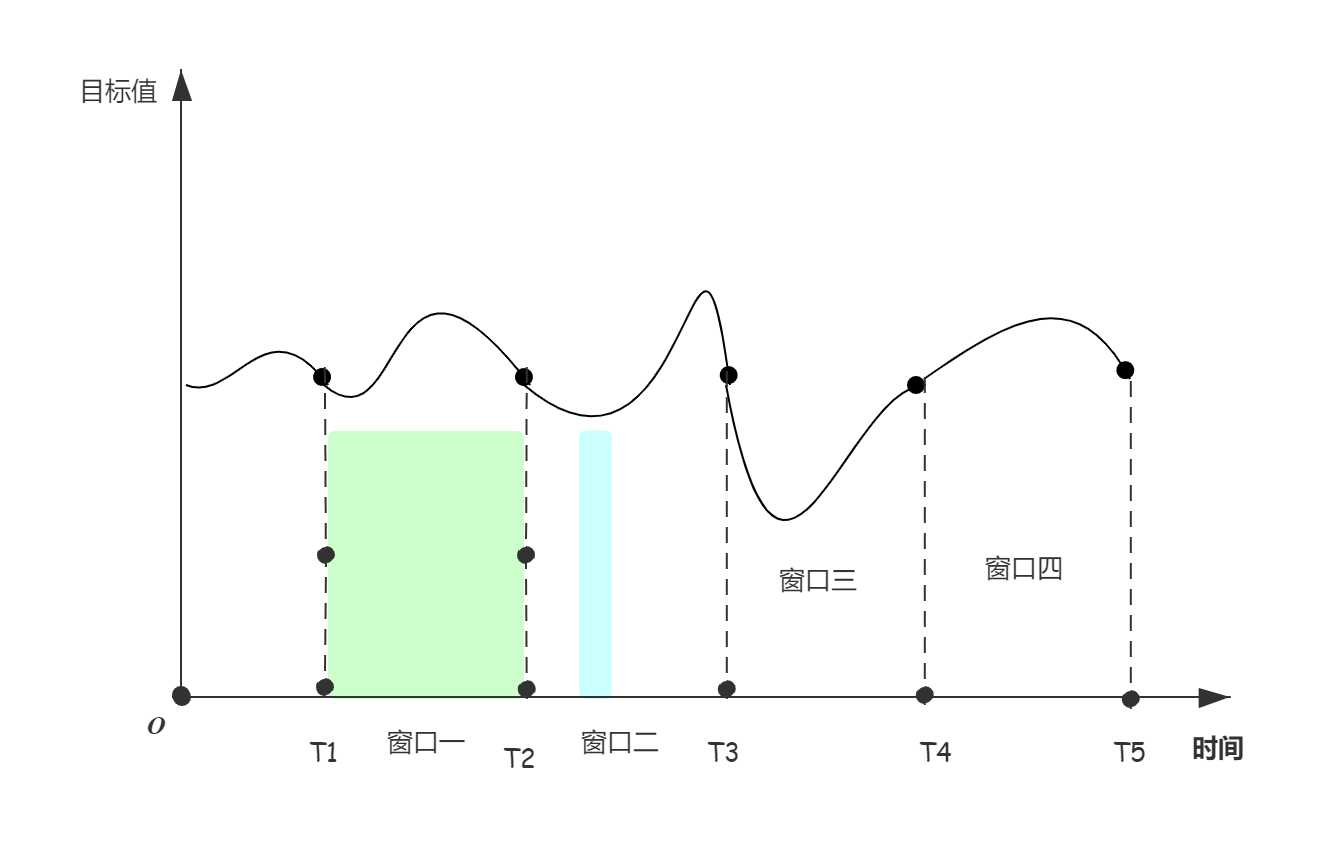
如果使用了穿越数据,那么很显然就会出现模型过拟合的现象。导致模型在训练集中效果却异常优异,但是在测试集或者上线后性能急剧下降。
究其根本原因,是因为在实际场景中,数据行为都是在快速变化的,相近时间内的行为存在一定的相似性,时间相差越远行为差异越大。这一点和一个稳定数据分布场景是完全不同的,如果数据分布在时间维度上是相对稳定的,那么时间因素就不是一个那么重要的因素,相互穿越带来的问题就会比较小。
因此我们在建模过程中为了模型的准确性和鲁棒性,需要避免时间穿越的问题。
因此,如果需要避免穿越,就不要使用未来数据即可,但是,在这之间有一些点需要注意,建模过程中常常误加入穿越数据。
标签:金融行业 切片 表结构 鲁棒性 就是 时序数据 enter 构建 ali
原文地址:https://www.cnblogs.com/tjpeng/p/12368665.html