标签:code ado width 进程 高效 持久 创建对象 空间 map
一、什么是序列化与反序列化
序列化是把对象转换为字节序列的过程,使之持久化到磁盘和网络传输(write过程)
反序列化是把字节序列转换为对象的过程,使之成为内存中的对象(read过程)
二、为什么要进行序列化与反序列化
对象只能在内存中
对象只能在本地的进程中使用
通过序列化与反序列的操作:
永久保存对象
将对象使用在网络传输中
三、Java的序列化与Hadoop的序列化
在MapReduce过程中大量使用序列化机制,Java会不断的创建对象,因此必须减少序列化与反序列化的开销。
(本文侧重于Hadoop的序列化,Serializable自行查看学习)
Java的序列化框架Serializable属于重量级框架,信息详细结构很完整但是不便于在网络中进行高效传输
Hadoop的序列化机制有以下优点:
紧凑:高效实用存储空间
快速:读写数据的额外开销小
可扩展:随着通信协议的升级而升级
互操作:支持多语言的交互(自行了解IPC机制)
Hadoop的Writable源码
自定义的bean对象只需要实现Writable接口重写接口中的两个方法即可实现序列化与反序列化
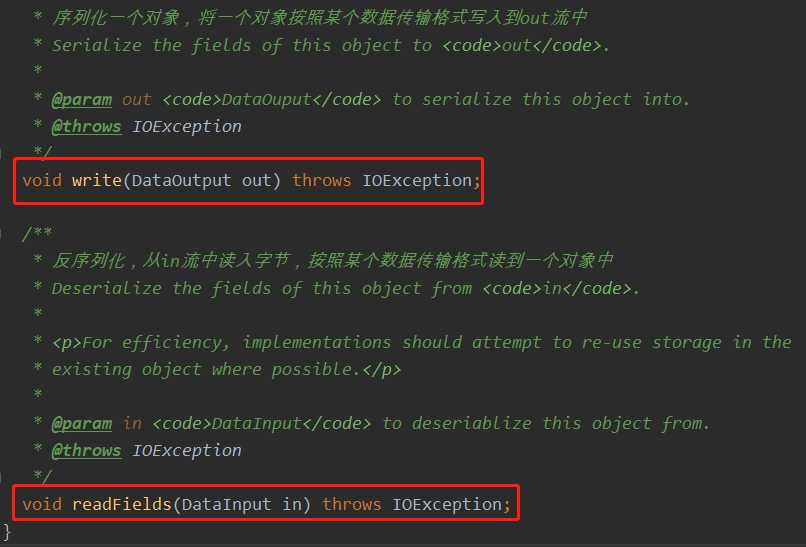
总结:Hadoop的序列化机制:高效,快速,消耗小
标签:code ado width 进程 高效 持久 创建对象 空间 map
原文地址:https://www.cnblogs.com/atBruce/p/12369476.html