标签:执行 oca 场景 info str roc mysql数据库 tag style
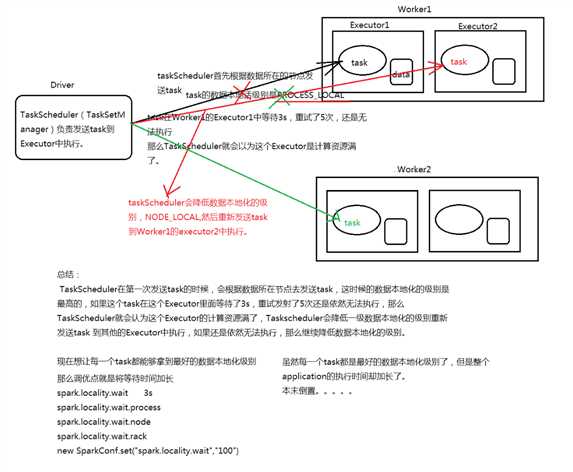
Application任务执行流程: 在Spark Application提交后,Driver会根据action算子划分成一个个的job,然后对每一 个job划分成一个个的stage,stage内部实际上是由一系列并行计算的task组成的,然后 以TaskSet的形式提交给你TaskScheduler,TaskScheduler在进行分配之前都会计算出 每一个task最优计算位置。Spark的task的分配算法优先将task发布到数据所在的节点上 ,从而达到数据最优计算位置。
一、数据本地化级别:
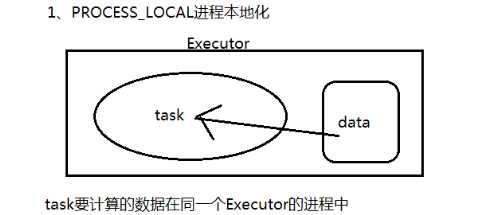
PROCESS_LOCAL 进程本地化
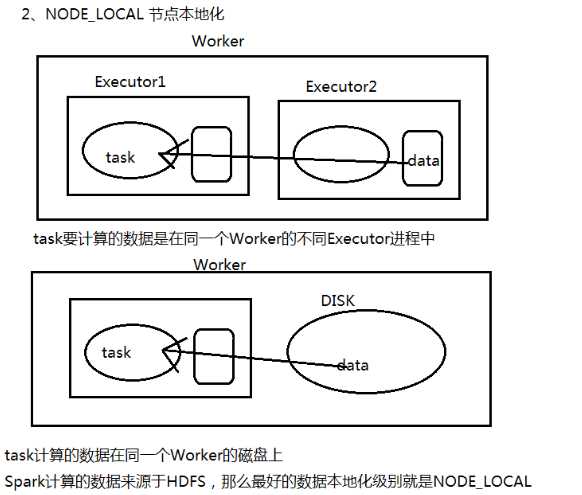
NODE_LOCA 节点本地化
NO_PREF 没有最佳位置这个说法 比如用到SparkSQl读取mysql数据库里的数据
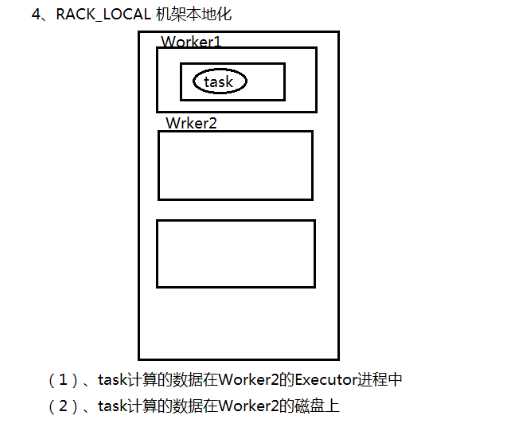
RACK_LOCAL 机架本地化
ANY 随机安排 跨机架
二、实际场景:

三、总结:
标签:执行 oca 场景 info str roc mysql数据库 tag style
原文地址:https://www.cnblogs.com/wyh-study/p/12376768.html