标签:超过 img str lang list data- filter uid elastic
我们可以使用from +size来获取所有数据,但是,如果数据量大的时候,这样的操作开销很大,这时候可以使用scroll操作
1.第一步发起一个scroll 的post请求,带上参数scroll=1m (1m的意思是1分钟的意思)
POST /twitter/_search?scroll=1m
{
"size": 100,
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
这一步会得到一个_scroll_id
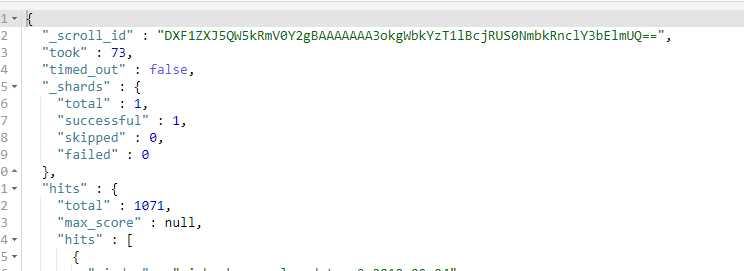
2. 使用第一步得到的_scroll_id 来翻页,一直执行这个请求,就可以得到所有的数据了
POST /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAA3okgWbkYzT1lBcjRUS0NmbkRnclY3bElmUQ=="
}
注意:
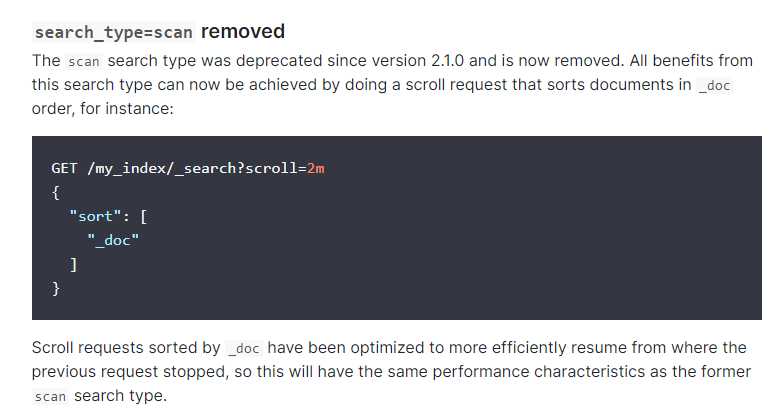
1. 如果想加快索引,第一步加上sort选项, 有些文章会说使用 search_type=scan ,但这个选项是要es 2.1版本之前才有用,之后的版本就被弃用了,改成sort选项了
GET /_search?scroll=1m
{
"sort": [
"_doc"
]
}
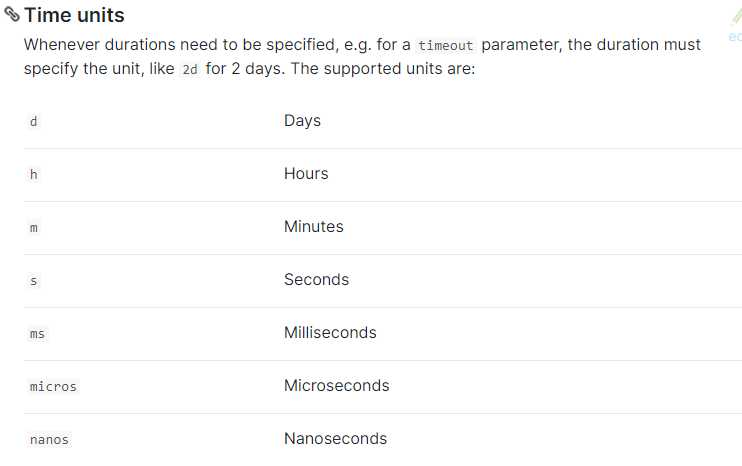
2.scroll参数说明,这个表示_scroll_id的有效期有多久,如果超过这个有效期,那再去翻页就会得到404 error,并且每次翻页都会重置有效期,所以这个有效期只需要大于前后两次翻页的时间(也就是你处理一页数据的时间)
3. scrapy去请求翻页,很有可能因为_scroll_id没有变化,造成请求重复而被放弃,一定要加上dont_filter=True
4.我在做这个测试的时候,发现window测试电脑用外网地址去请求centos服务器的ES数据很慢,而用内网中的linux计算机去请求同样的服务器数据,时间快了20倍
参考
https://www.elastic.co/guide/en/elasticsearch/reference/5.4/breaking_50_search_changes.html
标签:超过 img str lang list data- filter uid elastic
原文地址:https://www.cnblogs.com/WalkOnMars/p/12377313.html