标签:prim number serve std cto epo 说明 图片 software
主要补充内容:
1.同步多表
2.配置的参数个别说明
3.elasticsearch的"_id"如果有相同的,那么会覆盖掉,相同"_id"的数据只会剩下最后一条。所以还是用数据表中主键自增的id比较好,当然如果有需要也可以自己改变成别的UUID之类的。
elasticsearch默认的"_type"的值是"_doc"
先看一个配置
input { jdbc { jdbc_connection_string => "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC" jdbc_user => "root" jdbc_password => "root" jdbc_driver_library => "D:\softwareRepository\logstash-7.0.0\config\test-config\mysql-connector-java-5.1.46.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_paging_enabled => "true" jdbc_page_size => "50000"
#zyl.sql的语句是 select * from wuwu_user 我没有使用;结尾,听说用;的话会有问题,不过我也没试 statement_filepath => "D:\softwareRepository\logstash-7.0.0\config\test-config\zyl.sql" schedule => "* * * * *" } jdbc { jdbc_connection_string => "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC" jdbc_user => "root" jdbc_password => "root" jdbc_driver_library => "D:\softwareRepository\logstash-7.0.0\config\test-config\mysql-connector-java-5.1.46.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_paging_enabled => "true" jdbc_page_size => "50000" parameters => {"number" => "200"}
#zyl1.sql的语句是:SELECT * from wuwu_kill statement_filepath => "D:\softwareRepository\logstash-7.0.0\config\test-config\zyl1.sql" schedule => "* * * * *" } } filter { json { source => "message" remove_field => ["message"] } } output { if[name] == "zyl" { elasticsearch { hosts => ["localhost:9200"] index => "wuwu_user" document_id => "%{name}" } } if[age] == 18 { elasticsearch { hosts => ["localhost:9200"] index => "wuwu_kill" document_id => "%{age}" } } elasticsearch { hosts => ["localhost:9200"] index => "wuwu_other" document_id => "%{id}" } stdout { codec => json_lines } }
这里面的if[xx]==xx是个判断语句,符合哪个标准就生成哪个index。如果同一条数据同时符合两个if, 那么这条数据会同时插入两个index中。也就是说上面的if,if和java的if,if结构一样。而没有if, 直接是elasticsearch的这个是:凡是所有符合了if条件的生成的index的所有数据,它也全都要来一份。
除了if似乎还有别的条件判断操作,但是对我目前使用来说已经够了,所以就没有细究。
然后是document_id=>"%{xx}", 这个xx对应的是你的表里的某一个字段。如果这个不写会出现的问题是:每扫描一次数据库的数据,那么会把符合的数据继续增加。意思是:假设数据不改变,第一次有三条数据符合,加入了index中,再一次扫描会生成同样的三条数据加入index。 并且原本elasticsearch的"_id"是按照这个配置来的,如果你没写,那么elasticsearch会自动生成UUID。并且在没有设置document_id=>的情况下,上一条说的没有if的elastcisearch的index会乱加数据,不存在其他if的index的数据它也会加进去。
document_id=>"%{xx}"的xx不一定非要是数据表的主键,也不一定非要数据表的id字段。
实际上,经过我3个小时的测试,在使用logstash的时候,数据表的结构可以是随意的,没有主键,没有id字段什么的都是可以的。然后规范操作就靠你自己了。
最后附上几张效果图,和我测试时随意写的创表语句
create table wuwu_user ( id int primary key auto_increment, name varchar(5), age int ); create table wuwu_kill ( id int primary key auto_increment, age int, name char(5) ); insert into wuwu_user(name,age) value ("zyl",18),("lxf",18),("lw",19); insert into wuwu_kill(age,name) value (18,"lxf"),(19,"zyl"),(20,"lw"); update wuwu_user set age=18 where name="lw"; update hehe_user set name="zyl" where age=19; update hehe_kill set age=18 where name="lw";
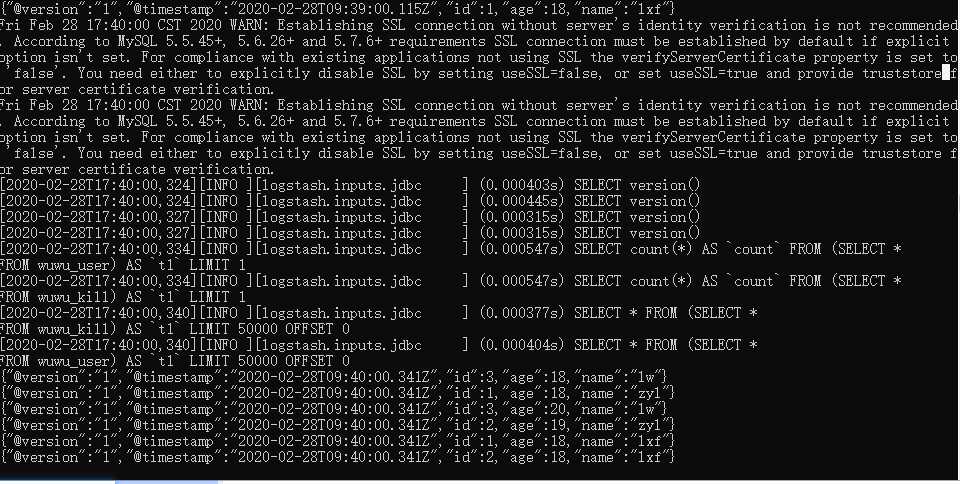
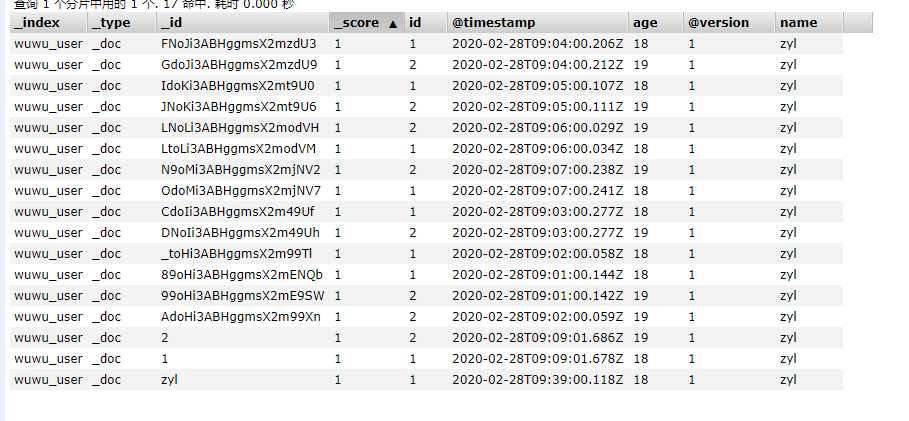 elasticsearch看起来好像每个select语句都执行了两次,好像是正常现象,我多加了一个if,一共三个if就有被执行的,还是每个语句两遍。
elasticsearch看起来好像每个select语句都执行了两次,好像是正常现象,我多加了一个if,一共三个if就有被执行的,还是每个语句两遍。
标签:prim number serve std cto epo 说明 图片 software
原文地址:https://www.cnblogs.com/woyujiezhen/p/12378174.html