标签:file sel min 定义 count index form oca hadoop
首先我们知道聚合函数(如sum()、avg()、max()等等)是针对定义的行集(组)执行聚集,每组只返回一个值。
窗口函数也是针对定义的行集(组)执行聚集,可为每组返回多个值。如既要显示聚集前的数据,又要显示聚集后的数据。
窗口查询有两个步骤:将记录分割成多个分区,然后在各个分区上调用窗口函数。
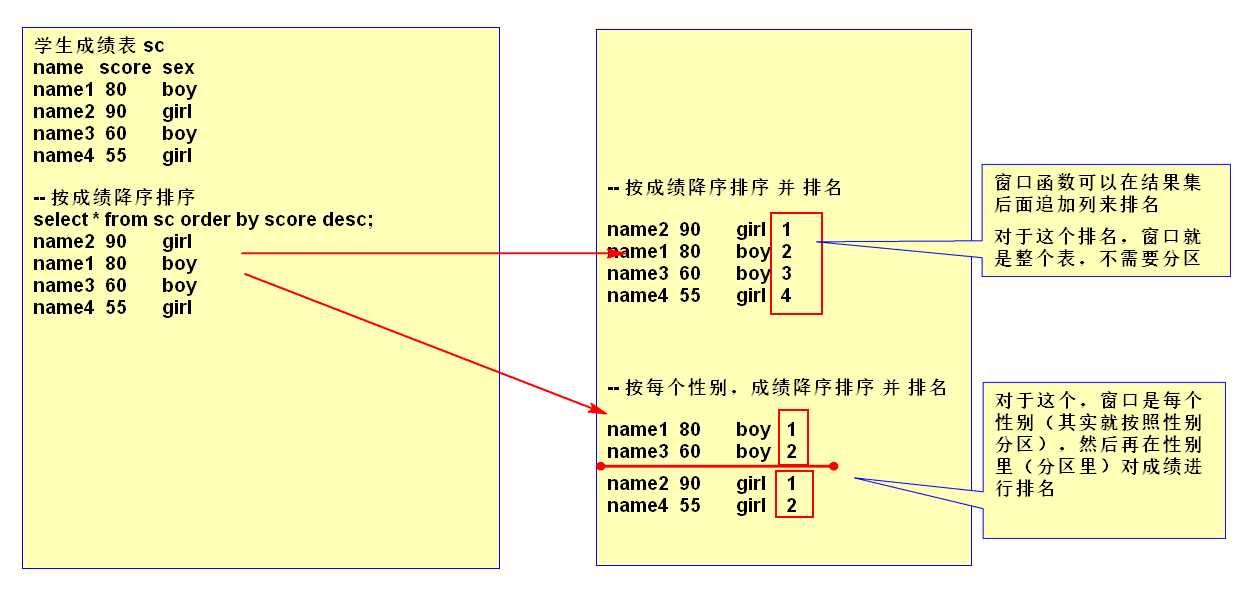
语法:主要是over( PARTITION BY (根据某条件分组,形成一个小组)….ORDER BY(再组内进行排序) …. )
over (order by col1) --按照 col1 排序
over (partition by col1) --按照 col1 分区
over (partition by col1 order by col2) -- 按照 col1 分区,按照 col2 排序
--带有窗口范围
over (partition by col1 order by col2 ROWS 窗口范围) -- 在窗口范围内,按照 col1 分区,按照 col2 排序
--建表
CREATE TABLE wt1(
id int,
name string,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘;
-- 初始化数据 id name age \t分割
1 a1 10
2 a2 10
3 a3 10
4 a4 20
5 a5 20
6 a6 20
7 a7 20
8 a8 30
-- 加载数据
load data local inpath ‘/home/hadoop/d1/file1‘ overwrite into table wt1;
-- 窗口范围是整个表
-- 按照age排序,每阶段的age数据进行统计求和
select
id,
name,
age,
count() over (order by age) as n
from wt1;
运行结果 : 将整个表作为一个窗口,然后对这个窗口中排序的字段进行分别计算
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.27 sec HDFS Read: 9498 HDFS Write: 263 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 270 msec
OK
3 a3 10 3
2 a2 10 3
1 a1 10 3
7 a7 20 7
6 a6 20 7
5 a5 20 7
4 a4 20 7
8 a8 30 8
------------------------------------
-- 窗口范围是表下按照age进行分区
-- 在分区里面,再按照age进行排序
select
id,
name,
age,
count() over (partition by age order by age) as n
from wt1;
-- 运行结果 使用age作为新的分区 然后针对各个分区使用聚合函数分开统计
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.77 sec HDFS Read: 9354 HDFS Write: 263 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 770 msec
OK
3 a3 10 3
2 a2 10 3
1 a1 10 3
7 a7 20 4
6 a6 20 4
5 a5 20 4
4 a4 20 4
8 a8 30 1
----------------------------------
-- 窗口范围是表下按照age进行分区
-- 在分区里面,再按照id进行排序
select
id,
name,
age,
count() over (partition by age order by id) as n
from wt1;
-- 根据年龄分三个窗口 然后每个窗口中按ID排序 count记录每个窗口中id出现的次数
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.96 sec HDFS Read: 9421 HDFS Write: 263 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 960 msec
OK
1 a1 10 1
2 a2 10 2
3 a3 10 3
4 a4 20 1
5 a5 20 2
6 a6 20 3
7 a7 20 4
8 a8 30 1

标签:file sel min 定义 count index form oca hadoop
原文地址:https://www.cnblogs.com/zhuziz/p/12381987.html