标签:learning inf 因子 团队 机器 abd 组合 结构 引入

摘要:上一篇广告行业中那些趣事系列2:BERT实战NLP文本分类任务(附github源码)通过项目实战讲解了如何使用BERT模型来完成文本分类任务。本篇则从理论的角度讲解BERT模型的前世今生。BERT虽然在模型创新的角度来说并不是非常出色,但它是近几年NLP领域杰出成果的集大成者。BERT大火最重要的原因是效果好,通用性强两大优点。可以说BERT的出现是NLP领域里具有里程碑意义的大事件。本篇主要讲解NLP里面的Word Embedding预训练技术的演化史,从最初的Word2Vec到ELMO、GPT,再到今天的巨星BERT诞生,还会讲解如何改造BERT模型去对接上游任务以及BERT模型本身的创新点。
本篇对数据挖掘、数据分析和自然语言处理的小伙伴会有些许帮助。一起努力,终身学习!
目录
01 BERT模型的两阶段技术
02 预训练技术
03 微调及BERT改造
04 BERT的创新之处
01 BERT模型的两阶段技术
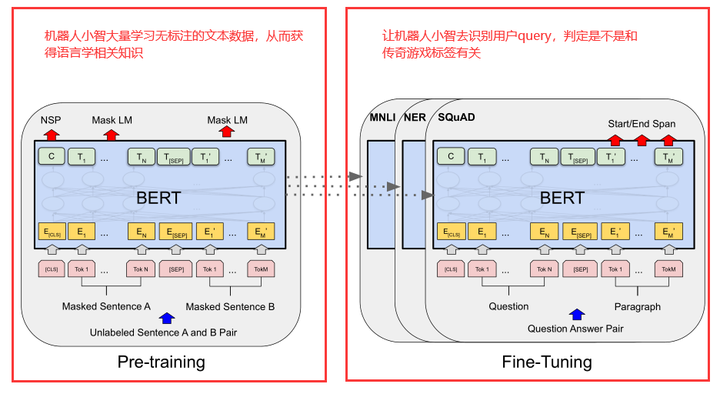 图1 BERT 预训练+Fine Tuning两阶段
图1 BERT 预训练+Fine Tuning两阶段
之前咱们通过一个非常简单的例子讲解了下BERT模型的两阶段技术:预训练Pre-Training和微调Fine-Tuning技术。这里咱们再回顾下。拿上一篇识别一段话是不是属于传奇游戏标签来举例。假如我们有个机器人小智,现在我们希望小智能帮我们完成这样一个任务:我们给小智输入一句话(可能是用户的搜索),小智就能判断这句话是不是对传奇游戏标签有兴趣。
针对这个任务,BERT模型怎么做的?
BERT主要采用预训练和微调的两阶段架构。预训练做的事就是提前让小智看海量的文本语料。这些语料可能来自现实世界或者网络世界。小智通过这些语料,学习到了很多语言学知识。
很多小伙伴要问了,如果没有预训练这个阶段会咋样?再举个极端的例子,你分别告诉一个刚出生的婴儿和一个大学毕业的小伙子“成龙大哥代言的一刀传奇好玩么”,他们两个的理解能力是完全不同的。
预训练过程的本质就是通过大量的语料,从而获得语言学的知识,最终能更好的帮助我们理解语言本身。这就是预训练技术!
BERT的第二个阶段微调更像是具体问题具体分析。我们可能希望机器人小智来识别女朋友是不是生气了(分类任务),也可能希望小智帮我们翻译下喵星人石榴(我家胖猫叫石榴)说了啥(翻译任务),还可能希望小智帮我们看一篇文章主要讲了啥(自动摘要任务)等等。
根据你实际的业务需求,通过第二阶段来完成你想让模型做的事。
总结下,BERT是两阶段模型,预训练通过学习大量的语料获得语言学知识,微调则真正让我们的模型解决实际生活中问题。
02 预训练技术
1.One-hot编码
预训练阶段要解决的一个很重要的问题是文本的表示问题。我们给计算机输入一个词"legend",计算机并不明白你的意思。计算机能理解的就是01这种数字,所以我们要做的就是对词进行编码。
通常机器学习中我们会使用One-hot编码。小伙伴们要问了,啥是One-hot编码?
举例来说,我们现在一共就四个词:"i","love","legend","game"。计算机本身无法理解这四个词的含义,但是我们现在用一种编码表示。"i"编码为1000,"love"编码成0100,"legend"编码为0010,"game"编码为0001。
对One-hot通俗的理解就是有多少个词,就有多少位。如果有8个词,我们就需要长度为8的01串来表示词。每个词都有自己的顺序,那么对每个词One-hot编码的时候在该位置上置1其他都置为0。
现在我们把这四个词对应的编码输入到计算机里,计算机就能明白各个编码代表的含义。这种形式就是One-hot编码。通过One-hot编码我们就能轻松的表示这些文本。
2. Word2vec
One-hot编码存在一个问题,上面的例子中有四个词,那么我们就需要长度为4的01串来表示。如果有100W个词,那么我们就需要长度100W的01串来进行编码么?这显然不方便。
然后引入了embedding技术。深度学习中embedding技术大肆风靡,甚至有"万物皆可embedding"之说。有些小伙伴可能要好奇了,我们用embedding能干啥?
自然语言中我们使用embedding技术进行词编码,也叫Word Embedding。其中最有代表性的就是2013年超火的Word2Vec技术。Word2Vec技术主要将词映射到向量空间,通过一组向量来表示词,实现对文本的表示。Word2Vec技术很好的解决了One-hot编码引起的高纬度和稀疏矩阵的问题。
下图是我们通过Word2Vec将文本映射到三维立体空间中:
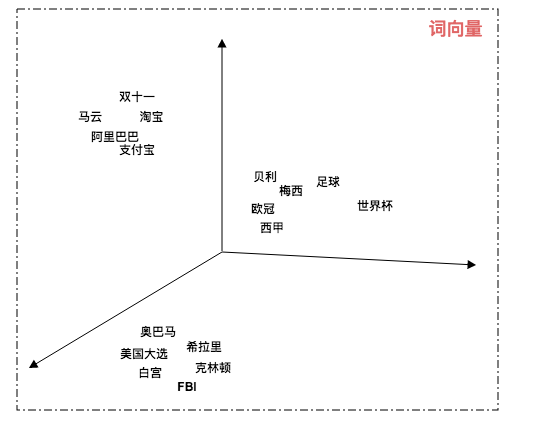 图2 Word2Vec映射到三维空间展示图
图2 Word2Vec映射到三维空间展示图
通过Word2Vec技术我们可以在低纬空间上表示文本。我们可以通过计算词向量空间中的距离来表示语义的相似度。
但是Word2Vec技术也存在明显的缺陷。那就是无法解决多义词问题。比如"legend"这个词,它既可以代表一个人牛逼的人生经历,比如科比拥有传奇的一生。也可以代表图例。但是在Word2Vec中每个词在向量空间中的表示是唯一的。可以假装理解我们有一张很大的表,这张表用来存放所有的词,但是每个词在表中id唯一。在不同的语句环境中"legend"对应不同的语义,但是却使用的是一样的编码。
归根结底,就是因为Word2Vec是静态的Word Embedding。
3. ELMO
为了解决Word2Vec无法理解多义词的问题,2018年NAACL最佳论文《Deep contextualized word representations》提出了ELMO模型。
ELMO模型怎么解决多义词问题呢?先上一张图。
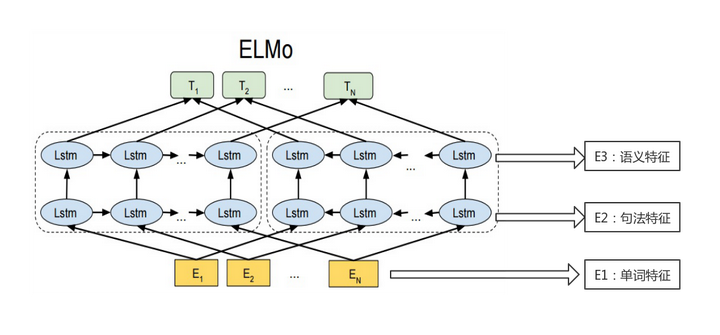 图3 ELMO模型结构
图3 ELMO模型结构
ELMO模型的思想是:模型一开始输入的词向量虽然是静态的Word Embedding,但是没有关系。等模型在预训练的时候可以看到完整的语句,也就拥有了词的上下文。那么我就会根据这个词的上下文来动态的调整Word Embedding。
说的好听,怎么动态调整词的Word Emebedding?
简单的说Word2Vec通过一个向量来表示一个词,现在ELMO用三个向量来表示。
ELMO不仅使用词向量本身,还会通过图3中虚线的左右两个双层LSTM网络结构来学习语句中的句法特征和语义特征。最后拿词向量、句法特征向量和语义特征向量三个向量组合成一个理解了上下文的向量来最终表示这个词。
所以说Word2Vec是静态的Word Embedding
而ELMO是动态的Word Embedding。
 图4 ELMO和Word2Vec表示Word Embedding
图4 ELMO和Word2Vec表示Word Embedding
关于ELMO模型具体怎么通过左右两个双层的LSTM网络来学习句法特征和语义特征,这里做简要说明。LSTM是循环神经网络RNN的变种,要讲的话又是超长的知识分享。这里大家只需要明白ELMO使用LSTM作为特征抽取器来抽取特征就行了。
后续有机会可以分享目前假期正在看的台大李宏毅的深度学习课程笔记。有兴趣的小伙伴也可以去B站搜索"台大李宏毅"就会出来了。浅显易懂的深度学习课程分享给大家。
ELMO使用LSTM来抽取特征。这里再说一个概念,具体预训练的时候我们可以拿到整句话。当我们需要表示某个词的时候,该词前面的部分称为上文,后面的部分称为下文。ELMO模型结构图中虚线的部分是两个双层的LSTM网络结构,左边的是一个正向的双层LSTM网络,主要用来理解这个词的上文。同理右边的是一个逆向的双层LSTM网络,主要用来理解这个词的下文。也就是说ELMO会同时考虑上文和下文。
总结下,ELMO通过左右两个双层的LSTM网络利用上下文的知识共同来表示这个词,所以说它是动态的Word Embedding。Word2Vec和ELMO不同最直接的结果就是,一个词"legend"在一万句话里面Word2Vec表示是一样的,而在ELMO里面可能有一万种表示。
因为后续涉及到和BERT模型的对比,所以关于ELMO模型的归纳就是:一方面使用了LSTM作为特征抽取器,另一方面同时考虑了上下文。
4. GPT
GPT是"Generative Pre-Traingng"的简称,中文是生成式预训练的意思,由论文《Improving Language Understanding by Generative Pre-Training》提出。先来一张GPT模型的结构图压压惊:
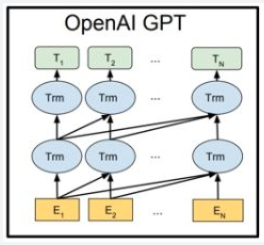 图5 GPT模型结构图
图5 GPT模型结构图
GPT和ELMO一样也是动态的Word Embedding,可以解决多义词的问题。和ELMO不用之处在于GPT特征抽取器使用的是Transformer,而ELMO使用的是LSTM。
这里大概提一下Transformer。Transformer是2017年google团队在《Attention is all you need》论文中提出的。这里大家只需要明白Transformer的特征抽取能力非常强,比LSTM强的多就够了。具体为啥强,之前在团队做过一个Transformer的分享,广告系列的下一篇文章会详细讲一下Transformer。希望有兴趣的小伙伴们可以多多关注。
GPT比ELMO明智的一点就是使用Transformer作为特征抽取器。但是GPT在使用词上下文这块有些欠缺,GPT仅仅使用了词的上文来动态表示Word Embedding,这样就完全没有用到下文有用的信息。从以后的发展趋势来看,这并不是一个好主意。
所以针对GPT的归纳总结也是两点:一方面使用Transformer作为特征抽取器,另一方面仅仅使用词的上文来表示Word Embedding。
5. BERT
最后终于到了咱们的巨星BERT模型了。BERT和ELMO、GPT有密切关系。先上一张BERT模型的结构图:
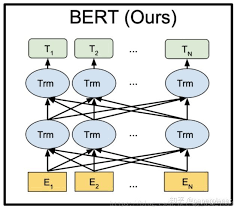 图6 BERT结构图
图6 BERT结构图
从BERT结构图可以看出和ELMO、GPT之间的关系。BERT使用了Transformer作为特征抽取器,并且同时使用了上下文来表示。这里BERT使用的上下文和ELMO有不同之处,ELMO是分别看上文和下文,然后将上文得到的结果和下文得到的结果进行拼接。而BERT是同时看上下文中的每个词,效果上也比ELMO要好。
可能小伙伴会有点迷,我画个图说明下:
 图 7 BERT和ELMO的上下文不同之处
图 7 BERT和ELMO的上下文不同之处
来张全家图看看Word2Vec、ELMO、GPT和BERT的关系吧:
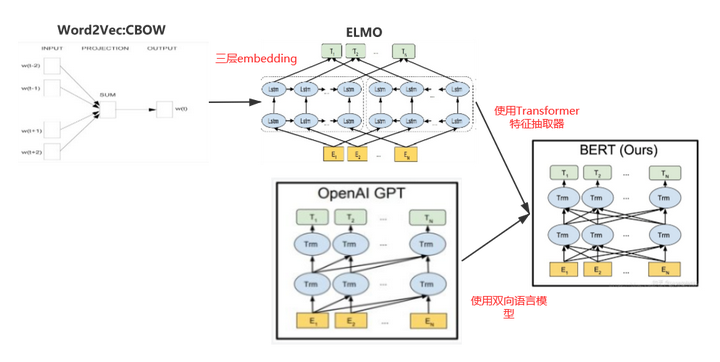 图8 Word2Vec、ELMO、GPT和BERT之间的关系
图8 Word2Vec、ELMO、GPT和BERT之间的关系
从图8咱们查看Word2Vec、ELMO、GPT和BERT之间的关系进行总结:Word2Vec是静态的Word Embedding,所以无法解决多义词问题。而ELMO是动态的Word Embedding。ELMO相比于Word2Vec使用词向量、句法特征向量和语义特征向量三层embedding组合来表示词,主要的特点是使用LSTM作为特征抽取器,同时使用上下文共同来进行词编码。如果将ELMO中的LSTM换成Transformer,那么就变成了BERT的结构。而GPT的特点是使用了Transformer作为特征抽取器,但是仅仅使用了上文。所以如果GPT同时使用上下文那么也就变成了BERT的结构。
BERT集百家之长,同时使用了Transformer作为特征抽取器,还使用了上下文共同来表示词,所以是集大成者。而BERT的效果也是极其出色的。BERT在11个NLP任务重效果有很大的提升。
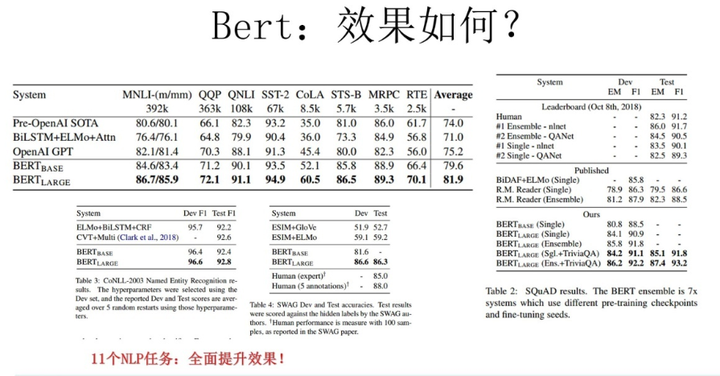 图9 BERT效果图
图9 BERT效果图
03 微调及BERT改造
上面从预训练的角度讲解了各大模型。现在从第二个阶段微调来分析模型。
ELMO、GPT和BERT都是两阶段模型。ELMO第二阶段将三层embedding根据不同的权重组合成一层embedding,每层的权重可以通过模型学习得到。ELMO将组合得到的embedding作为特征提供给上游任务使用。所以这里对ELMO提供给上游的网络结构没有要求。
GPT则不同,GPT主要通过微调的方式来支持上游任务。也就是说要求上游任务和GPT的网络结构是一样的。对接上游任务的时候通过不断微调网络参数以适应当前任务。
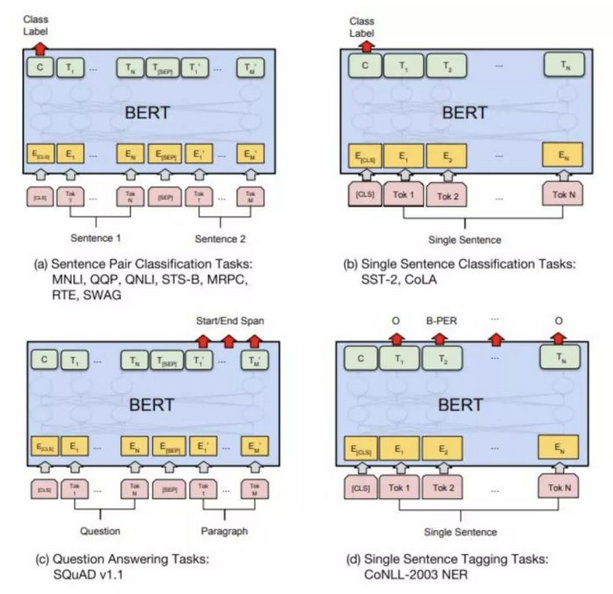 图10 BERT改造适应上游任务
图10 BERT改造适应上游任务
BERT同时支持特征补充和微调的方式来对接上游任务。一般选择微调的方式。之前说过,BERT不仅效果好,而且通用性很强。针对不同类型的NLP任务,如何改造BERT从而对接上游任务呢?
BERT论文中有详细说明。对于句子关系类任务,输入部分只需要在句子开始和结束的地方加上特殊的符号,句子之间加上分隔符即可完成改造。而模型输出的部分则需要把第一个起始符号对应的Transformer最后一层添加一个softmax进行分类即可。句子分类任务和句子关系类任务类似。对于序列标注任务来说,输入和句子关系类任务一样,输出则在每个单词后面都进行分类。通过图10可以看出我们可以很容易的改造BERT模型从而去完成各种类型的NLP任务。
04 BERT的创新之处
BERT主要提出了Masked LM和Next Sentence Prediction。
1. Masked LM
之前说过虽然BERT和ELMO都使用了上下文,但是上下文的方式不同。ELMO是构建了左右两个双层LSTM结构分别来理解上文和下文,而BERT则同时理解上下文。
为了训练这样一个可以同时理解上下文的深度双向表示网络,google团队使用了一种随机屏蔽的语言模型Masked LM。
Masked LM是这样做的。首先随机屏蔽每个序列中15%的词,然后类似完形填空那样的操作使用语言模型去预测这15%的词。这样虽然能得到双向预训练模型,但是存在两个问题:
第一个问题,预训练阶段随机屏蔽序列中15%的词,但是在Fine Tuning阶段并不会这么做,这样会导致两阶段间不匹配。为了解决这个问题,google团队会将这15%需要Mask的词再进行划分。其中的80%真正用Mask去屏蔽,比如"I love machine learning"换成"I love [Mask] learning"。还有10%是随机的转化成其他的词,比如"I love machine learning"换成"I love app learning"。最后那10%保持不变。
通过这样的操作模型不知道要预测哪些词,也不知道哪些词被替换了。这样模型就会被迫去学习每个词的上下文表示。
第二个缺点是Masked LM的收敛速度比单向语言模型慢。主要原因是每个batch只预测15%的词,模型可能需要更多的步骤才能收敛。
虽然如此,但是Masked LM模型的效果提升远远超过训练的成本。
2. Next Sentence Prediction
NLP中很多任务需要理解两个句子之间的关系,比如问答任务和自然语言推理任务。
为了使模型能够理解两个句子之间的关系,BERT在选择语料时,会选择句子A和句子B作为训练样本。其中B有50%的可能是A的下一句,还有50%的可能是随机选择的。
通过这种操作实现了Next Sentence Prediction。
3. BERT有效因子分析
BERT在预训练中,Masked LM和Next Sentence Prediction是同时进行训练的。那么到底这两种创新策略对于最终模型的效果有什么影响?
 图11 BERT有效因子分析
图11 BERT有效因子分析
通过实验发现,Masked LM对模型的效果作用很大,而Next Sentence Prediction则对个别任务有明显影响。
总结和预告
本篇从理论的角度分析了下BERT这种预训练+Fine Tuning的两阶段模型。预训练主要回顾了下Word Embedding的历史,从静态的Word2Vec到动态的ELMO、GPT,再到我们的巨星BERT模型。可以看出BERT是NLP领域近几年重大成果的集大成者。也分析了下在Fine Tuning阶段如何将BERT模型改造成多种多样的NLP任务。最后分析了下BERT的两个创新点Masked LM和Next Sentence Prediction。通过这一篇分享小伙伴们可以对BERT模型的前世今生有个大致的了解,也能方便我们更好的使用BERT模型去完成业务开发。
其中埋下了一个伏笔,我们说BERT模型效果很好的一个重要原因是使用了Transformer作为特征抽取器。那么这个Transformer为啥这么牛?下一篇广告系列就和小伙伴们一起来看一看这个Transformer的神奇之处。
回顾下历史
如果对广告感兴趣的小伙伴建议看看我广告系列的第一篇文章:广告中那些趣事系列1:广告统一兴趣建模流程。第一篇文章对于理解广告以及我们标签团队所做的事情和业务本身至关重要。再牛逼的技术也需要去支撑业务才有价值和意义。
对BERT文本分类感兴趣的小伙伴们可以看下我的第二篇文章:广告行业中那些趣事系列2:BERT实战NLP文本分类任务(附github源码)。第二篇从项目实战的角度指导小伙伴们用BERT模型去完成一个文本分类的项目。
喜欢本类型文章的小伙伴可以关注我的微信公众号:数据拾光者。有任何干货我会首先发布在微信公众号,还会同步在知乎、头条、简书、csdn等平台。也欢迎小伙伴多交流。如果有问题,可以在微信公众号随时Q我哈。

标签:learning inf 因子 团队 机器 abd 组合 结构 引入
原文地址:https://www.cnblogs.com/wilson0068/p/12388931.html