标签:extc 设计 code targe 表单 neu chat att 向量空间

摘要:上一篇广告行业中那些趣事系列3:NLP中的巨星BERT,从理论的角度讲了下NLP中有里程碑意义的BERT模型。BERT具有效果好和通用性强两大优点,其中效果好最主要的原因就是使用了Transformer作为特征抽取器。本篇主要详解下这个从配角到C位出道的Transformer,主要从宏观和微观的角度分析Transformer,讲下它的核心注意力机制Attention,然后以翻译任务举例讲下Transformer是如何进行工作的。
对充满挑战的高薪行业NLP感兴趣的小伙伴可以多多关注。不仅仅是技术,大家也可以了解到身边的翻译任务、对话机器人是怎么做出来的。
目录
01 BERT和Transformer的关系
02 为什么要用Transformer
03 从宏观视角看Transformer
04 从微观视角看Transformer
01 BERT和Transformer的关系
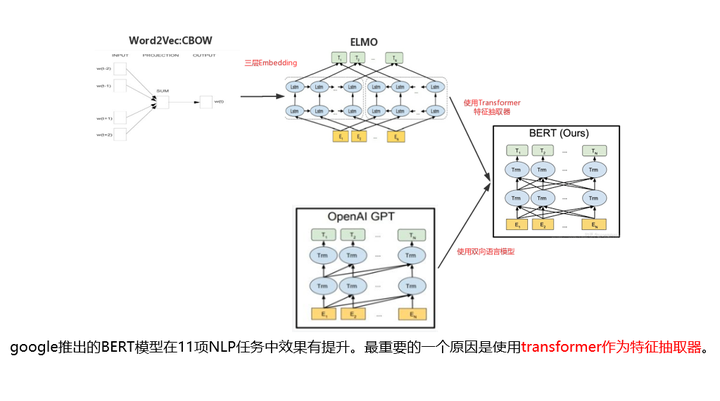 图1 回顾Word Embedding的演化历史
图1 回顾Word Embedding的演化历史
这里作为引言回顾下NLP中预训练技术Word Embedding的演化历史:
Word2vec将文本映射到向量空间,从而实现了在低维向量空间表示文本。通过向量空间中距离的长短可以表示文本语义的相似度。但是因为一个词在向量空间中位置是唯一的,所以无法解决多义词的问题。比如”legend”既可以代表传奇,还可以代表图例。归根结底是静态的Word Embedding。
ELMO采用联系上下文的三层embedding来表示词,不仅包括词向量,还包括了句法特征向量和语义特征向量,很好的解决了多义词问题。
而目前项目中使用的BERT模型相比于ELMO,因为使用了Transformer作为特征抽取器,所以模型效果很好。
总结下,google推出的BERT模型在11项NLP任务中效果有很大提升。最重要的一个原因是使用Transformer作为特征抽取器。
02 为什么要用Transformer
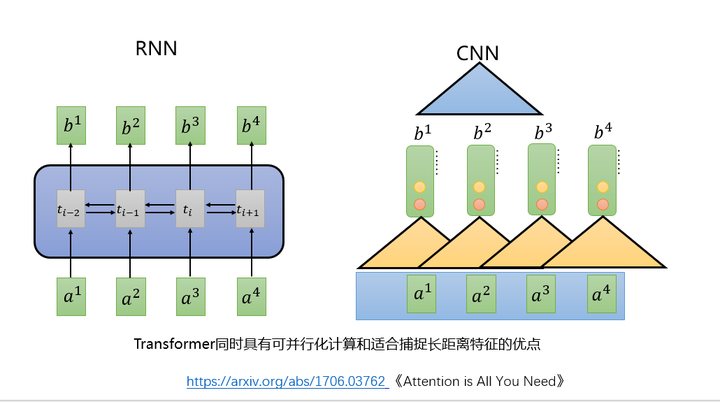 图2 传统的特征抽取器RNN和CNN
图2 传统的特征抽取器RNN和CNN
NLP中传统的特征器主要是RNN和CNN。
RNN(或者变种LSTM、GRU等)由于本身的机制只能按顺序依次计算,这种机制存在两个问题:
CNN虽然可以并行化计算,但是不适合捕捉长距离特征。
因为RNN和CNN各自存在的问题,所以google团队在论文《Attention is All You Need》中提出了Transformer模型。中文的意思是变形金刚,听着就很霸气。

Transformer抛弃了传统的CNN和RNN,整个网络完全由Attention机制组成,同时具有可并行化计算和捕捉长距离特征的优点。
03 从宏观视角看Transformer
1. Transformer的组成
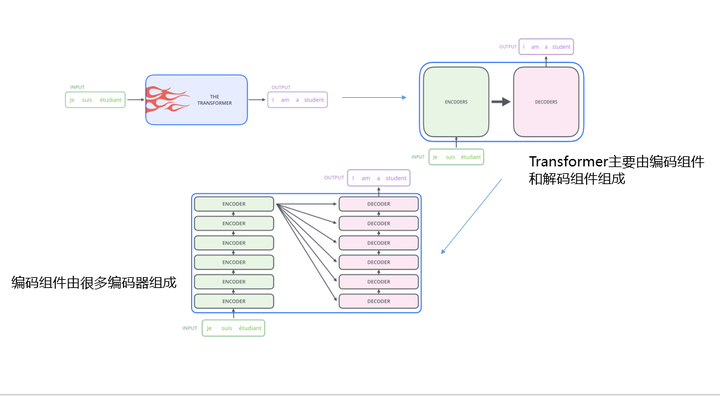 图3 从宏观视角看Transformer
图3 从宏观视角看Transformer
拿翻译系统举例,我们输入一种语言,通过Transformer模型,输出是另外一种语言。
进一步剖析Transformer模型,主要有编码组件和解码组件组成。编码组件中包含很多个编码器,解码组件也包含很多个解码器。
2. 编码器和解码器结构
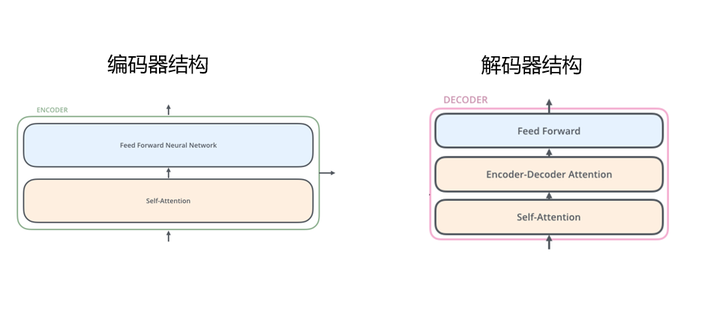 图4 编码器和解码器结构
图4 编码器和解码器结构
编码器主要包含自注意力层(Self-Attention)和前馈神经网络层(Feed Forward Neural Network)。
解码器和编码器很相似,也包含自注意力层和前馈神经网络层,另外还有一层编码解码层(Encoder-Decoder Attention)。
小结下,我们从宏观视角了解了Transformer的结构。Transformer主要包含编码组件和解码组件,编码组件中又包含很多编码器,解码组件同理。编码器中主要有自注意力层和前向神经网络层,解码器相比于编码器多了编码解码层。总体来说还是比较容易理解。
04 从微观视角看Transformer
1. 从张量计算查看Transformer内部转化流程
大部分NLP任务首先需要将语料转化成词向量的表征形式x。
对于编码组件来说,底层的编码器作为整个Transformer的入口,接收词向量作为模型输入。
这里咱们通过具体输入输出的维度表示来方便小伙伴们更好的理解Transformer中的各个环节。我们假设词向量的维度为512维。这里的512是可以设置的参数,一般是训练集中最长句子的长度。
因为编码组件中所有编码器的输入维度是相同的,初始的词向量是1X512维,那么底层的编码器的输入是1X512维,所以其他的编码器的输入也是1X512维。编码器内部会依次经过自注意力层和前馈神经网络层。
低层编码器的输出会作为上一层编码器的输入,不断进行,直到穿过整个编码组件。比如图5中编码器1的输入是词向量,编码器2的输入是编码器1的输出。编码器内部转化流程和编码器之间的转化流程如下图所示:
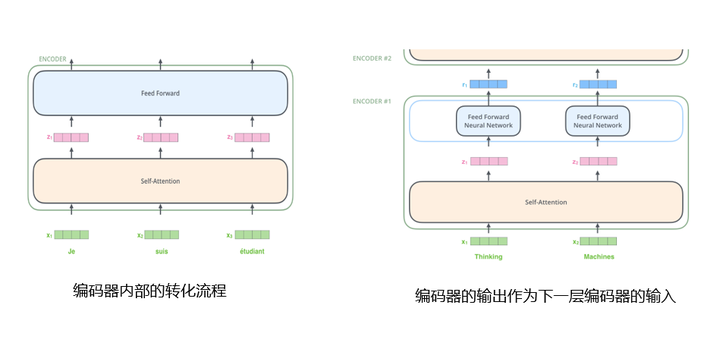 图5 编码器内部以及之间的转化流程
图5 编码器内部以及之间的转化流程2. 查看自注意力层的计算流程
Transformer中最重要的就是这个自注意力机制Self-Attention。Self-Attention主要用于计算当前词对所有词的注意力得分,整个流程如下:
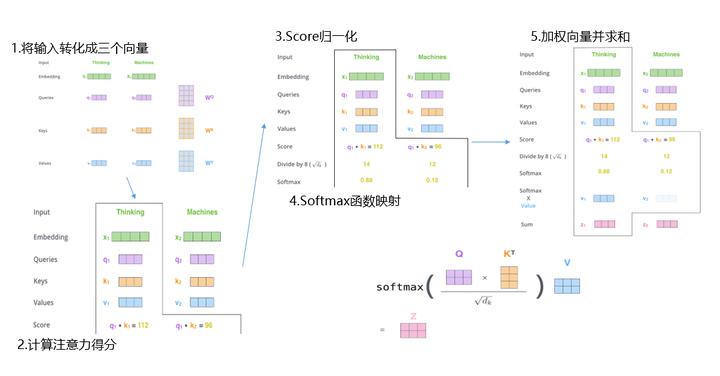 图6 计算注意力得分整个流程
图6 计算注意力得分整个流程这里通过计算词"thinking"的注意力得分举例,详细分析步骤如下:
(1) 将编码器的输入x转化成三个向量
通过词向量x(1X512)和三个不同的权值矩阵????、????、????相乘得到查询向量Q(1X64)、键向量K(1X64)和值向量V(1X64)。
小伙伴们可能有疑问了,这三个权值矩阵怎么得到的?
模型刚开始训练的时候,这三个权值矩阵参数可能是随机的。等模型训练完成之后,就得到训练好的权值矩阵的参数了。这三个权重矩阵的维度都是512X64维。
其中512是因为一开始我们设置词向量的维度是1X512,那64怎么来的?这里涉及到Transformer的多头注意力机制,先埋个坑,后面填。
(2) 计算当前词对所有词的注意力得分
比如我们计算"thinking"的注意力得分。将"thinking"的查询向量q1分别和所有词的ki点积相乘得到一个得分score。这个得分代表当前词对其他词的注意力。
(3) score归一化和softmax函数映射
使用score归一化的目的是为了梯度稳定,分别将score除以键向量维度的算术平方根(论文中默认为8)。然后通过一个softmax函数将得分映射为0-1之间的实数,并且归一化保证和为1。
(4) 计算最终的注意力得分
计算softmax值和值向量v1相乘得到加权向量,然后求和得到z1为最终的自注意力向量值。目的是保持相关词的完整性,同时可以将数值极小的不相关的词删除。
上述整个流程就是通过张量计算展示自注意力层是如何计算注意力得分的。整体公式如下所示:
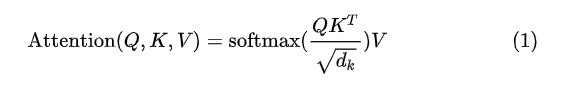
3. 多头注意力机制
多头注意力机制相当于多个不同的注意力的集成(ensemble)。更通俗的理解是将上面Attention层“重复多次“,但是这里不仅仅是简单的重复多次。
多头注意力机制主要从以下两个方面进一步完善注意力层:
Transformer默认使用8个注意力头。这样每个编码器就能得到8个矩阵。论文默认使用的是8个头,可调。
因为每个初始的权重矩阵都是随机初始化的,所以经过模型训练之后将被投影到不同的表示子空间中。多头注意力机制如下图所示:
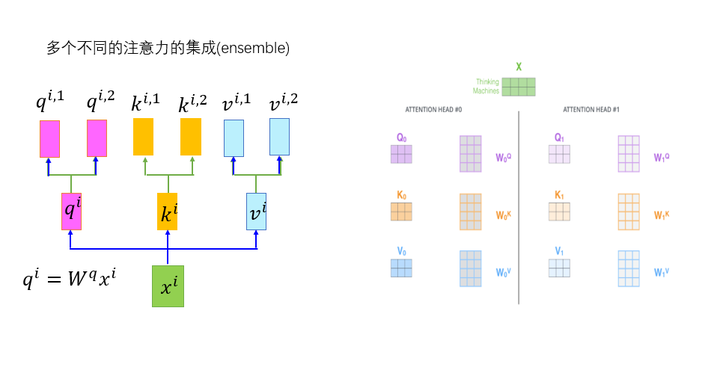 图8 多头注意力机制
图8 多头注意力机制
下面通过可视化的方式查看多头注意力机制:
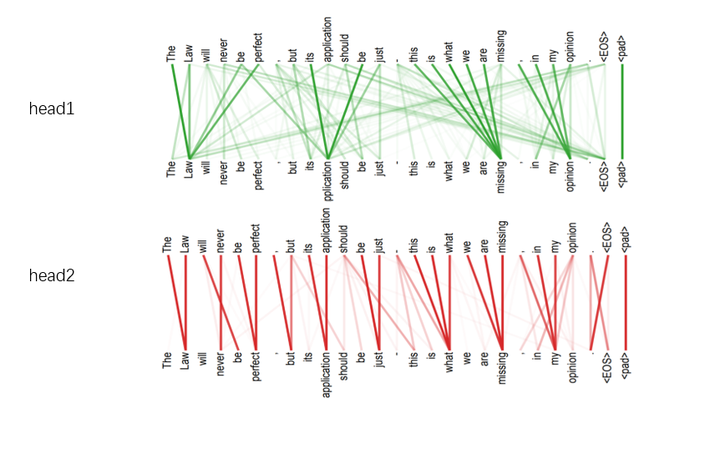 图9 多头注意力机制可视化
图9 多头注意力机制可视化图9中分别有两个头head1和head2,通过是否有连线以及颜色深浅我们可以查看当前词对所有词的注意力得分。head1得到的注意力矩阵更多的关注距离较远的词,head2则关注的是距离较近的词。可以看出不同的头关注的点是不同的。
现在出现一个新的问题:编码器中从自注意力层到前馈神经网络层过程中,前馈神经网络仅需要一个矩阵。现在因为多头注意力机制,出现了八个头。如何将这八个头压缩成一个头?
Transformer的解决策略是先将8个矩阵拼接起来,然后再和一个附加的权重矩阵W0相乘。这里可以简单的理解成通过一个全连接层来转化输出维度。其中权重矩阵W0和前面讲的权值矩阵Q、K、V都是通过模型训练得到的。
 图10 多头注意力机制合并多头策略
图10 多头注意力机制合并多头策略查看维度,比如z1是1X64,那么8个矩阵拼接起来就是1X(64*8)变成了1X512维。
这个额外的权值矩阵W0的维度是512X512,这样通过多头机制的自注意力层最终得到的矩阵维度就是1X512了。通过前馈神经网络之后还是1X512维,那么编码器的输入和输出则都是1X512维。
到这里为止,我们可以把前面的坑埋上了。为什么我们的Q、K、V权重矩阵的维度是512X64。512是因为词向量的维度是512维,而64就是因为论文中默认使用的是八头注意力机制。将8个头的注意力矩阵压缩成一个,所以这里是64维。
总结下多头注意力机制的整个流程:首先输入原始的语句;然后转化为词向量的矩阵形式;接着通过多头注意力得到多个查询/键/值向量;然后按照上面计算注意力的过程分别计算注意力矩阵;最后将多头注意力矩阵压缩为一个矩阵。大功告成!多头注意力机制整个流程如下图所示:
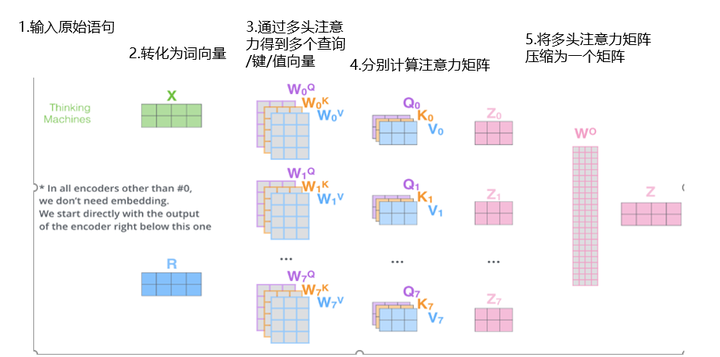 图11 多头注意力机制整个流程
图11 多头注意力机制整个流程
4. 位置编码
上述流程中缺少词位置的信息,导致的结果就是无论句子结构怎么打乱,Transformer得到的结果类似。也就是说,Transformer并没有捕捉顺序序列的能力,仅仅是一个功能强大的“词袋”模型。
为了解决这个问题,Transformer为每个词向量增加了一个表征词位置以及词之间距离的向量。这样计算自注意力的时候模型就会加入有用的位置信息了。
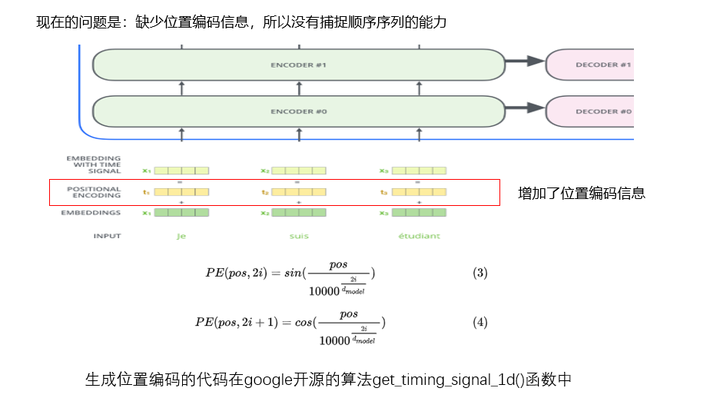 图12 位置编码
图12 位置编码
下面是论文中关于计算位置编码的公式:
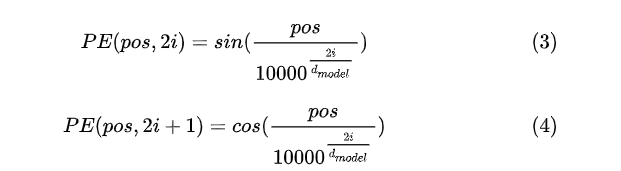
其中pos代表单词的位置,i表示词的维度。
生成位置编码的代码在google开源的算法get_timing_signal_1d()函数中
作者这么设计的原因是,在NLP任务中词的绝对位置很重要(比如通常一篇文章中首尾段落可能包含更多的信息),词的相对位置也很重要。通过上述公式可以体现Transformer更加关注相对位置。
5. 残差模块
编码器内部子层还采用残差网络,主要是为了解决深度学习中的退化问题。每个子层之后都连接一个残差网络,进行求和归一化步骤。比如自注意力层后的残差网络会将自注意力层的输入x和输出z相加,然后进行normalize归一化。
编码器内部的残差网络和可视化如下图:
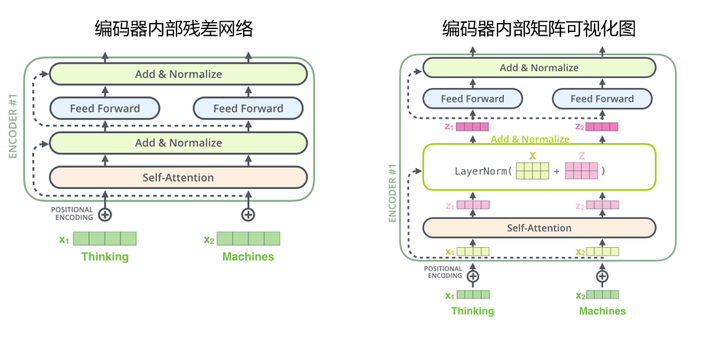 图13 残差模块
图13 残差模块6. Attention可视化
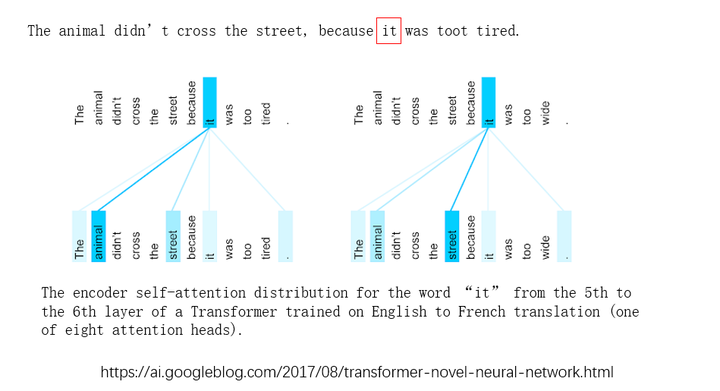 图14 Attention可视化
图14 Attention可视化
图14通过一个简单的例子看下Attention机制有多强大。现在我们想翻译一句话:"The animaldidn’t cross the street, because it was toot tired"。
我们想知道"it"到底是啥意思?对于人类而言,我们很容易知道"it"代表上面的"animal"(在一些复杂的段落中可能对于我们人类也是很难的任务,类比小时候英语试题中某些完形填空题)。对于机器来说,完全就是下面这个黑人小哥的表情了。
Attention机制可以很好的理解"it"并找到最可能代表"it"的这个词"animal"。图中有两个表示注意力矩阵的可视化图,每个可视化图表示的是上面一行的每个词对下面一行所有词的注意力,有连线则表示当前词对其他词有关注,线的颜色越深则代表关注度越高。可以看出当前词"it"同时对"the"、" animal"、" street"、"it"和句号都有关注度,但是对"animal"的关注度是最高的,所以"it"词最终就代表"animal"。
有意思的是,如果我们修改语句,将其中的"tired"改成"wide",奇迹出了,Attention能很好的识别到"it"代表的是"street"。
下图展示一个完整的双层编码-解码器的Transformer结构:
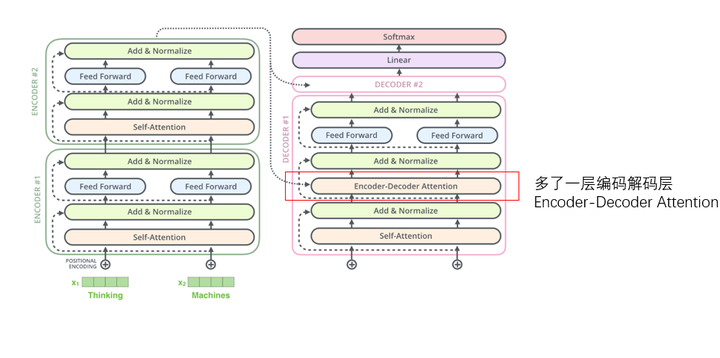 图15 一个完整的双层编码-解码器的Transformer结构
图15 一个完整的双层编码-解码器的Transformer结构解码器和编码器大致相同,区别在于解码器中多了一层编码解码层(encoder-decoderAttention)。编码组件的输入是词向量,输出是最顶层的编码器输出的K、V注意力向量集。这些K、V注意力向量集会分别进入解码组件中各个解码器的编码解码层。解码器中其他的自注意力层和前向神经网络层和编码器是一样的。
编码器和解码器工作流程动图如下所示:
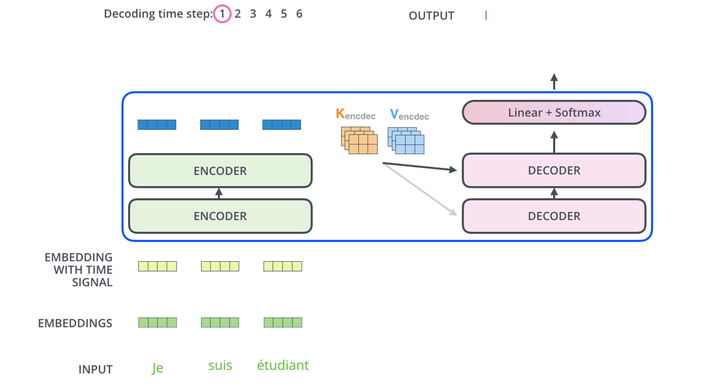 图16 编码器和解码器整个流程动图
图16 编码器和解码器整个流程动图
这里需要注意的是解码器第一轮的输入是一个特殊的开始标志符号,使用编码组件输出的K、V注意力向量集,输出是需要翻译的第一个词。
整个德语翻译成英语流程动图如下所示:
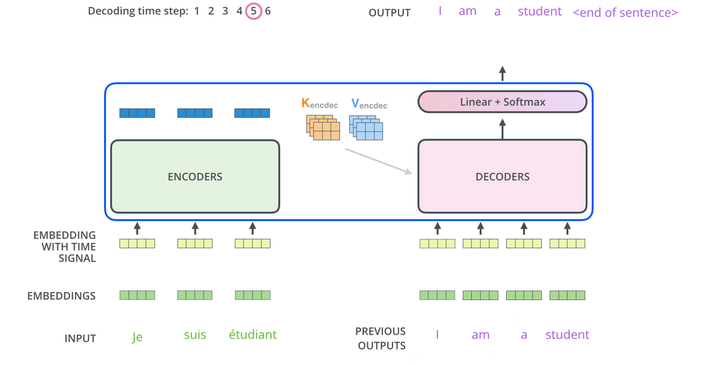 图17 整个德语翻译成英语流程动图
图17 整个德语翻译成英语流程动图
咱们详细讲解下德语翻译成英语的流程:编码流程上面讲的很详细,不再赘述。编码组件完成编码后,会将得到的K、V注意力向量集合分别传递给解码组件中各个解码器的编码解码层。
解码阶段开始,第一轮输入是一个特殊的开始符号,使用编码组件输出的K和V注意力向量集合,输出是翻译的第一个单词。第二轮的输入是第一轮输出的单词,输出翻译的第二个单词。第三轮的输入是前两轮输出的单词,输出翻译的第三个单词。依次类推,每次输入都是之前输出的所有单词,输出是翻译的一个单词。直到出现一个特殊的结束符号告诉Transformer解码器已经完成输出。
当时分享的时候有个小伙伴问了一个问题,Transformer如何做到神奇的完成翻译流程并且知道何时停止?这里我理解翻译任务应该是一个多词对多词的流程,和通常的输入输出长度相同的S2S可能不同。这里的输入和输出长度是不同的,翻译流程应该是分成两步,先找到目标语言需要的所有词,然后选择最符合人类表达方式的顺序输出。因为没有做过翻译系统,所以这里仅是猜测。
有点小遗憾,本来图16和图17是动图,但是不管咋弄到上面就成静态的。求助小伙伴如何在公众号插入动图的。
总结
本篇从宏观和微观视角讲了下Transformer,重头戏在Attention机制。因为Transformer具备并行性好和适合捕捉长距离特征的优点,所以成为NLP中主流的特征抽取器,从配角慢慢C位出道。BERT模型大火的背后则是Transformer的高调付出。可以说想学好BERT,必须要搞懂Transformer。
参考资料
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [C],Advancesin Neural Information ProcessingSystems. 2017: 5998-6008.
[2] http://jalammar.github.io/illustrated-Transformer/
[3] https://www.youtube.com/watch?v=ugWDIIOHtPA,台大李宏毅,Transformer
[4] https://ai.googleblog.com/2017/08/Transformer-novel-neural-network.html
[5] https://colab.research.google.com/github/tensorflow/tensor2tensor/blob/
master/tensor2tensor/notebooks/hello_t2t.ipynb#scrollTo=EB4MP7_y_SuQ
特别说明:本次分享主要参考的是《Attention is all you need》论文。因为论文比较高深难懂,所以仅通过论文不能很好的理解其中的精华。幸好国外有篇jalammar大神分享的可视化Transformer文章。深度好文,点赞!喜欢的朋友也可以直接通过参考资料[2]欣赏大作。这里也参考了台大李宏毅关于Transformer的讲解。有兴趣的小伙伴可以通过B站查看。
回顾下广告系列
广告行业中那些趣事系列2:BERT实战NLP文本分类任务(附github源码)
喜欢本类型文章的小伙伴可以关注我的微信公众号:数据拾光者。有任何干货我会首先发布在微信公众号,还会同步在知乎、头条、简书、csdn等平台。也欢迎小伙伴多交流。如果有问题,可以在微信公众号随时Q我哈。

广告行业中那些趣事系列4:详解从配角到C位出道的Transformer
标签:extc 设计 code targe 表单 neu chat att 向量空间
原文地址:https://www.cnblogs.com/wilson0068/p/12388950.html