标签:不一致 com data png version log nbsp 数据 删除
格式化NameNode会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往数据,所以,格式化NameNode前,先关闭掉NameNode和DataNode,然后一定要删除data数据和log日志。最后再进行格式化。
在hadoop-2.9.2/data/tmp/dfs/name/current/VERSION中可查到NameNode标识id
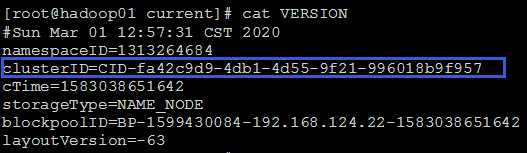
在hadoop-2.9.2/data/tmp/dfs/data/current/VERSION中可查到DataNode标识id
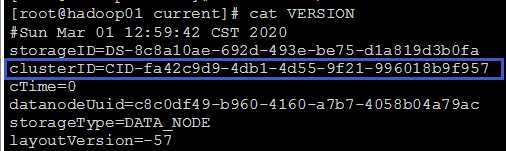
可以看出它们的集群Id是要保持一致的。
标签:不一致 com data png version log nbsp 数据 删除
原文地址:https://www.cnblogs.com/xiximayou/p/12389451.html