标签:没有 数据保存 消息 集群 顺序 bean 步骤 code 数据丢失
为了避免MQ服务器意外宕机导致数据丢失,需要做到重启后没有被消费的数据依然在消息队列中。
1. JDBC:持久化到数据库
2. AMQ:日志文件
3. KahaBD:AMQ基础上改进,默认选择
4. LevelDB:谷歌K/V数据库
注:ActiveMQ默认是不开启持久化的。
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb"/>
</persistenceAdapter>
AMQ的性能改与JDBC的持久化机制,由于是在文件中追加写入消息,所以性能比较高。并且创建了消息主键索引和缓存索引机制以提升性能。
AMQ会为每一个Destination创建一个索引,若创建了大小的消息队列,则磁盘占用会非常大,所以由于索引文件比较大,当Broker崩溃后,重建所以速度比较慢。
producer.setDeliveryMode(DeliveryMode.PERSISTENT);
PERSISTENT:代表开启持久化
NON_PERSISTENT:代表不开启持久化
文件位置在conf目录下
<persistenceAdapter>
<!--第一次创建是createTablesOnStartup属性为true,之后创建完成后将属性该为false,一直为true的话,每次启动的时候都会创建新表 --> <jdbcPersistenceAdapter dataSource="#activemq-db" createTablesOnStartup="true" /> </persistenceAdapter>
由于JDBC持久话方式需要连接数据库,所以需要在ActiveMQ安装目录的lib目录下添加如下jar包:

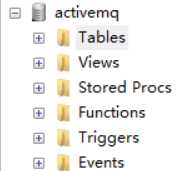
重启之后数据库中将会自动创建三张表
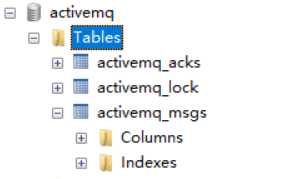
activemq_acks:用于存储订阅关系。如果是持久化Topic,订阅者和服务器的订阅关系在这个表保存。
主要的数据库字段如下:
CONTAINER:消息的Destination
SUB_DEST:如果是使用Static集群,这个字段会有集群其他系统的信息
CLIENT_ID:每个订阅者都必须有一个唯一的客户端ID用于区分
SUB_NAME:订阅者名称
SELECTOR:选择器,可以选择只消费满足条件的消息。条件可以用自定义属性实现,可支持多属性AND和OR操作
LAST_ACKED_ID:记录最后消费过的消息的ID
activemq_lock:在集群环境下才有用,只有一个Broker可以获得消息,称为Master Broker
activemq_msgs:用于存储消息,Queue和Topic都存储在这个表中;
主要的数据库字段如下:
CONTAINER:消息的Destination
MSGID_PROD:消息发送者客户端的主键
MSG_SEQ:是发送消息的顺序,MSGID+PROD+MSG_SEQ可以组成JMS的MessageID
EXPIRATION:消息的过期时间
MSG:消息本体的java序列化对象的二进制数据
PRIORITY:优先级,从0-9,数值越大优先级越高
启动生产者:
生产者发送完成,下面可以查看一下队列中的数据
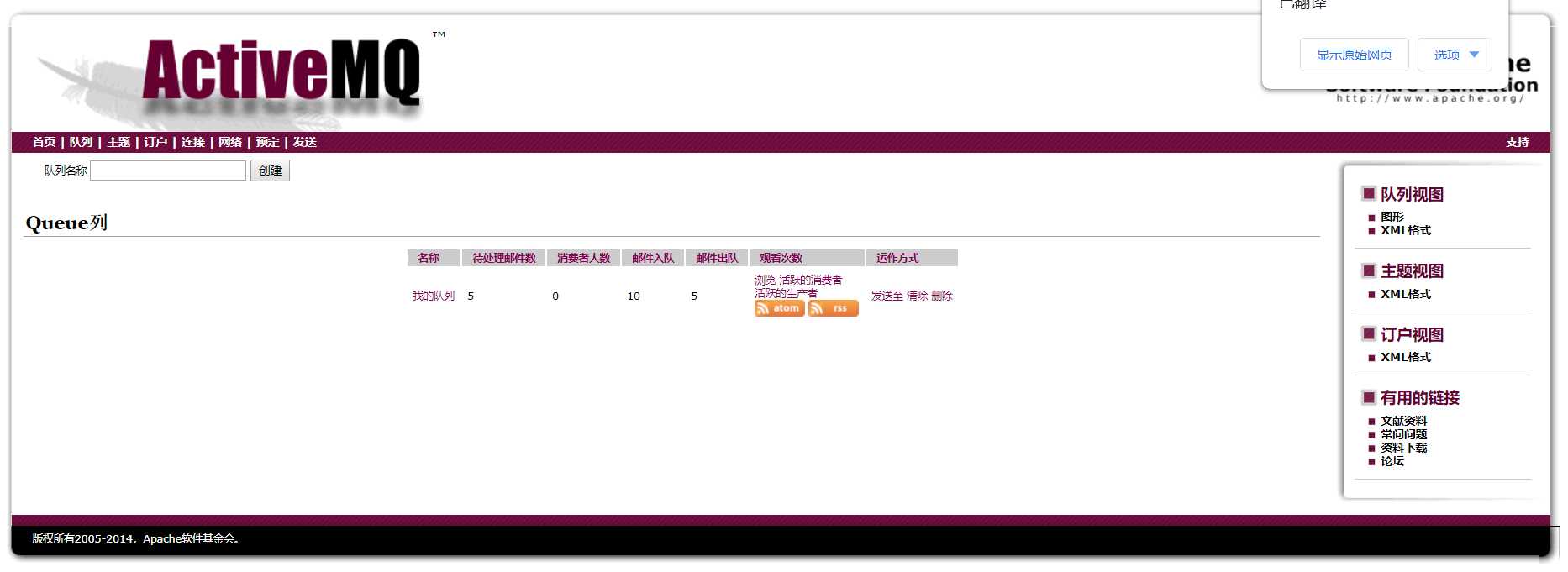
因为上面做配置将数据保存在数据库中,下面可以查看一下数据库中的数据

关闭ActiveMQ服务测试数据有没有真正的持久化
关闭之后页面时无法访问的;

关闭之后刷新数据库,数据依然存在,这是数据已经持久化了
启动ActiveMQ服务以及消费者:
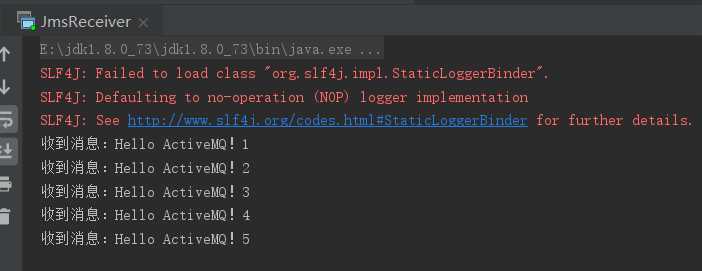
启动消费者时,数据已经成功接收到了
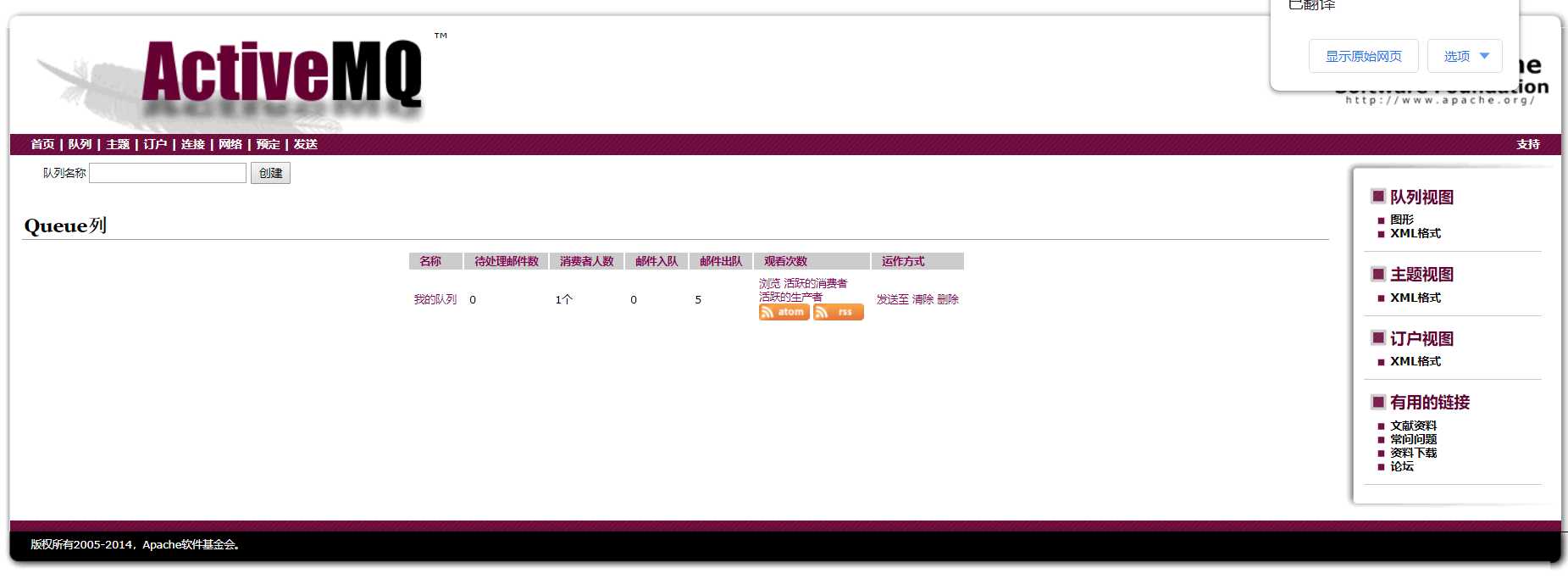
因为消费者已经接受到消息了,所以队列中的待处理数据就变成了0,并且现在的消费者是1;
下面可以查看一个数据库中的数据

由于消费者已经接受消息,队列中数据删除了,所以数据库中的数据也被删除了
结论:生产者就数据发送到队列中,如果不做持久化操作,ActiveMQ服务器宕机,数据就会清空;如果做了持久化操作,ActiveMQ服务器宕机之后再次启动,没有被消费者消费的消息就会一直在数据库中,等消费者消费完消息后,数据库中的数据才会被删除。
标签:没有 数据保存 消息 集群 顺序 bean 步骤 code 数据丢失
原文地址:https://www.cnblogs.com/mayuan01/p/12391361.html