标签:hql 处理 shm hdfs cat 信息 write 针对 调用
hive> create database hadoop;
hive> use hadoop;

数据库位置在 hdfs://ns1/user/hive/warehouse/hadoop.db目录下

hive> create table t_order(id int,name string,container string,price double) > row format delimited > fields terminated by ‘\t‘;
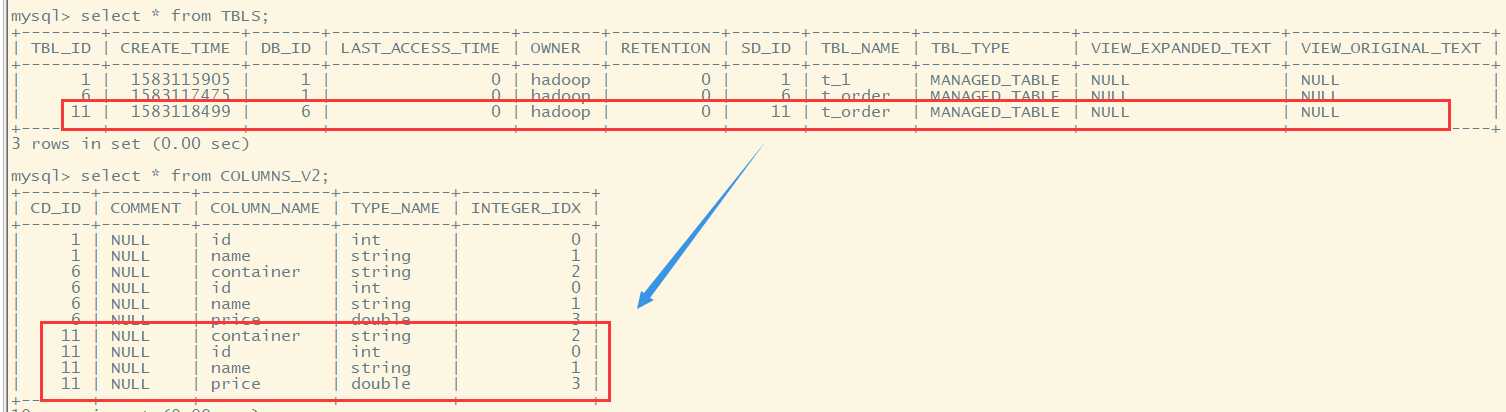
//array create table tab_array(a array<int>,b array<string>) row format delimited fields terminated by ‘\t‘ //使用\t分割字段 collection items terminated by ‘,‘; //使用,分割数组元素
select a[0] from tab_array; select * from tab_array where array_contains(b,‘word‘); insert into table tab_array select array(0),array(name,ip) from tab_ext t;
//map create table tab_map(name string,info map<string,string>) row format delimited fields terminated by ‘\t‘ //使用\t分割字段 collection items terminated by ‘,‘ //使用,分割map元素 map keys terminated by ‘:‘; //使用:分割每个map的key和value
load data local inpath ‘/home/hadoop/hivetemp/tab_map.txt‘ overwrite into table tab_map; insert into table tab_map select name,map(‘name‘,name,‘ip‘,ip) from tab_ext;
create table tab_struct(name string,info struct<age:int,tel:string,addr:string>) row format delimited fields terminated by ‘\t‘ collection items terminated by ‘,‘ load data local inpath ‘/home/hadoop/hivetemp/tab_st.txt‘ overwrite into table tab_struct; insert into table tab_struct select name,named_struct(‘age‘,id,‘tel‘,name,‘addr‘,country) from tab_ext;
[hadoop@hadoopH1 ~]$ cat order.txt 00001001 iphone5 32G 4999 00001002 iphone6S 128G 9999 00001003 xiaomi6x 32G 2999 00001004 honor 32G 3999
load data local inpath ‘/home/hadoop/order.txt‘ into table t_order;

实际是拷贝数据到hdfs文件系统中。

[hadoop@hadoopH1 ~]$ cat order_1.txt 00002001 redmi 32G 3999 00002002 geli 128G 1999 00002003 xiami6x 32G 999 00002004 huawei 32G 3999

load data local inpath ‘/home/hadoop/ip.txt‘ into table tab_ext;
load data inpath ‘hdfs://ns1/aa/bb/data.log‘ into table tab_user;
insert overwrite table tab_ip_seq select * from tab_ext;
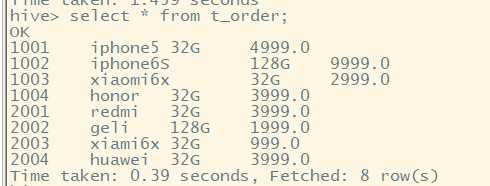
select * from t_order;
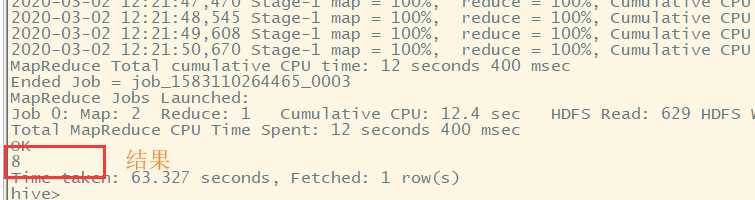
select count(*) from t_order;
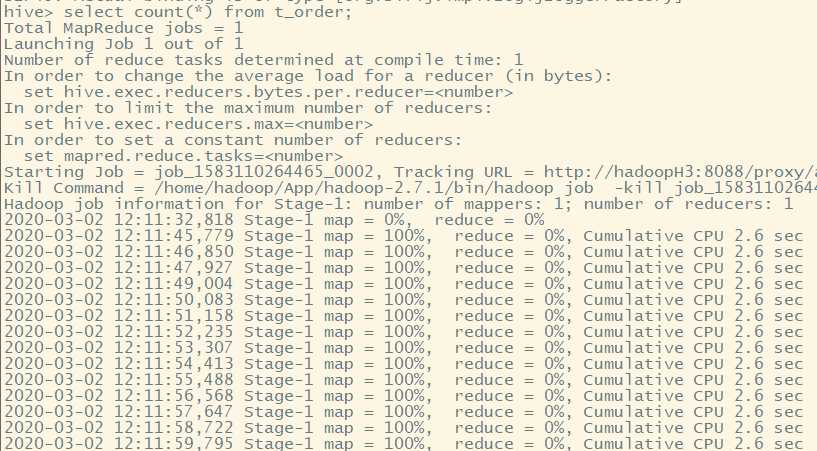
调用mapreduce程序进行数据处理。
CREATE EXTERNAL TABLE tab_ip_ext(id int, name string, ip STRING, country STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘ STORED AS TEXTFILE #数据表存储格式为TEXT文本 LOCATION ‘/external/user‘; #从hdfs中其他文件目录/external/user下引入数据

CREATE TABLE t_order_sel
AS
SELECT id new_id, name new_name, price new_price
FROM t_order
SORT BY new_id;


partition分区,可以使用建表字段,也可以使用其他字段。
建表使用partition进行分区,数据插入也需要指定分区进行存放
create table tab_ip_part(id int,name string,ip string,country string) partitioned by (year string) row format delimited fields terminated by ‘,‘;
load data local inpath ‘/home/hadoop/data.log‘ overwrite into table tab_ip_part partition(year=‘1990‘); load data local inpath ‘/home/hadoop/data2.log‘ overwrite into table tab_ip_part partition(year=‘2000‘);
实际:将数据加载再分区中,既是在表目录下新建一个分区目录,将数据放入该目录中。

show partitions tab_ip_part;
alter table tab_ip change id id_alter string; 修改字段
ALTER TABLE tab_cts ADD PARTITION (partCol = ‘dt‘) location ‘/external/hive/dt‘; 修改添加分区
create table tab_ip_cluster(id int,name string,ip string,country string) clustered by(id) into 3 buckets;
load data local inpath ‘/home/hadoop/ip.txt‘ overwrite into table tab_ip_cluster; set hive.enforce.bucketing=true; insert into table tab_ip_cluster select * from tab_ip;
select * from tab_ip_cluster tablesample(bucket 2 out of 3 on id);
hive -S -e ‘select country,count(*) from tab_ext‘ > /home/hadoop/hivetemp/e.txt
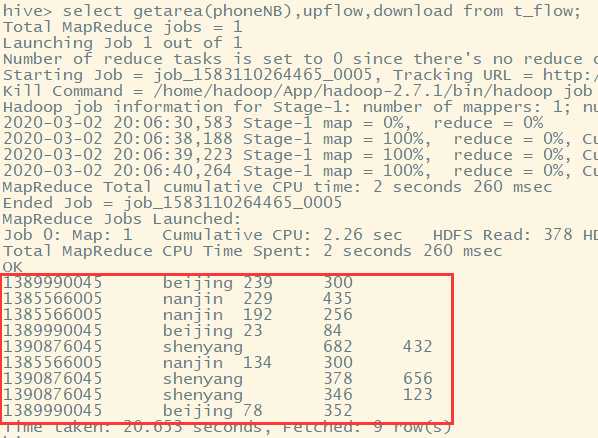
select getarea(phoneNB),upflow,downflow from t_flow
1389990045 239 300 1385566005 229 435 1385566005 192 256 1389990045 23 84 1390876045 682 432 1385566005 134 300 1390876045 378 656 1390876045 346 123 1389990045 78 352
1389990045 beijing 239 300 1385566005 nanjin 229 435 1385566005 nanjin 192 256 1389990045 beijing 23 84 1390876045 shenyang 682 432 1385566005 nanjin 134 300 1390876045 shenyang 378 656 1390876045 shenyang 346 123 1389990045 beijing 78 352
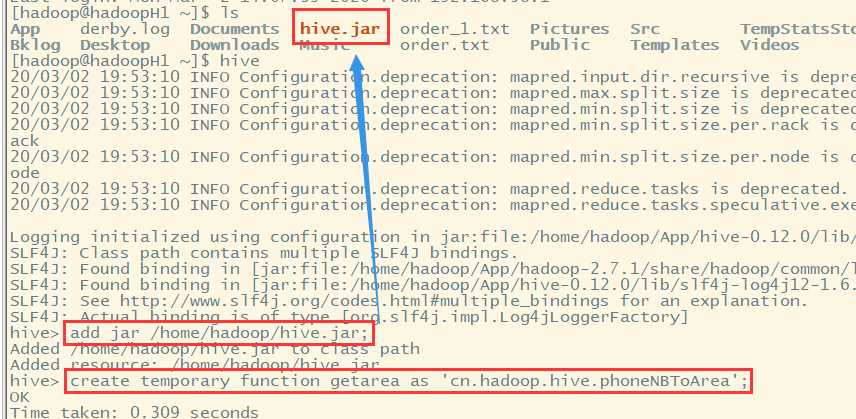
1.实现Java类,定义上述函数逻辑。转化为jar包,上传到hive的lib中
2.在hive中创建一个函数getarea,和jar包中的自定义java类建立关联
package cn.hadoop.hive; import java.util.HashMap; import org.apache.hadoop.hive.ql.exec.UDF; public class phoneNBToArea extends UDF{ public static HashMap<String,String> areamap = new HashMap<>(); static { areamap.put("1389", "beijing"); areamap.put("1385", "nanjin"); areamap.put("1390", "shenyang"); } public String evaluate(String phoneNB) { //需要重载该方法 String result = areamap.get(phoneNB.substring(0, 4))==null?(phoneNB+" nowhere"):(phoneNB+" "+areamap.get(phoneNB.substring(0, 4))); return result; } }
hive> add jar /home/hadoop/hive.jar; hive> create temporary function getarea as ‘cn.hadoop.hive.phoneNBToArea‘;
create table t_flow(phoneNB string,upflow int,download int) row format delimited fields terminated by ‘\t‘;
load data local inpath ‘/home/hadoop/flow.txt‘ into table t_flow;
select getarea(phoneNB),upflow,download from t_flow;
标签:hql 处理 shm hdfs cat 信息 write 针对 调用
原文地址:https://www.cnblogs.com/ssyfj/p/12394252.html