标签:park 数据处理 partition 均值 nump create 聚合操作 none png
combineByKey(createCombiner,
mergeValue,
mergeCombiners,
numPartitions=None,
partitionFunc=<function portable_hash at 0x7f1ac7340578>)
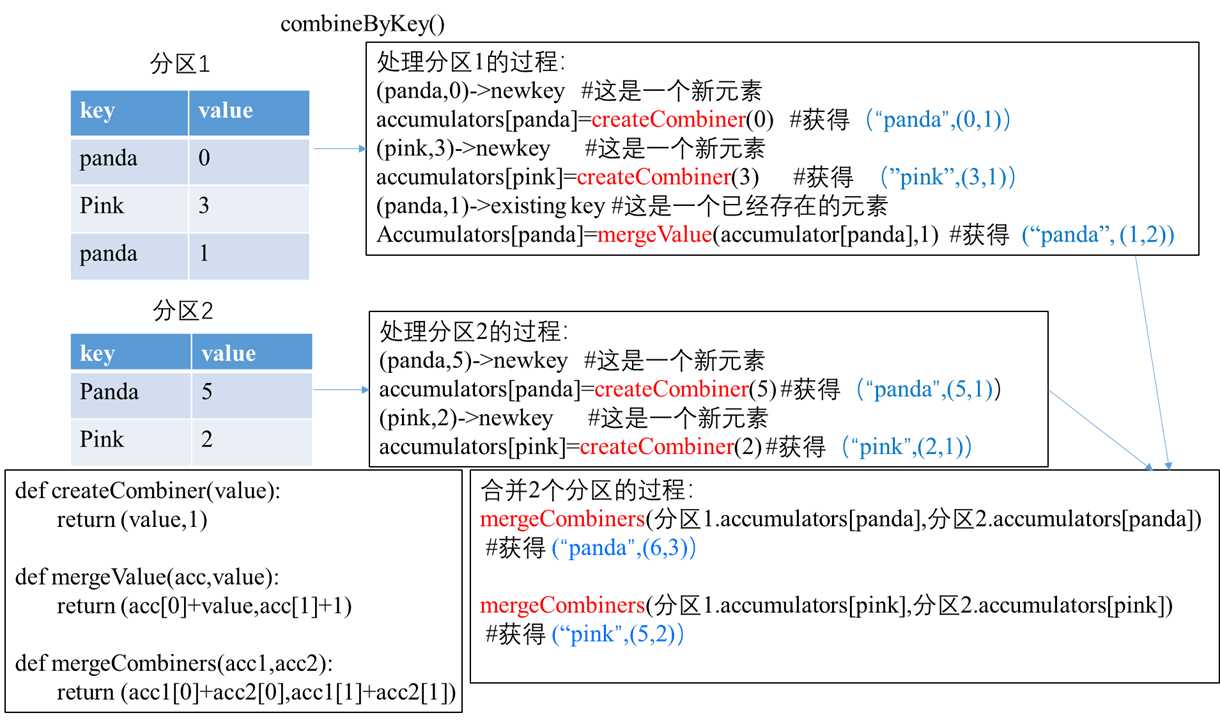
它是一个泛型函数,主要完成聚合操作,将输入RDD[(K,V)]转化为结果RDD[(K,C)]输出
乍一看,感觉有些难理解,我们来一起探索下! 加油
pair RDD是键值对RDD 也就是包含key和value
我们对这样的数据做分组、聚合操作其实是将类型为RDD[(K,V)]的数据处理为RDD[(K,C)]
这里的V和C可以是相同类型,也可以是不同类型
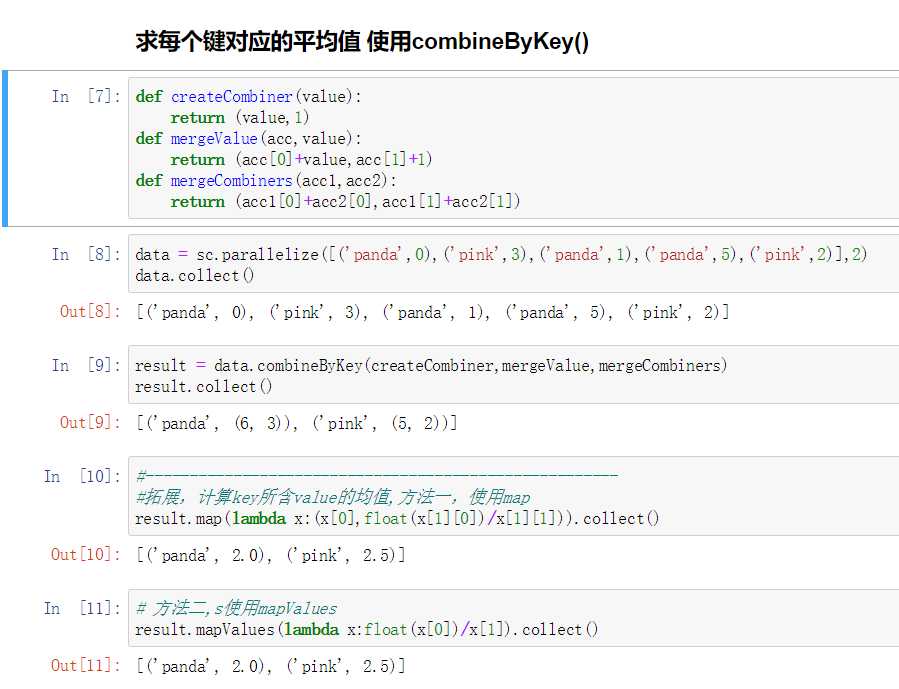
求每个键对应的平均值
具体的操作过程如下:
代码实现
标签:park 数据处理 partition 均值 nump create 聚合操作 none png
原文地址:https://www.cnblogs.com/ivyharding/p/12401435.html