标签:宕机 名称 code 字符串 -- 区分 分析 分配 遍历
-- 所谓的再平衡,指的是在kafka consumer所订阅的topic发生变化时发生的一种分区重分配机制。一般有三种情况会触发再平衡:

-- 关于Round Robin重分配策略,其主要采用的是一种轮询的方式分配所有的分区,该策略主要实现的步骤如下。这里我们首先假设有三个topic:t0、t1和t2,这三个topic拥有的分区数分别为1、2和3,那么总共有六个分区,这六个分区分别为:t0-0、t1-0、t1-1、t2-0、t2-1和t2-2。这里假设我们有三个consumer:C0、C1和C2,它们订阅情况为:C0订阅t0,C1订阅t0和t1,C2订阅t0、t1和t2。那么这些分区的分配步骤如下:
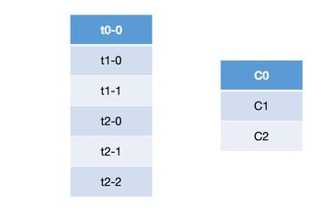
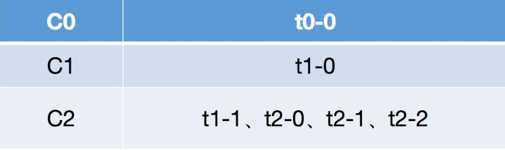
-- 从上面的步骤分析可以看出,轮询的策略就是简单的将所有的partition和consumer按照字典序进行排序之后,然后依次将partition分配给各个consumer,如果当前的consumer没有订阅当前的partition,那么就会轮询下一个consumer,直至最终将所有的分区都分配完毕。但是从上面的分配结果可以看出,轮询的方式会导致每个consumer所承载的分区数量不一致,从而导致各个consumer压力不均一。
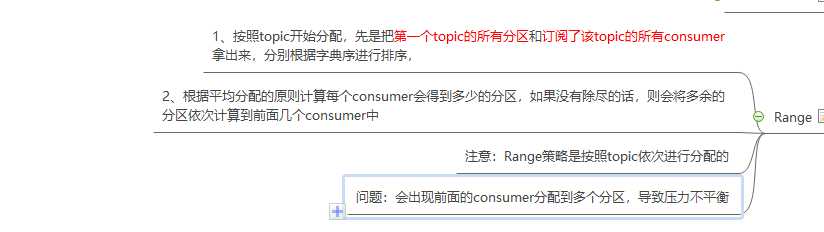
-- 所谓的Range重分配策略,就是首先会计算各个consumer将会承载的分区数量,然后将指定数量的分区分配给该consumer。这里我们假设有两个consumer:C0和C1,两个topic:t0和t1,这两个topic分别都有三个分区,那么总共的分区有六个:t0-0、t0-1、t0-2、t1-0、t1-1和t1-2。那么Range分配策略将会按照如下步骤进行分区的分配:
-- 最终上面六个分区的分配情况如下:

-- 可以看到,如果按照Range分区方式进行分配,其本质上是依次遍历每个topic,然后将这些topic的分区按照其所订阅的consumer数量进行平均的范围分配。这种方式从计算原理上就会导致排序在前面的consumer分配到更多的分区,从而导致各个consumer的压力不均衡。
-- Sticky策略是新版本中新增的策略,顾名思义,这种策略会保证再分配时已经分配过的分区尽量保证其能够继续由当前正在消费的consumer继续消费,当然,前提是每个consumer所分配的分区数量都大致相同,这样能够保证每个consumer消费压力比较均衡。关于这种分配方式的分配策略,我们分两种情况进行讲解,即初始状态的分配和某个consumer宕机时的分配情况

-- 初始状态分配的特点是,所有的分区都还未分配到任意一个consumer上。这里我们假设有三个consumer:C0、C1和C2,三个topic:t0、t1和t2,这三个topic分别有1、2和3个分区,那么总共的分区为:t0-0、t1-0、t1-1、t2-0、t2-1和t2-2。关于订阅情况,这里C0订阅了t0,C1订阅了t0和1,C2则订阅了t0、t1和t2。这里的分区分配规则如下:
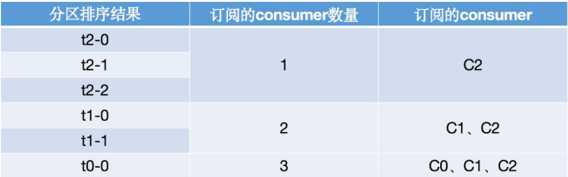
a. 首先将t2-0尝试分配给C0,由于C0没有订阅t2,因而分配不成功,继续轮询下一个consumer;
b. 然后将t2-0尝试分配给C1,由于C1没有订阅t2,因而分配不成功,继续轮询下一个consumer;
c. 接着将t2-0尝试分配给C2,由于C2订阅了t2,因而分配成功,此时由于C2分配的分区数发生变化,各个consumer变更后的排序结果为:
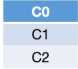
d. 接下来的t2-1和t2-2,由于也只有C2订阅了t2,因而其最终还是会分配给C2,最终在t2-0、t2-1和t2-2分配完之后,各个consumer的排序以及其分区分配情况如下:
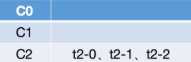
e. 接着继续分配t1-0,首先尝试将其分配给C0,由于C0没有订阅t1,因而分配不成功,继续轮询下一个consumer;
f. 然后尝试将t1-0分配给C1,由于C1订阅了t1,因而分配成功,此时各个consumer以及其分配的分区情况如下:
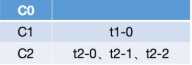
g. 同理,接下来会分配t1-1,虽然C1和C2都订阅了t1,但是由于C1排在C2前面,因而该分区会分配给C1,即:
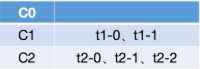
h. 最后,尝试将t0-0分配给C0,由于C0订阅了t0,因而分配成功,最终的分配结果为:
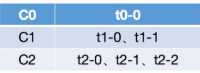
-- 上面的分配过程中,需要始终注意的是,虽然示例中的consumer顺序始终没有变化,但这是由于各个分区分配之后正好每个consumer所分配的分区数量的排序结果与初始状态一致。这里读者也可以比较一下这种分配方式与前面讲解的Round Robin进行对比,可以很明显的发现,Sticky重分配策略分配得更加均匀一些。
-- 由于前一个示例中最终的分区分配方式模拟宕机的情形比较简单,因而我们使用另一种订阅策略。这里我们的示例的consumer有三个:C0、C1和C2,topic有四个:t0、t1、t2和t3,每个topic都有两个分区,那么总的分区有:t0-0、t0-1、t1-0、t1-1、t2-0、t2-1、t3-0和t3-1。这里的订阅情况为三个consumer订阅所有的主题,那么如果按照Sticky的分区分配策略,初始状态时,分配情况如下,读者可以按照前一示例讲解的方式进行推算:
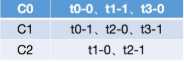
-- 这里我们假设在消费的过程中,C1发生了宕机,此时就会发生再平衡,而根据Sticky策略,其再分配步骤如下:


a. 首先尝试将t0-1分配给C2,由于C2订阅了t0,因而可以分配成功,此时consumer排序和分区分配情况如下,需要注意的是,虽然分配之后,C2和C0的分区数量相同,但是由于按照字典序,C0在C2前面,因而排序情况还是会发生变化:

b. 然后尝试将t2-0分配给C0,由于C0订阅了t2,因而分配可以成功,此时consumer排序和分区分配情况如下:

c. 最后尝试分配t3-1给C2,由于C2订阅了t3,因而分配可以成功,此时consumer排序与分区分配情况如下:

-- 在上面的分区分配过程中,我们可以看到,由于分区的不断分配,各个consumer所拥有的分区数量也在不断变化,因而其排序情况也在变化,但是最终可以看到,各个分区是均匀的分配到各个consumer的,并且还保证了当前consumer已经消费的分区是不会分配到其他的consumer上的。
标签:宕机 名称 code 字符串 -- 区分 分析 分配 遍历
原文地址:https://www.cnblogs.com/haojia/p/12404182.html