标签:品种 pre 数据量 直接 block 两种 顺序 图片 child
对文本提取特征
1、最简单直接的方式就是 用顺序数字表示不同的单词,进行特征提取
比如:形容女人用漂亮,女孩用可爱
形-0 容-1 女-2 人-3 用-4 漂-5 亮-6 孩-7 可-8 爱-9
则 原句子的特征:0123456789
使用该种方式,由于不用词语的量纲不一样,无法进行特征的计算,所以 one-host 表示法就来了
2、使用一维数组表示一个字,句子就是 二维的稀疏矩阵
比如:形容女人用漂亮,女孩用可爱
形-1000000000 容-0100000000 女-0010000000 人-0001000000 用-0000100000 漂-0000010000 亮-0000001000 孩-0000000100 可-0000000010 爱-0000000001 则原句子特征 1000000000 0100000000 0010000000 0001000000 0000100000 0000010000 0000001000 0000000100 0000000010 0000000001
这个相对上面特征表示一个好处是特征计算简单,直接将稀疏矩阵对应位置相乘相加即可。另外他的劣势是由于是稀疏矩阵,大部分信息都是0,浪费存储空间和计算空间,到这就推导出embeddding层的作用了
3、将one-host稀疏矩阵映射为一个 总特征个数/维数 更小的矩阵,叫做embedding层的作用
第2点使用的稀疏矩阵
X = [ 1000000000 0100000000 0010000000 0001000000 0000100000 0000010000 0000001000 0000000100 0000000010 0000000001 ] 使用 w=[ w10 w11 w20 w21 w30 w31 w40 w41 w50 w51 w60 w61 w70 w71 w80 w81 w90 w91 w100 w101 ] X * w = [ w10 w11 w20 w21 w30 w31 w40 w41 w50 w51 w60 w61 w70 w71 w80 w81 w90 w91 w100 w101 ]
以上,10 x 10矩阵,乘以 10 x 2的矩阵,变成了10 x 2矩阵 ,特征大小缩小了 10 / 2 = 5倍。(注:这个地方可以设置为降维,当w取 10 x20 ,就可以实现升维的作用)
看到以上embedding可以降维,你是不是会有信息丢失的担心的丢失或者这种降维实际有啥意义? 下面从文本降维的例子理解下
4、word-embedding
假设有1000个词汇量。第一个词是[1,0,0,0,0,...],其余的词都是某个位置为1,其余都是0的1000维度的向量,也即one-hot编码。
从one-hot编码原理可知,不同词仅仅是 随机或者排序后 从先到后在不同的位置设置为1,其余位置设置为0.也就是不同词之间没有关系,而这和现实不符。比如:
语义:girl和woman虽然用在不同年龄上,但指的都是女性。man和boy虽然用在不同年龄上,但指的都是男性。
复数:word和words仅仅是复数和单数的差别。
时态:buy和bought表达的都是“买”,但发生的时间不同。
我们更希望用诸如“语义”,“复数”,“时态”等维度去描述一个单词。每一个维度不再是0或1,而是连续的实数,表示不同的程度。这个就是Distributed representation的方式
假设我们的词汇只有4个,girl, woman, boy, man,下面就思考用两种不同的表达方式会有什么区别。
尽管我们知道他们彼此的关系,但是计算机并不知道。在神经网络的输入层中,每个单词都会被看作一个节点。 而我们知道训练神经网络就是要学习每个连接线的权重。如果只看第一层的权重,下面的情况需要确定4*3个连接线的关系,因为每个维度都彼此独立,girl的数据不会对其他单词的训练产生任何帮助,训练所需要的数据量,基本就固定在那里了。
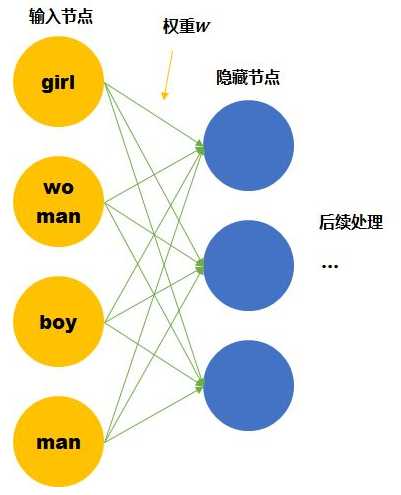
我们这里手动的寻找这四个单词之间的关系 。可以用两个节点去表示四个单词。每个节点取不同值时的意义如下表。 那么girl就可以被编码成向量[0,1],man可以被编码成[1,1](第一个维度是gender,,第二个维度是age)

那么这时再来看神经网络需要学习的连接线的权重就缩小到了2*3。同时,当送入girl为输入的训练数据时,因为它是由两个节点编码的。那么与girl共享相同连接的其他输入例子也可以被训练到(如可以帮助到与其共享female的woman,和child的boy的训练)。
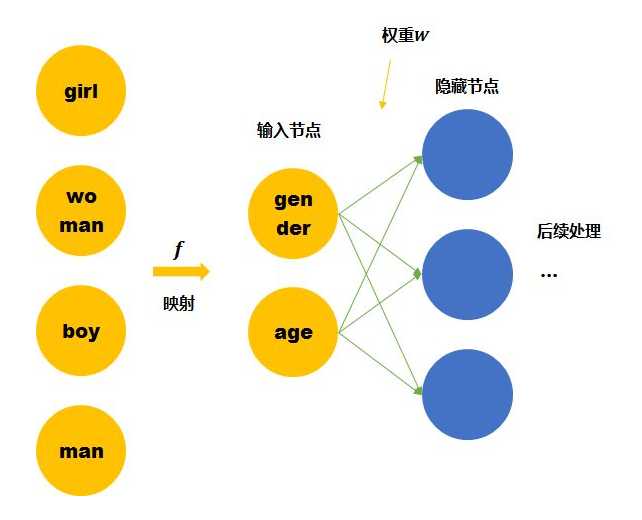
Word embedding也就是要达到第二个神经网络所表示的结果,降低训练所需要的数据量。
而上面的四个单词可以被拆成2个节点的是由我们人工提供的先验知识将原始的输入空间经过 (上图中的黄色箭头)投射到了另一个空间(维度更小),所以才能够降低训练所需要的数据量。 但是我们没有办法一直人工提供,机器学习的宗旨就是让机器代替人力去发现pattern。
Word embedding就是要从数据中自动学习到输入空间到Distributed representation空间的 映射
5、那 embedding怎么训练呢?
问题来了,我们该如何自动寻找到类似上面的关系,将One hot representation转变成Distributed representation。 我们事先并不明确目标是什么,所以这是一个无监督学习任务。
无监督学习中常用思想是:当得到数据后,我们又不知道目标(输出)时,
Word embedding更偏向于方向二。 同样是学习一个 ,但训练后并不使用
,而是只取前半部分的
。
到这里,我们希望所寻找的 既有标签
,又可以让
所转换得到的
的表达具有Distributed representation中所演示的特点。
同时我们还知道,
单词意思需要放在特定的上下文中去理解。
那么具有相同上下文的单词,往往是有联系的。
实例:那这两个单词都狗的品种名,而上下文的内容已经暗指了该单词具有可爱,会舔人的特点。
而从上面这个例子中我们就可以找到一个 :预测上下文。
用输入单词作为中心单词去预测其他单词
出现在其周边的可能性。
我们既知道对应的 ,同时该任务
又可以让
所转换得到的
的表达具有Distributed representation中所演示的特点。 因为我们让相似的单词(如泰迪和金巴)得到相同的输出(上下文),那么神经网络就会将泰迪的输入和金巴的输入经过神经网络
得到的泰迪的输出和金巴的输出几乎相同。
标签:品种 pre 数据量 直接 block 两种 顺序 图片 child
原文地址:https://www.cnblogs.com/pyclq/p/12405631.html