标签:rtb flush linux fail day relevant install mes into
I. Introduction
This document provides common steps and commands used to retrieve core files in Nexus switching platforms - Nexus7000, Nexus5000, Nexus 4000, Nexus 3000 and Nexus2000.
II. Technical Background Information
NX-OS is a full-featured, modular, and scalable Cisco networking operating system available for entire Nexus switching platforms.
For more information, please review the information and documents provided at:
http://www.cisco.com/en/US/products/ps9372/index.html
NX-OS runs on Linux Kernel. From kernel‘s perspective all the NX-OS processes are run in the "User" space. Available DRAM are split into two regions: (1) Kernel space (a.k.a Low Memory region) and (2) User space (a.k.a High Memory region).
Kernel
The kernel needs memory to store its own text, data, and Kernel Loadable Modules (KLMs). KLMs are pieces of code that are loaded into the kernel (as opposed to being a separate user process). An example of kernel memory usage is when an inband port driver allocates memory to receive packets.
User processes
This memory is used by Cisco NX-OS processes (along with Kernel processes that are not integrated into the kernel)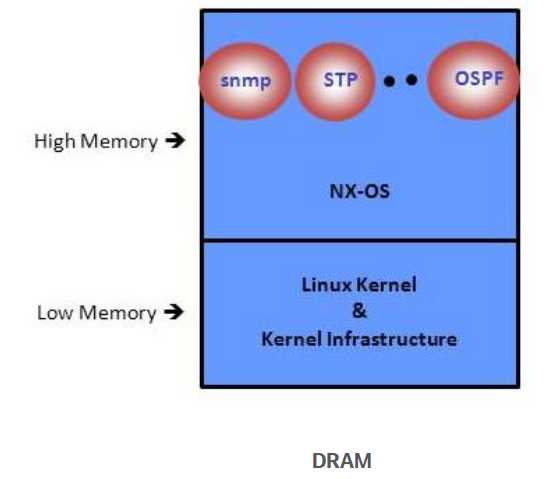
III. What is a Core file ?
Core file is same as crashinfo file generated in Cisco IOS platforms, but with more log and system files bundled together into a tar file.
Core file is generated when a process crash or experience an exception.
Contents of a core file - generated by Nexus7000 switch: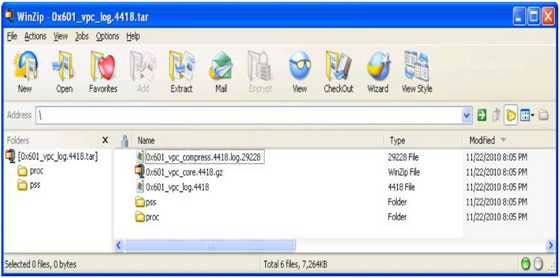
IV. Crash / Exception:
When a specific process (called as Service) crahes, the device should report a log message, as follows:
Scenario 1:
%SYSMGR-2-SERVICE_CRASHED: Service "vpc" (PID 5883) hasn‘t caught signal 11 (core will be saved)
Here, service "vpc" has crashed and a core file will be saved.
Scenario 2:
The device may report message, with no core file created.
%SYSMGR-2-SERVICE_CRASHED: Service "stp" (PID 4668) hasn‘t caught signal 9 (no core).
Here, sevice "stp" crashed but has not generated any core file.
V. Retreiving Core files:
For Scenario 1 (as mentioned above):
If there is a process crash/exception reported and the switch has NOT reloaded (since the exception/crash), then do "show cores" to get list of cores.
N7K# show cores
VDC Module Instance Process-name PID Date(Year-Month-Day Time)
--- ------ -------- --------------- -------- -------------------------
1 6 1 vpc 4763 2011-01-10 11:33:01
1 6 1 vpc 5883 2011-01-10 11:33:05
Please do "show cores vdc-all" to see core files in all VDCs.
The above results indicate that the exception was reported for "vpc" service in VDC #1, Module #6.
The results provide different Process ID (PID) - 4763 and 5883 - the specific process had at exception, with timestamps.
Instance number will be useful to identify the core files when a specific process with same PID (for the same VDC) experience multiple exceptions.
Please be aware that "show cores" command do NOT provide any information, if the switch has rebooted since the exception.
To copy the core files to FTP or TFTP server, follow the steps:
N7K# copy core:?
core: Enter URL "core://<module-number>/<process-id>[/instance-num]“
N7K# copy core://6/4763/1 ?
bootflash: Select destination filesystem
ftp: Select destination filesystem
scp: Select destination filesystem
sftp: Select destination filesystem
slot0: Select destination filesystem
tftp: Select destination filesystem
usb1: Select destination filesystem
usb2: Select destination filesystem
The above command collects all relevant info (system info, log files etc.) from the switch and bundles them into .tar file.
It is NOT recommended to copy files directly from different filesystems manually.
If the switch has rebooted, do following command to see if there are core files generated earlier:
N7K# dir logflash://sup-1/core
100499456 Aug 29 22:36:54 2011 0x501_ethpm_core.16574
8638991 Aug 29 22:45:14 2011 0x501_ethpm_core.4165.gz
37139 Aug 29 22:36:54 2011 0x501_ethpm_log.16574
7699061 Aug 29 22:36:32 2011 0x501_ethpm_log.16576.tar.gz
8208542 Aug 29 22:36:32 2011 0x501_ethpm_log.4165.tar.gz
7698622 Aug 29 22:45:30 2011 1314657930_0x501_ethpm_log.16576.tar.gz
8208230 Aug 29 22:45:30 2011 1314657930_0x501_ethpm_log.4165.tar.gz
If there is Supervisor failover occurred, please check the other/standby sup for core files.
N7K# dir logflash://sup-2/core
In Nexus5000, Nexus4000, Nexus3000 and Nexus2000 platforms, as there is no supervisor engine redundancy, there will not be any failover.
Note:
In Nexus5000, Nexus4000, Nexus3000 and Nexus2000 platforms the core files are stored in the "volatile:" and not in the "logflash:" file system.
N3k-3# dir volatile:?
volatile:///
volatile://module-1/
volatile://sup-1/
volatile://sup-active/
volatile://sup-local/
Please be aware that contents of "volatile:" file system are flushed on reload.
For Scenario 2 (as mentioned above):
N7K# show process log vdc-all
VDC Process PID Normal-exit Stack Core Log-create-time
--- --------------- ------ ----------- ----- ----- ---------------
1 installer 10544 N N N Thu Jun 10 17:49:21 2010
1 ethpm 16574 N Y N Mon Aug 29 22:36:15 2011
Here, the "ethpm" sevice crashed and generated "Stack" (flagged with Y) but no "Core" file (flagged with N).
At the same, for the "installer" process, neither "Stack" nor "Core" file is generated.
For the "installer" process, furher information can be obtained by:
N7K# show process log pid 10544
Service: installer
Description: Installer
Started at Thu Jun 10 17:45:42 2010 (483528 us)
Stopped at Thu Jun 10 17:49:21 2010 (719259 us)
Uptime: 3 minutes 39 seconds
Start type: SRV_OPTION_RESTART_STATELESS (23)
Death reason: SYSMGR_DEATH_REASON_FAILURE_NOCALLHOME (12)
Last heartbeat 0.00 secs ago
RLIMIT_AS: 69909875
System image name: n7000-s1-dk9.4.2.4.bin
System image version: 4.2(4) S32
Exit code: SYSMGR_EXITCODE_FAILURE_NOCALLHOME (20)
PID: 10544
SAP: 0
UUID: 0
For the "ethpm" process, the stack trace can be obtained by:
N7K# show process log pid 16574
Service: ethpm
Description: Test Ethernet Port Manager
Executable: /isan/bin/ethpm
Started at Mon Aug 29 22:36:15 2011 (188136 us)
Stopped at Mon Aug 29 22:36:15 2011 (746741 us)
Uptime: 0 seconds
Start type: SRV_OPTION_RESTART_STATEFUL (24)
Death reason: SYSMGR_DEATH_REASON_FAILURE_SIGNAL (2)
<snip>
Virtual Memory:
CODE 08048000 - 08356C90
DATA 08357000 - 08369BA8
BRK 083F0000 - 086F9000
STACK BFBB25C0
TOTAL 98996 KB
<snip>
Memory Map: 08048000 ethp 08357000 ethp 4143F000 ld-2.8.s 41459000 ld-2.8.s 4145
A000 ld-2.8.s 4145D000 libc-2.8.s 41596000 libc-2.8.s 41598000 libc-2.8.s 4159E0
<snip>
Register Set:
EBX BFBB0ADC ECX 00000000 EDX 00000002
ESI BFBB15B0 EDI 00000009 EBP BFBB1148
<snip>
Stack: 6976 bytes. ESP BFBB0A80, TOP BFBB25C0
0xBFBB0A80: 0000001F 00000000 00000000 00000001 ................
<snip>
VI. Why the core file is missing ? :
If the switch does not have enough space in the specific filesystem (logflash: or volatile: depending on the platform), then the core file may not be successfully generated/stored.
N7K# dir logflash://sup-1/
Usage for logflash://sup-1
498237440 bytes used
7394926592 bytes free
7893164032 bytes total
To check the free space available in different file systems, you can also do:
N7K# show system internal flash
Mount-on 1K-blocks Used Available Use% Filesystem
/ 409600 61372 348228 15 /dev/root
/proc 0 0 0 0 proc
/sys 0 0 0 0 none
/isan 1048576 339184 709392 33 none
....
/bootflash 1809684 673252 1044504 40 /dev/hda3
....
/logflash 7708168 95004 7221608 2 /dev/hde1
/bootflash_sup-remote 1809688 672952 1044808 40 127.1.1.2:/bootflash/
/logflash_sup-remote 7708168 34976 7281640 1 127.1.1.2:/logflash/
Same set of commands, from a Nexus3000 switch:
N3K# dir volatile://sup-1/
Usage for volatile://sup-1
0 bytes used
104857600 bytes free
104857600 bytes total
N3K# sh system internal flash
Mount-on 1K-blocks Used Available Use% Filesystem
/ 204800 112436 92364 55 /dev/root
/proc 0 0 0 0 proc
/post 2048 4 2044 1 none
/sys 0 0 0 0 none
.....
/volatile 102400 0 102400 0 none
/debug 20480 8 20472 1 none
.....
/bootflash 1609984 582492 945708 39 /dev/sda3
VII. Logs/Files to Capture:
If further analysis required on process exception / core files, please open a Service Request and send following logs:
- show cores vdc-all
- Core files saved using "copy core://<module-number>/<process-id>[/instance-num]..." command
- show process log vdc-all
- show process log details
- show logging onboard internal reset-reason
- show logging onboard stack-trace
- show logging onboard kernel-trace
- show module internal exceptionlog module <mod#>
Please make sure all these logs are captured to a file(s), as the logs may go several pages.
VIII. Further Information:
Cisco Nexus 7000 Series NX-OS Troubleshooting Guides:
http://docwiki.cisco.com/wiki/Cisco_Nexus_7000_Series_NX-OS_Troubleshooting_Guide
Cisco Nexus 7000 Series Switches Configuration Guides:
http://www.cisco.com/en/US/products/ps9402/products_installation_and_configuration_guides_list.html
Cisco Nexus 7000 Series Switches Command Reference Guides:
http://www.cisco.com/en/US/products/ps9402/prod_command_reference_list.html
Source:https://community.cisco.com/t5/networking-documents/retrieving-core-files-from-cisco-nexus-switching-platforms/ta-p/3124284
标签:rtb flush linux fail day relevant install mes into
原文地址:https://www.cnblogs.com/MomentsLee/p/12409123.html