标签:而不是 info ram print 执行 出现 col panda 判断
pandas的索引操作可以快速的完成多种功能。
import pandas as pd import numpy as np
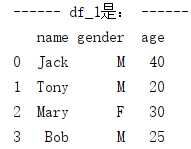
1. 首先pandas创建DataFrame
df_1 = pd.DataFrame([[‘Jack‘,‘M‘,40],[‘Tony‘,‘M‘,20],[‘Mary‘,‘F‘,30],[‘Bob‘,‘M‘,25]], columns=[‘name‘,‘gender‘,‘age‘]) #列表创建DataFrame print(‘------ df_1是: ------‘) print(df_1)
2. 直接列名检索
# 列名索引 a = df_1[‘name‘] print(a)

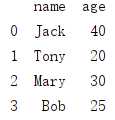
3. 同时取多列数据
# 同时取多列 b = df_1[[‘name‘,‘age‘]] print(b)
4. 切片索引
# 切片索引,按行索引 bb = df_1[1:3] print(bb)
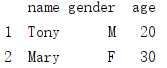
5. 条件索引
aa = df_1[df_1.age>25] print(aa)
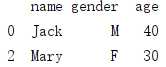
6. isin判断
# isin 索引 cc = df_1[df_1.name.isin([‘Jack‘,‘Bob‘])] print(cc)

7. loc取行数据
# loc取行 dd = df_1.loc[df_1.name.isin([‘Jack‘,‘Bob‘])] #去满足条件的所有行 print(dd)
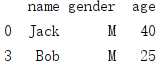
8. loc标签
# loc取行 ee = df_1.loc[1:3] #直接按照标签取,不是属于切片,所以会1-3行全部取出来 print(ee)

9. 多个条件,‘|‘ 条件取行(‘或‘条件),逻辑条件
ff = df_1.loc[df_1.name.isin([‘Jack‘,‘Bob‘]) | (df_1.age>25)] #多个条件,‘|‘条件取行 print(‘the value of ff is: ‘) print(ff) print(df_1.name.isin([‘Jack‘,‘Bob‘]) | (df_1.age>25))
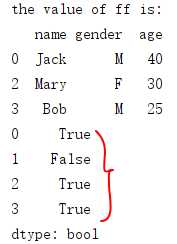
10. 多个条件取行,‘&‘ 条件取行,(‘与‘ 条件),逻辑条件
gg = df_1.loc[df_1.name.isin([‘Jack‘,‘Bob‘]) & (df_1.age>25)] #多个条件取行,‘&‘条件取行 print(‘the value of gg is: ‘) print(gg) print(df_1.name.isin([‘Jack‘,‘Bob‘]) & (df_1.age>25))

11. loc 按行、列条件取值,取其中某列,可用来取某一行某一列的值(也就是某个位置的值)
hh = df_1.loc[df_1.name.isin([‘Jack‘,‘Bob‘]) | (df_1.age>25), ‘age‘] print(hh)

12. loc多行、列取值,取多行多列
ii = df_1.loc[1:3, ‘name‘:‘gender‘] # ‘name‘:‘gender‘顺序有前后 print(‘the value of ii is: ‘) print(ii)
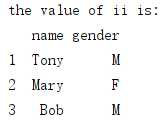
13. iloc:切片
jj = df_1.iloc[1:3] #此时按照切片规则取行 print(‘the value of jj is: ‘) print(jj)

14. ix:之前的方法,现在可以用loc和iloc来实现,执行的时候会出现:DeprecationWarning: .ix is deprecated. Please use .loc for label based indexing or .iloc for positional indexing。
mm = df_1.ix[1:3] #此时按照标签规则取行,而不是切片规则 print(‘the value of mm is: ‘) print(mm)
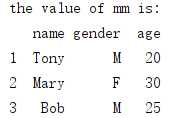
nn = df_1.ix[1:3, ‘name‘:‘gender‘] #此时按照标签规则取行,而不是切片规则 print(‘the value of nn is: ‘) print(nn)
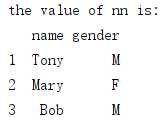
15. 如果其中的值都是数字,可以对整体进行限定,例如:
array_test = np.array([[1,2,3,4],[2,3,4,5],[3,4,5,6]]) df_3 = pd.DataFrame(array_test, index = [‘aa‘, ‘bb‘, ‘ff‘], columns = [‘c1‘, ‘c2‘, ‘c3‘, ‘c4‘]) #数组创建DataFrame print(‘------ df_3是: ------‘) print(df_3)

# 取满足条件的值:
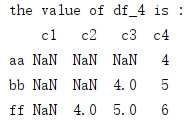
df_4 = df_3[df_3>3] #取满足条件的值 print(‘the value of df_4 is :‘) print(df_4)
# 将满足条件的值重新赋值:
df_3[df_3>3]=0 #将满足条件的值重新赋值 print(‘the value of df_3 is :‘) print(df_3)

##
标签:而不是 info ram print 执行 出现 col panda 判断
原文地址:https://www.cnblogs.com/qi-yuan-008/p/12412018.html