标签:row 观测 输入 height 随机 strong == 通过 密度
在之前的学习2020/01/02 深度学习数学基础学习——朴素贝叶斯中,大概的了解了生成学习的原理,但是对算法实现的 完整流程 不够清晰,所以今天想通过对生成学习回顾,明确一下生成学习的流程框架。
学习资料:斯坦福CS229-note2-Generative Learning algorithms的1.2节
类别先验概率: \(P(c)\)

类条件概率: \(P(\vec x | c)\) ,其中\(\vec x=(x_{1},x_{2},...,x_{m}); m为属性\),\(\vec x\)可以想象成特征向量
举例: 当类别\(c\)是西瓜时,1号属性值\(x_{1}\)为4的概率。
类别后验概率: \(P(c|\vec x) \Leftrightarrow P(f_{\vec \theta}(\vec x)|\vec x) \Leftrightarrow P(\vec \theta|\vec x)\)(就是机器学习器)
举例: 当1号属性值\(x_{1}\)为4时,类别\(c\)是西瓜的概率。
为了估计这个分布 \(P(随机向量 \vec X, 随机变量Y) <==> P(随机向量 \vec X | 随机变量Y)P(随机变量Y)\) ,我们需要了解\(P(随机向量 \vec X | 随机变量Y)\) 和 \(P(随机变量Y)\) 都是什么。
\(P(随机变量Y)\) 是类别先验概率,它可以通过统计样本中类别出现频次统计得到或者可以作为待估计参数 \(\phi\) 。
\(P(随机向量 \vec X | 随机变量Y)\) 是类别条件概率, 它是我们的预测的关键! 由于我们事先并不知道它的分布,那我们如何对它建模呢?最简单的方法就是假设!最为一般的我们假设它服从 多元(维)高斯分布-CS229-note2-1.1节。

根据最大后验估计,
\(\begin{aligned} \ell\left(\phi, \mu_{0}, \mu_{1}, \Sigma\right) &=\log \prod_{i=1}^{m} p\left(x^{(i)}, y^{(i)} ; \phi, \mu_{0}, \mu_{1}, \Sigma\right) =\log \prod_{i=1}^{m} p\left(x^{(i)} | y^{(i)} ; \mu_{0}, \mu_{1}, \Sigma\right) p\left(y^{(i)} ; \phi\right) \end{aligned}\)
通过最大化 \(\ell\) 求得参数:

为了便于可视化,我们假设 \(随机向量 \vec X\) 的长度(维度)为2。
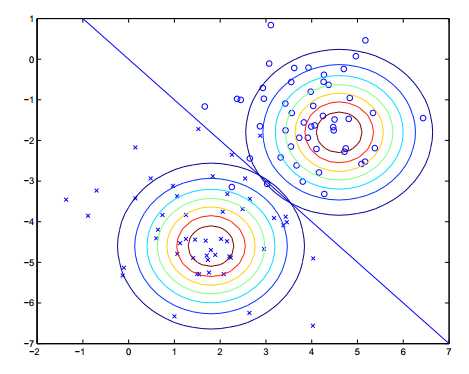
从图中可以看出,坐标在左下圆圈的点属于 \(\mu1\) 的分布,坐标在右上的点输入 \(\mu2 的分布\)。且越靠近圆心,点越密集,符合多元高斯概率密度函数的特点。
2020/03/05 生成模型&生成学习(Generative Learning)的流程
标签:row 观测 输入 height 随机 strong == 通过 密度
原文地址:https://www.cnblogs.com/Research-XiaoEMo/p/12419416.html