标签:样本 梯度 多个 matrix 第一个 神经元 输入 技术 lin
神经元可以理解为一个具有多个输入、单个输出的模型,输入和输出的关系可以用一个函数来表示。如果用\(x_1,x_2,x_3,\cdots,x_n\)表示输入,\(y\)表示输出,那么这个函数可以表示为:
\[y = a(w_1x_1+w_2x_2+w_3x_3+\cdots+w_nx_n+b)\]
其中,\(w_1,w_2,w_3,\cdots,w_n\)称做神经元的权重,\(b\)称作神经元的偏置,\(a\)是一个非线性函数,称作神经元的激活函数。
单位阶跃函数
\[ f(x)={ \begin{cases} 0, &x<0\ 1,&x\geq0 \end{cases} } \]
Sigmoid函数
\[ f(x) = \frac{1}{1 + e^{-x}} \]
ReLU
\[ f(x) = max(0, x) \]
神经网络是将多个神经元连接在一起组成的网络,如下所示:
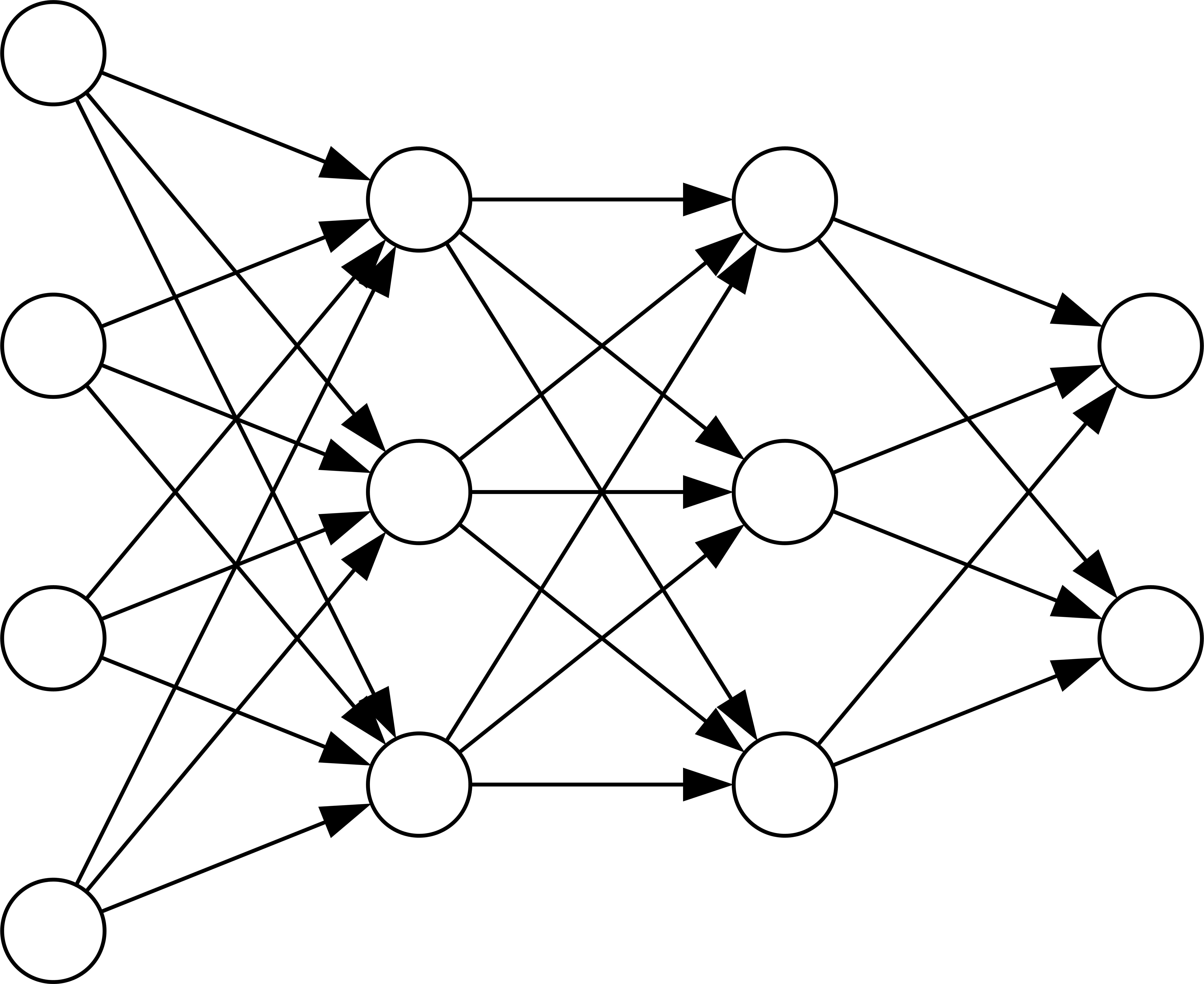
图中的神经元一共有4层,最左边是输入层,中间的2层是隐藏层,最右边的是输出层。除了输入层之外,每一层的神经元都与前一层的每个神经元连在一起。输入层的神经元输入和输出是相同的,隐藏层和输出层的神经元输入和输出的关系如下:
\[
z_j^l = w^l_{j1}a^{l-1}_1 + w^l_{j2}a^{l-1}_2+w^l_{j3}a^{l-1}_3+\cdots+w^l_{jn}a^{l-1}_n+b^l_j
\]
\[
a^l_j=az^l_j
\]
其中,\(w^l_{jn}\)表示第\(l-1\)层的第\(n\)个神经元到第\(l\)层第\(j\)个神经元的权重,\(a^{l-1}_n\)表示第\(l-1\)层的第\(n\)个神经元的输出。\(b^l_j\)表示第\(l\)层第\(j\)个神经元的偏置。\(a\)表示神经元的激活函数。\(z^l_j\)第\(l\)层第\(j\)个神经元的加权输入。
第一隐藏层的矩阵表示:
\[ \begin{bmatrix} a^2_1 \ a^2_2 \ a^2_3 \ \end{bmatrix} = a \left( \begin{bmatrix} w^2_{11} & w^2_{12} & w^2_{13} & w^2_{14}\ w^2_{21} & w^2_{22} & w^2_{23} & w^2_{24}\ w^2_{31} & w^2_{32} & w^2_{33} & w^2_{34}\ \end{bmatrix} \begin{bmatrix} a^1_1 \ a^1_2 \ a^1_3 \ a^1_4 \end{bmatrix} + \begin{bmatrix} b^2_1 \ b^2_2 \ b^2_3 \ \end{bmatrix} \right) \]
第二隐藏层的矩阵表示:
\[ \begin{bmatrix} a^3_1 \ a^3_2 \ a^3_3 \ \end{bmatrix} = a \left( \begin{bmatrix} w^3_{11} & w^3_{12} & w^3_{13} \ w^3_{21} & w^3_{22} & w^3_{23} \ w^3_{31} & w^3_{32} & w^3_{33} \ \end{bmatrix} \begin{bmatrix} a^2_1 \ a^2_2 \ a^2_3 \ \end{bmatrix} + \begin{bmatrix} b^3_1 \ b^3_2 \ b^3_3 \ \end{bmatrix} \right) \]
输出层的矩阵表示:
\[ \begin{bmatrix} a^4_1 \ a^4_2 \ \end{bmatrix} = a \left( \begin{bmatrix} w^4_{11} & w^4_{12} & w^4_{13} \ w^4_{21} & w^4_{22} & w^4_{23} \ \end{bmatrix} \begin{bmatrix} a^3_1 \ a^3_2 \ a^3_3 \ \end{bmatrix} + \begin{bmatrix} b^4_1 \ b^4_2 \ \end{bmatrix} \right) \]
代价函数
假设第k个样本的输出是\(a^3_1\left[k\right]\)和\(a^3_2\left[k\right]\),正解是\(t_1\left[k\right]\)和\(t_2\left[k\right]\),那么第k个样本的代价函数是
\[ C_k=\frac{1}{2} \left[ \left( t_1\left[k\right] - a^3_1\left[k\right] \right)^2 + \left( t_2\left[k\right] - t_1\left[k\right] \right)^2 \right] \]
如果样本集中含有n个样本,那么此时的代价函数\(C_T\)为
\[ C_T = C_1 + C_2 + C_3 + \cdots + C_n \]
代价函数\(C_T\)是一个多变量函数,它们分别是第一个隐藏层的12个权重和3个偏置,第二个隐藏层的9个权重和3个偏置,输出层的6个偏置和2个权重,一共有35个变量。
在代价函数取得最小值的时候,每一个变量的偏导数为0:
\[ \frac{\partial C_T}{\partial w^2_{11}} = 0 \\vdots \\frac{\partial C_T}{\partial b^2_1} = 0 \\vdots \\frac{\partial C_T}{\partial w^4_{21}} = 0 \\vdots \\frac{\partial C_T}{\partial b^4_2} = 0 \\]
理论上,可以找出满足上面由35个方程组成的方程组的所有的解,将它们代入代价函数\(C_T\)中,就可以找出使代价函数最小的这35个权重和偏置。
然而在实际上,目前的计算机求解类似上面的方程组非常困难,通常的做法是求出每个变量的导数值,然后根据导数值使每个变量的值发生微小的变化,从而使代价函数变小。比如对于\(w^2_1\),求出\(\frac{\partial C_T}{\partial w^2_{11}}\),如果大于0,使\(w^2_1\)减小一个微小的正数,反之则增加一个微小的正数。
\[ \left( \Delta w^2_{11}, \cdots, \Delta b^2_1, \cdots, \Delta w^4_{21}, \cdots, \Delta b^4_2 \right) = -\eta \left( \frac{\partial C_T}{\partial w^2_{11}}, \cdots, \frac{\partial C_T}{\partial b^2_1}, \cdots, \frac{\partial C_T}{\partial w^4_{21}}, \cdots, \frac{\partial C_T}{\partial b^4_2} \right) \]
其中,\(\Delta w^l_{ji}\)表示\(w^l_{ji}\)的变化量,\(\Delta b^l_j\)表示\(b^l_j\)的变化量,\(\eta\)表示学习率,是人们在训练神经网络时根据经验设定的一个正数。
标签:样本 梯度 多个 matrix 第一个 神经元 输入 技术 lin
原文地址:https://www.cnblogs.com/pIUhO/p/12420177.html