标签:ima 的区别 for 代码 BMI col size 并保存 管理

目前一个询价应用,这个应用需要从三个电商询价,然后保存在自己的数据库里。核心示例代码如下 ,由于是串行的,所以性能很慢
1 // 向电商 S1 询价,并保存 2 r1 = getPriceByS1(); 3 save(r1); 4 5 // 向电商 S2 询价,并保存 6 r2 = getPriceByS2(); 7 save(r2); 8 9 // 向电商 S3 询价,并保存 10 r3 = getPriceByS3(); 11 save(r3);
如果采用“ThreadPoolExecutor+Future”的方案,你的优化结果很可能是下面示例代码这样:用三个线程异步执行询价,通过三次调用 Future 的 get() 方法获取询价结果,之后将询价结果保存在数据库中
// 创建线程池 ExecutorService executor = Executors.newFixedThreadPool(3); // 异步向电商 S1 询价 Future<Integer> f1 = executor.submit( ()->getPriceByS1()); // 异步向电商 S2 询价 Future<Integer> f2 = executor.submit( ()->getPriceByS2()); // 异步向电商 S3 询价 Future<Integer> f3 = executor.submit( ()->getPriceByS3()); // 获取电商 S1 报价并保存 r=f1.get(); executor.execute(()->save(r)); // 获取电商 S2 报价并保存 r=f2.get(); executor.execute(()->save(r)); // 获取电商 S3 报价并保存 r=f3.get(); executor.execute(()->save(r));
上面方案有个小问题,你注意到了吗?
如果获取电商 S1 报价的耗时很长,那么即便获取电商 S2 报价的耗时很短,也无法让保存 S2 报价的操作先执行,因为这个主线程都阻塞在了 f1.get() 操作上。这点小瑕疵你该如何解决呢?
你应该猜到了,若加一个阻塞队列,获取到 各自的报价都进入阻塞队列,然后在主线程中消费阻塞队列,这样就能保证先获取到的报价先保存到数据库了。
// 创建阻塞队列 BlockingQueue<Integer> bq = new LinkedBlockingQueue<>(); // 电商 S1 报价异步进入阻塞队列 executor.execute(()-> bq.put(f1.get())); // 电商 S2 报价异步进入阻塞队列 executor.execute(()-> bq.put(f2.get())); // 电商 S3 报价异步进入阻塞队列 executor.execute(()-> bq.put(f3.get())); // 异步保存所有报价 for (int i=0; i<3; i++) { Integer r = bq.take(); executor.execute(()->save(r)); }
Java SDK 并发包里已经提供了 CompletionService。 不但能帮你解决先获取到的报价先保存到数据库的问题,而且还能让代码更简练。其原理也简单:是内部维护了一个阻塞队列,当任务执行结束就把任务的执行结果(Future 对象)加入到阻塞队列中
那么我们来用CompletionService重写刚才的询价系统
// 创建线程池 ExecutorService executor = Executors.newFixedThreadPool(3); // 创建 CompletionService CompletionService<Integer> cs = new ExecutorCompletionService<>(executor); // 异步向电商 S1 询价 cs.submit(()->getPriceByS1()); // 异步向电商 S2 询价 cs.submit(()->getPriceByS2()); // 异步向电商 S3 询价 cs.submit(()->getPriceByS3()); // 将询价结果异步保存到数据库 for (int i=0; i<3; i++) { Integer r = cs.take().get(); executor.execute(()->save(r)); }
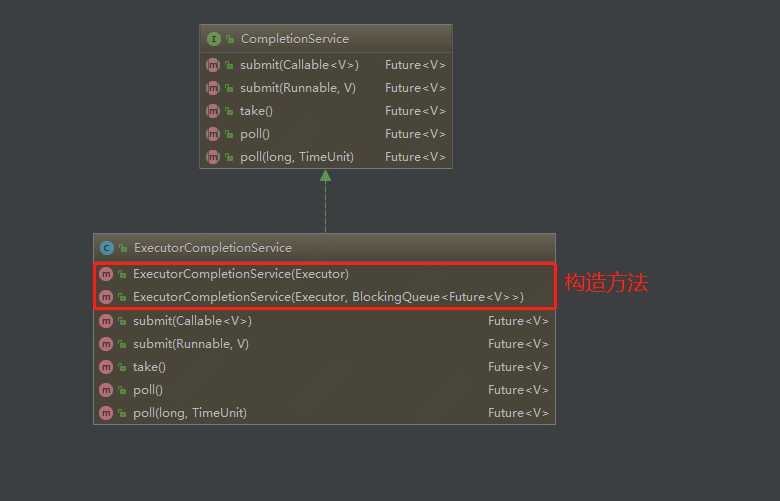
类图中可以看到,有5个方法,
1.submit(callable()) 有返回值 通过调用get()来获得
2.submit(Runable())无返回值
3.take()、poll() 都是从阻塞队列中获取并移除一个元素;它们的区别在于如果阻塞队列是空的,那么调用 take() 方法的线程会被阻塞,而 poll() 方法会返回 null 值
4.poll(long timeout, TimeUnit unit) 方法支持以超时的方式获取并移除阻塞队列头部的一个元素,如果等待了 timeout unit 时间,阻塞队列还是空的,那么该方法会返回 null 值。
使用场景:
1. 需要批量提交异步任务的时候建议你使用 CompletionService。CompletionService 将线程池 Executor 和阻塞队列 BlockingQueue 的功能融合在了一起,能够让批量异步任务的管理更简单。
2.让异步任务的执行结果有序化。先执行完的先进入阻塞队列,利用这个特性,你可以轻松实现后续处理的有序性,避免无谓的等待。
3.线程池隔离。CompletionService支持创建知己的线程池,这种隔离性能避免几个特别耗时的任务拖垮整个应用的风险。
标签:ima 的区别 for 代码 BMI col size 并保存 管理
原文地址:https://www.cnblogs.com/amberJava/p/12423843.html