标签:test 文件中 mysql高可用性 can 获取 crm 重启 work osi
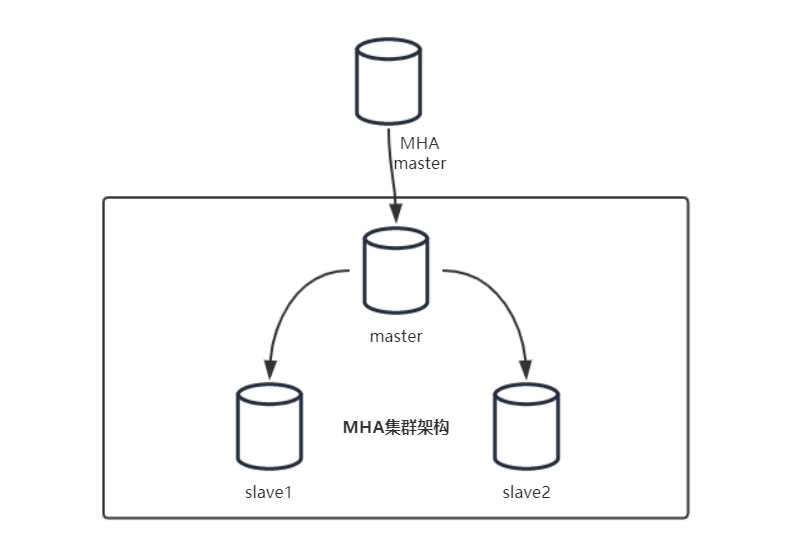
该软件由两部分组成:MHA Manager(管理节点)和 MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。MHA 适合任何存储引擎, 只要能主从复制的存储引擎它都支持,不限于支持事物的 innodb 引擎。
官方介绍:
MHA集群架构图:
识别含有最新的更新的slave;
应用差异的中继日志(relay log)到其他的slave;
应用从master保存的二进制日志文件(binlog events);
提升一个slave为新的master;
masterha_check_repl 检查MySQL复制情况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog 去除不必要的 ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs
MySQL版本:5.7.28
VIP(虚IP):
注:1主2从GTID
环境规划:
| ip | 主机名 | 网卡 | server_id | 功能 | |
| Master、Node | 10.0.0.51 | db01 | eth0 | 51 | 主库 |
| Node | 10.0.0.52 | db02 | eth0 | 52 | 从库 |
| Node | 10.0.0.53 | db03 | eth0 | 53 |
ln -s /app/database/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog ln -s /app/database/mysql/bin/mysql /usr/bin/mysql
[root@db01 ~]# ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory ‘/root/.ssh‘. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:yYSbmv/grRRvcSCFgwg0lRa0Coguy8+RkGG+EzC4KyE root@db01 The key‘s randomart image is: +---[RSA 2048]----+ |o+o=o. .. | |+ ooo oo | |Bo.. o.o | |*o+ * o | |EB + S . | |+++ .o o o | |++ oo o o | |. + .+ + | | o +oo | +----[SHA256]-----+
yum install sshpass -y
#!/bin/bash #前提请把公钥默认创建完成 #例 ssh-keygen --- 一路回车 # yum install sshpass -y 先执行 cat<<eof ******************************************** 注:yum install sshpass -y 先执行 请输入你的网段,查看可用IP地址. 例:10.0.0. 请耐心等待! ******************************************* eof read -p "Please enter the network segment where you want to distribute the secret keys : " ip read -s -p "Please enter your local password :" pass echo $ip | grep -Ex ‘(25[0-5]|2[0-4][0-9]|1[0-9][0-9]|[1-9][0-9]|[1-9]).((25[0-5]|2[0-4][0-9]|[01]?[0-9]?[0-9])\.){2}‘ &> /dev/null check=$? sleep 3 if [ $check -eq 0 ]; then for i in ${ip}{1..255} do { ping -c 1 $i &> /dev/null if [ $? -ne 0 ]; then echo $i &> /dev/null else . /etc/init.d/functions timeout 5 sshpass -p$pass ssh-copy-id -f -i ~/.ssh/id_rsa.pub root@$i -o StrictHostKeyChecking=no &> /dev/null if [ $? -eq 0 ] then action "主机 $i" /bin/true echo "" else action "主机 $i" /bin/false echo "" fi fi }& done else echo "当前仅支持ipv4格式且是十进制,请重新输入" fi wait echo "结束"
[root@db01 ~]# sh key.sh ******************************************** 注:yum install sshpass -y 先执行 请输入你的网段,查看可用IP地址. 例:10.0.0. 请耐心等待! ******************************************* Please enter the network segment where you want to distribute the secret keys : 10.0.0. --网段加个点 Please enter your local password : ---主机的密码 主机 10.0.0.254 [FAILED] 主机 10.0.0.52 [ OK ] 主机 10.0.0.53 [ OK ] 主机 10.0.0.51 [ OK ] 主机 10.0.0.2 [FAILED] 结束
db01: ssh 10.0.0.51 date ssh 10.0.0.52 date ssh 10.0.0.53 date db02: ssh 10.0.0.51 date ssh 10.0.0.52 date ssh 10.0.0.53 date db03: ssh 10.0.0.51 date ssh 10.0.0.52 date ssh 10.0.0.53 date
github下载地址:
8.0 的版本:
注:因为需要去外网下载这里就直接准备好软件包
[root@db01 ~]# ls anaconda-ks.cfg key.sh MHA-2019-6.28.zip [root@db01 ~]# unzip MHA-2019-6.28.zip [root@db01 ~]# ls anaconda-ks.cfg email_2019-最新.zip master_ip_failover.txt mha4mysql-manager-0.56-0.el6.noarch.rpm Atlas-2.2.1.el6.x86_64.rpm key.sh MHA-2019-6.28.zip mha4mysql-node-0.56-0.el6.noarch.rpm
yum install perl-DBD-MySQL -y rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm Preparing... ################################# [100%] Updating / installing... 1:mha4mysql-node-0.56-0.el6 ################################# [100%]
mysql grant all privileges on *.* to mha@‘10.0.0.%‘ identified by ‘mha‘;
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
#创建配置文件目录 mkdir -p /etc/mha #创建日志目录 mkdir -p /var/log/mha/app1 #编辑mha配置文件 cat > /etc/mha/app1.cnf <<EOF [server default] manager_log=/var/log/mha/app1/manager manager_workdir=/var/log/mha/app1 master_binlog_dir=/data/binlog user=mha password=mha ping_interval=2 repl_password=123 repl_user=repl ssh_user=root [server1] hostname=10.0.0.51 port=3306 [server2] hostname=10.0.0.52 port=3306 [server3] hostname=10.0.0.53 port=3306 EOF
[root@db01 ~]# masterha_check_ssh --conf=/etc/mha/app1.cnf Thu Mar 5 00:08:37 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Mar 5 00:08:37 2020 - [info] Reading application default configuration from /etc/mha/app1.cnf.. Thu Mar 5 00:08:37 2020 - [info] Reading server configuration from /etc/mha/app1.cnf.. Thu Mar 5 00:08:37 2020 - [info] Starting SSH connection tests.. Thu Mar 5 00:08:38 2020 - [debug] Thu Mar 5 00:08:37 2020 - [debug] Connecting via SSH from root@10.0.0.52(10.0.0.52:22) to root@10.0.0.51(10.0.0.51:22).. Thu Mar 5 00:08:37 2020 - [debug] ok. Thu Mar 5 00:08:37 2020 - [debug] Connecting via SSH from root@10.0.0.52(10.0.0.52:22) to root@10.0.0.53(10.0.0.53:22).. Thu Mar 5 00:08:38 2020 - [debug] ok. Thu Mar 5 00:08:38 2020 - [debug] Thu Mar 5 00:08:37 2020 - [debug] Connecting via SSH from root@10.0.0.51(10.0.0.51:22) to root@10.0.0.52(10.0.0.52:22).. Thu Mar 5 00:08:37 2020 - [debug] ok. Thu Mar 5 00:08:37 2020 - [debug] Connecting via SSH from root@10.0.0.51(10.0.0.51:22) to root@10.0.0.53(10.0.0.53:22).. Thu Mar 5 00:08:38 2020 - [debug] ok. Thu Mar 5 00:08:39 2020 - [debug] Thu Mar 5 00:08:38 2020 - [debug] Connecting via SSH from root@10.0.0.53(10.0.0.53:22) to root@10.0.0.51(10.0.0.51:22).. Thu Mar 5 00:08:38 2020 - [debug] ok. Thu Mar 5 00:08:38 2020 - [debug] Connecting via SSH from root@10.0.0.53(10.0.0.53:22) to root@10.0.0.52(10.0.0.52:22).. Thu Mar 5 00:08:39 2020 - [debug] ok. Thu Mar 5 00:08:39 2020 - [info] All SSH connection tests passed successfully. #################################################################################################### [root@db01 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf Thu Mar 5 00:09:30 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Mar 5 00:09:30 2020 - [info] Reading application default configuration from /etc/mha/app1.cnf.. Thu Mar 5 00:09:30 2020 - [info] Reading server configuration from /etc/mha/app1.cnf.. Thu Mar 5 00:09:30 2020 - [info] MHA::MasterMonitor version 0.56. Thu Mar 5 00:09:31 2020 - [info] GTID failover mode = 1 Thu Mar 5 00:09:31 2020 - [info] Dead Servers: Thu Mar 5 00:09:31 2020 - [info] Alive Servers: Thu Mar 5 00:09:31 2020 - [info] 10.0.0.51(10.0.0.51:3306) Thu Mar 5 00:09:31 2020 - [info] 10.0.0.52(10.0.0.52:3306) Thu Mar 5 00:09:31 2020 - [info] 10.0.0.53(10.0.0.53:3306) Thu Mar 5 00:09:31 2020 - [info] Alive Slaves: Thu Mar 5 00:09:31 2020 - [info] 10.0.0.52(10.0.0.52:3306) Version=5.7.28-log (oldest major version between slaves) log-bin:enabled Thu Mar 5 00:09:31 2020 - [info] GTID ON Thu Mar 5 00:09:31 2020 - [info] Replicating from 10.0.0.51(10.0.0.51:3306) Thu Mar 5 00:09:31 2020 - [info] 10.0.0.53(10.0.0.53:3306) Version=5.7.28-log (oldest major version between slaves) log-bin:enabled Thu Mar 5 00:09:31 2020 - [info] GTID ON Thu Mar 5 00:09:31 2020 - [info] Replicating from 10.0.0.51(10.0.0.51:3306) Thu Mar 5 00:09:31 2020 - [info] Current Alive Master: 10.0.0.51(10.0.0.51:3306) Thu Mar 5 00:09:31 2020 - [info] Checking slave configurations.. Thu Mar 5 00:09:31 2020 - [info] read_only=1 is not set on slave 10.0.0.52(10.0.0.52:3306). Thu Mar 5 00:09:31 2020 - [info] read_only=1 is not set on slave 10.0.0.53(10.0.0.53:3306). Thu Mar 5 00:09:31 2020 - [info] Checking replication filtering settings.. Thu Mar 5 00:09:31 2020 - [info] binlog_do_db= , binlog_ignore_db= Thu Mar 5 00:09:31 2020 - [info] Replication filtering check ok. Thu Mar 5 00:09:31 2020 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking. Thu Mar 5 00:09:31 2020 - [info] Checking SSH publickey authentication settings on the current master.. Thu Mar 5 00:09:32 2020 - [info] HealthCheck: SSH to 10.0.0.51 is reachable. Thu Mar 5 00:09:32 2020 - [info] 10.0.0.51(10.0.0.51:3306) (current master) +--10.0.0.52(10.0.0.52:3306) +--10.0.0.53(10.0.0.53:3306) Thu Mar 5 00:09:32 2020 - [info] Checking replication health on 10.0.0.52.. Thu Mar 5 00:09:32 2020 - [info] ok. Thu Mar 5 00:09:32 2020 - [info] Checking replication health on 10.0.0.53.. Thu Mar 5 00:09:32 2020 - [info] ok. Thu Mar 5 00:09:32 2020 - [warning] master_ip_failover_script is not defined. Thu Mar 5 00:09:32 2020 - [warning] shutdown_script is not defined. Thu Mar 5 00:09:32 2020 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 & [1] 27904 --进程号
[root@db01 ~]# masterha_check_status --conf=/etc/mha/app1.cnf app1 (pid:27904) is running(0:PING_OK), master:10.0.0.51
vim /etc/mha/app1.cnf
[server default]
master_ip_failover_script=/usr/local/bin/master_ip_failover
[root@db01 data]# cp master_ip_failover.txt /usr/local/bin/master_ip_failover vim /usr/local/bin/master_ip_failover my $vip = ‘10.0.0.55/24‘; #虚拟vip地址 my $key = ‘1‘; #数字 my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip"; #开启命令注意网卡名称,我的是eth0 my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down"; #关闭命令
yum install dos2unix -y dos2unix /usr/local/bin/master_ip_failover chmod +x /usr/local/bin/master_ip_failover
注:查看本地网卡名称,这里是eth0
[root@db01 data]# ifconfig eth0:1 10.0.0.55/24 #添加的信息 ip -a inet 10.0.0.55/24 brd 10.0.0.255 scope global secondary eth0:1 valid_lft forever preferred_lft forever
masterha_stop --conf=/etc/mha/app1.cnf nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
[root@db01 /data]# masterha_check_status --conf=/etc/mha/app1.cnf app1 (pid:11923) is running(0:PING_OK), master:10.0.0.51
注意:keepalive的话,需要candidate_master=1和check_repl_delay=0进行配合。防止vip和主库选择不在一个节点。
注:因为机器有限,直接把binlog服务加入master节点。切记,误将备份的binlog日志和本地放在一起,否则会被覆盖掉,这里在配置文件写入
vim /etc/mha/app1.cnf [binlog1] no_master=1 hostname=10.0.0.51 master_binlog_dir=/data/mysql/binlog
hostname=10.0.0.51 # 本地ip地址
mkdir -p /data/mysql/binlog chown -R mysql.mysql /data/*
cd /data/mysql/binlog -----》必须进入到自己创建好的目录 mysqlbinlog -R --host=10.0.0.51 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
--read-from-remote-server:从远端拉binlog,不加会在本地找
--raw:本地以二进制方式保存binlog,不指定则以文本保存
--stop-never:一直同步不断
指定为raw,数据不会时时落盘,而是先搞到内存里,然后每4k刷盘一次,一旦连接断开,内存中数据马上都刷到磁盘上
拉取日志的起点,需要按照目前从库的已经获取到的二进制日志点为起点,需要在主库中查询位置点:
db01 [(none)]>show master status ; +------------------+----------+--------------+------------------+------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+------------------------------------------+ | mysql-bin.000002 | 730 | | | 5dfe203f-5edc-11ea-a789-000c291f7357:1-2 | +------------------+----------+--------------+------------------+------------------------------------------+ 1 row in set (0.00 sec)
注:在实际生产中我们也可以从当前binlog二进制日志直接备份,以为实际生产中的binlog文件很多,拉取会消耗很多资源和空间
master_stop --conf=/etc/mha/app1.cnf nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
邮件的作用就是当我们出现主从库切换时发送邮件通知相关人员进行数据库修复,这里我们使用qq邮箱
report_script=/usr/local/bin/send
[root@db01 ~]# unzip email_2019-最新.zip [root@db01 ~]# cd email/ [root@db01 ~/email]# cp -a * /usr/local/bin/ [root@db01 ~/email]# chmod +x /usr/local/bin/
vi /etc/mha/app1.cnf [server default] report_script=/usr/local/bin/send
#停止MHA masterha_stop --conf=/etc/mha/app1.cnf # 开启MHA nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
vim /usr/local/bin/testpl #!/bin/bash /usr/local/bin/sendEmail -o tls=no -f xxxxx@qq.com -t xxxxx@qq.com -s smtp.qq.com:25 -xu qq号 -xp 授权码 -u "[邮件标题]MHA警告" -m "[邮件内容]请检查MHA的工作状态" &>/tmp/sendmail.log
注:smtp授权方式:设置--->账户--->生成授权码
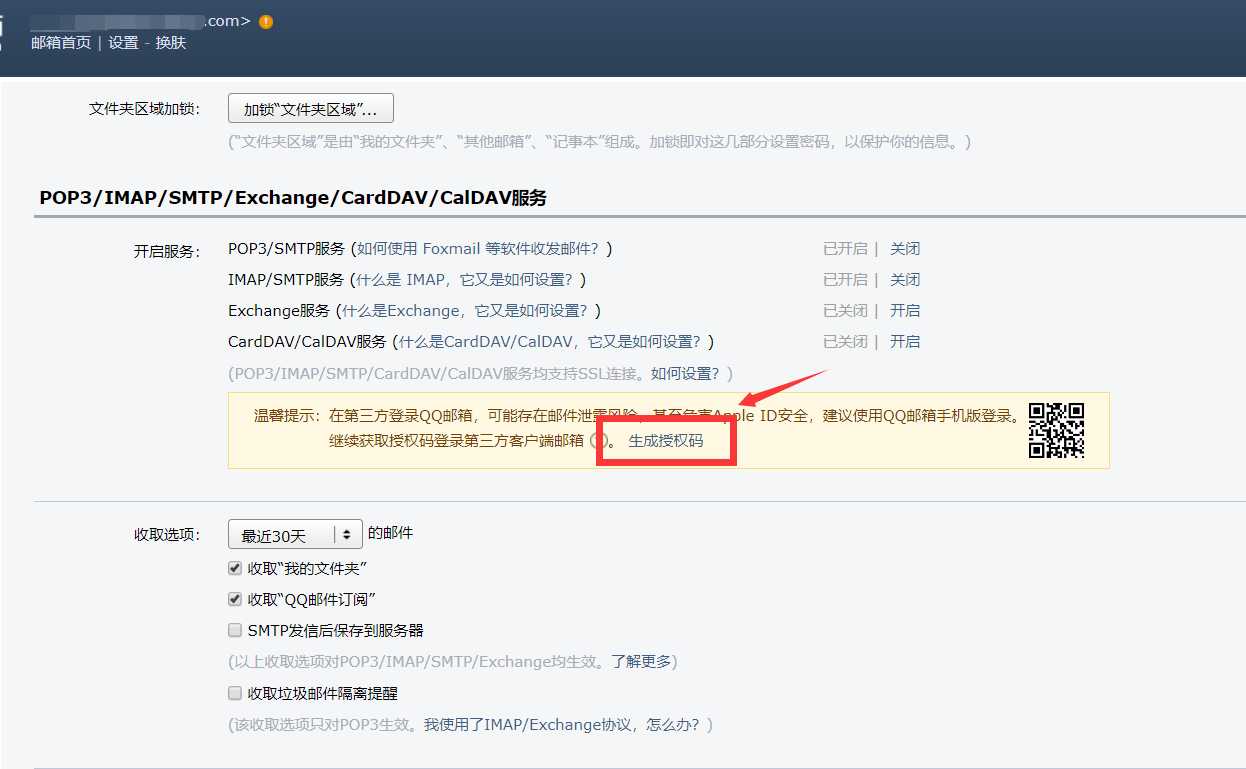
测试查看vip
故障库是否提出
切换日志/var/log/mha/app1/manager
# ps -ef | grep manager root 13087 2813 0 16:33 pts/1 00:00:00 grep --color=auto manager # masterha_check_status --conf=/etc/mha/app1.cnf app1 is stopped(2:NOT_RUNNING).
# cat /etc/mha/app1.cnf 如果节点已经被移除,说明切换过程已经大部分成功。 如果节点还在,证明切换过程在中间卡住。
vim /var/log/mha/app1/manager
# /etc/init.s/mysqld start
Starting MySQL.. SUCCESS!
将故障库修复好后,手工加入已有的主从中,作为从库
[root@db03 ~]# mysql -uroot -p -e "show slave status\G" | grep Master_Host: Master_Host: 10.0.0.52
change master to master_host=‘10.0.0.52‘, master_user=‘repl‘, master_password=‘123‘ , MASTER_AUTO_POSITION=1; start slave;
vim /etc/mha/app1,cnf 添加: [server1] hostname=10.0.0.51 port=3306
masterha_check_ssh --conf=/etc/mha/app1.cnf
masterha_check_repl --conf=/etc/mha/app1.cnf
[root@db01 ~]# cd /data/mysql/binlog/ [root@db01 binlog]# rm -rf * [root@db01 binlog]# mysqlbinlog -R --host=10.0.0.52 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
ifconfig eth0:1 10.0.0.55/24
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 & [root@db0 binlog]# masterha_check_status --conf=/etc/mha/app1.cnf app1 (pid:13189) is running(0:PING_OK), master:10.0.0.52
标签:test 文件中 mysql高可用性 can 获取 crm 重启 work osi
原文地址:https://www.cnblogs.com/Mercury-linux/p/12423995.html