标签:优先 image 简介 none xpath sel 第三方库 item file
导读:学习python爬虫很久了,一直习惯于requests抓取+xpath解析的两步走套路,直到我今天发现了pyquery这个爬虫利器后,才意识到python的世界没有最简,只有更简……
2020-03-06 21:22:12
pyquery是Python的一个第三方爬虫库,仿照 jQuery实现,语法与js十分相像。如果有js基础,那么应用pyquery简直是平步青云。pyquery自带网页解析和信息提取功能,所以应用起来会非常简洁。
pyquery安装(要求cssselect和lxml库支持):
pip install pyquery
安装好pyquery包后,默认可在..\Python\Python37\Lib\site-packages目录下找到pyquery文件,主要包括5个.py文件,分别是pyquery.py、 opener.py、 cssselectpath.py、 text.py以及一个初始化文件__init__.py,其中pyquery是主应用模块,内部调用其他3个模块。在pyquery模块中,实现了多个类,其中PyQuery是主类,继承列表类(所以列表的所有接口PyQuery都可以调用)。如下命令获取其所有方法接口:
from pyquery import PyQuery as pq
dir(pq)
pyquery的初始化可接收4种格式的参数,分别是字符串类型、html、html文件地址以及需要请求的ur相关信息,尤其是支持请求url的初始化方式,大大简化了的爬虫代码实现。
doc = pq("<html>hello, world</html>")
接收html
doc = pq(etree.fromstring("<html>hello, world</html>")
接收html文件地址
doc = pq(filename=path_to_html_file)
接受URL及相关信息
这里具体讲解pyquery接收url相关信息的实现方式。查看pyquery初始化方法,其接收不定参数和字典参数如下:
def __init__(self, *args, **kwargs):
html = None
elements = []
self._base_url = None
self.parser = kwargs.pop(‘parser‘, None)
if (len(args) >= 1 and
isinstance(args[0], string_types) and
args[0].split(‘://‘, 1)[0] in (‘http‘, ‘https‘)):
kwargs[‘url‘] = args[0]
if len(args) >= 2:
kwargs[‘data‘] = args[1]
args = []
pass
当接受参数满足:①参数个数大于等于1个、②第一个参数为字符串类型、③第一个参数可以解析为http或https格式,则提取url及其相关信息(如headers等)并赋值给字典参数kwargs,进行网页解析:
if kwargs:
# specific case to get the dom
if ‘filename‘ in kwargs:
html = open(kwargs[‘filename‘])
elif ‘url‘ in kwargs:
url = kwargs.pop(‘url‘)
if ‘opener‘ in kwargs:
opener = kwargs.pop(‘opener‘)
html = opener(url, **kwargs)
else:
html = url_opener(url, kwargs)
if not self.parser:
self.parser = ‘html‘
self._base_url = url
else:
raise ValueError(‘Invalid keyword arguments %s‘ % kwargs)
当前一步提取的字典参数不为空,且包含"url"键值时则解析为需要进行网页请求。网页请求中当初始化参数中指定了解析器opener时,则调用指定解析器,否则使用pyquery自定义的url_opener方法进行解析。 进一步查看pyquery自定义的url_opener方法:
try:
import requests
HAS_REQUEST = True
except ImportError:
HAS_REQUEST = False
--------------
def url_opener(url, kwargs):
if HAS_REQUEST:
return _requests(url, kwargs)
return _urllib(url, kwargs)
--------------
def _requests(url, kwargs):
encoding = kwargs.get(‘encoding‘)
method = kwargs.get(‘method‘, ‘get‘).lower()
session = kwargs.get(‘session‘)
if session:
meth = getattr(session, str(method))
else:
meth = getattr(requests, str(method))
pass
--------------
def _urllib(url, kwargs):
method = kwargs.get(‘method‘)
url, data = _query(url, method, kwargs)
return urlopen(url, data, timeout=kwargs.get(‘timeout‘, DEFAULT_TIMEOUT))
至此,我们知道pyquery的自定义解析器采用如下规则:
如果系统当前安装了requests库(第三方库,使用前需手动安装),则调用_requests方法,其中还根据初始化参数中是否指定了session来进一步区分
否则,则调用urllib库(python自带的网页解析库)urlopen方法进行解析
可见,pyquery相当于会自动调用requests库或默认的urllib库进行网页解析,且以前者优先,并支持携带requests的session进行解析。
pyquery支持与CSS一致的选择器实现方法:
from pyquery import PyQuery as pq
html = ‘‘‘
<div id="test">
<ul class="c1">
hello
<link href="http://123.com">this</link>
<link href="http://456.com">is</link>
<link href="http://789.com">pyquery</link>
</ul>
<ul class="c2">
world
<link href="http://321.com">test</link>
<link href="http://654.com">for</link>
<link href="http://987.com">spider</link>
</ul>
</div>
‘‘‘
doc = pq(html)
print(type(doc))#<class ‘pyquery.pyquery.PyQuery‘>
print(doc("div#test>ul.c1 link"))
"""
<link href="http://123.com">this</link>
<link href="http://456.com">is</link>
<link href="http://789.com">pyquery</link>
"""
其中:
pyquery初始化后为PyQuery对象类型
pyquery使用字符串识别标签和CSS标识
父标签和子标签间可以用>,也可以用空格
可以通过属性选择特定标签,其中id用"#",class用"."
pyquery可以很容易实现查找父类、子类、兄弟节点,主要方法如下:
item=doc(".c1")
link = item.find(‘link‘)
print(link)
"""
<link href="http://123.com">this</link>
<link href="http://456.com">is</link>
<link href="http://789.com">pyquery</link>
"""
item=doc(".c1")
p = item.parents()
print(p)
"""
<div id="test">
<ul class="c1">
hello
<link href="http://123.com">this</link>
<link href="http://456.com">is</link>
<link href="http://789.com">pyquery</link>
</ul>
<ul class="c2">
world
<link href="http://321.com">test</link>
<link href="http://654.com">for</link>
<link href="http://987.com">spider</link>
</ul>
</div>
"""
item=doc(".c1")
c = item.children()
print(c)
"""
<link href="http://123.com">this</link>
<link href="http://456.com">is</link>
<link href="http://789.com">pyquery</link>
"""
item=doc(".c1")
s = item.siblings()
print(s)
"""
<ul class="c2">
world
<link href="http://321.com">test</link>
<link href="http://654.com">for</link>
<link href="http://987.com">spider</link>
</ul>
"""
在完成选择节点的基础上,pyquery获取信息实现就非常简单。常用的方法如下:
items=doc(".c1 link").items()
print(items)#<generator object PyQuery.items at 0x000001F124C23390>
for item in items:
print(item.attr(‘href‘))
"""
http://123.com
http://456.com
http://789.com
"""
for item in items:
print(item.text())
"""
this
is
pyquery
"""
h = doc(‘ul‘).html()
print(h)
"""
hello
<link href="http://123.com">this</link>
<link href="http://456.com">is</link>
<link href="http://789.com">pyquery</link>
"""
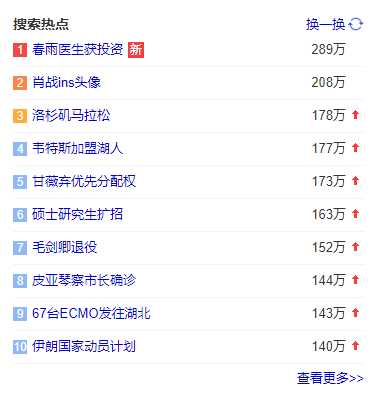
了解了基本操作,我们就可以应用pyquery进行快速的网页爬取了。以百度热点新闻为例,进行简单的接口分析获得url后只需要5行代码就可以轻松获取40条搜索热点标题,简直不能比这更方便了!
from pyquery import PyQuery as pq
doc = pq(url=‘http://top.baidu.com/buzz?b=1&fr=20811‘, encoding = ‘gb18030‘)
items = doc("td.keyword>a.list-title").items()
hots = [item.text() for item in items]
print(hots)
# [‘春雨医生获投资‘, ‘肖战ins头像‘, ‘洛杉矶马拉松‘, ‘韦特斯加盟湖人‘, ‘甘薇弃优先分配权‘, ‘硕士研究生扩招‘, ‘毛剑卿退役‘, ‘皮亚琴察市长确诊‘, ‘67台ECMO发往湖北‘, ‘伊朗国家动员计划‘, ‘雷神山机器人上岗‘, ‘上海马拉松升级‘, ‘湖北人民免费看剧‘, ‘草地贪夜蛾入侵‘, ‘快女喻佳丽结婚‘, ‘惠普拒绝施乐收购‘, ‘汪曾祺百年诞辰‘, ‘美国对塔利班空袭‘, ‘鼓浪屿将恢复开放‘, ‘Faker2000杀‘, ‘小罗因假护照被捕‘, ‘杨蓉经纪公司声明‘, ‘库里复出23分‘, ‘英国确诊人数翻倍‘, ‘英国再现集装箱藏人案‘, ‘Facebook员工确诊‘, ‘普利兹克建筑奖‘, ‘卢浮宫重新开放‘, ‘史酷比狗预告‘, ‘黄子佼孟耿如结婚‘, ‘法国政府征用口罩‘, ‘76人vs湖人‘, ‘龙卷风袭击美国‘, ‘邓肯执教首胜‘, ‘英国首例死亡病例‘, ‘布隆伯格退出大选‘, ‘库里复出‘, ‘罗永浩宣布开直播‘, ‘湖人战胜76人‘, ‘热刺大将怒揍球迷‘]
当然,为了实现反爬能力更强和更加高效的爬虫,可以在pyquery初始化时传入更多参数,例如headers、session和timeout等。
pyquery是一个高度集成的python第三方爬虫库,方法众多、实现简洁
pyquery内置了网页解析,会首先尝试调用requests库,若当前未安装则调用python内置urllib库解析
pyquery解析提取采用类似CSS选择器的方式进行
pyquery支持简洁的节点选择、属性和文本提取操作
pyquery还有很多其他方法,包括节点操作、伪类选择器等,但爬虫一般不需要用到
标签:优先 image 简介 none xpath sel 第三方库 item file
原文地址:https://www.cnblogs.com/luanhz/p/12430948.html