标签:loss 消失 text 归一化 title 因此 local sso big
将所有的预测结果都归一化到 0~1, 使用 Leaky RELU 作为激活函数。 Leaky RELU的公式如下:
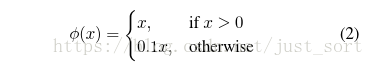
Leaky RELU可以解决RELU的梯度消失问题。
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。
简单的全部采用了sum-squared error loss来做这件事会有以下不足:
a) 8维的localization error和20维的classification error同等重要显然是不合理的。
b) 如果一些栅格中没有object(一幅图中这种栅格很多),那么就会将这些栅格中的bounding box的confidence
置为0,相比于较少的有object的栅格,这些不包含物体的栅格对梯度更新的贡献会远大于包含物体的栅格对梯度更新的贡献,这会导致网络不稳定甚至发散。
为了解决这些问题,YOLO的损失函数的定义如下:
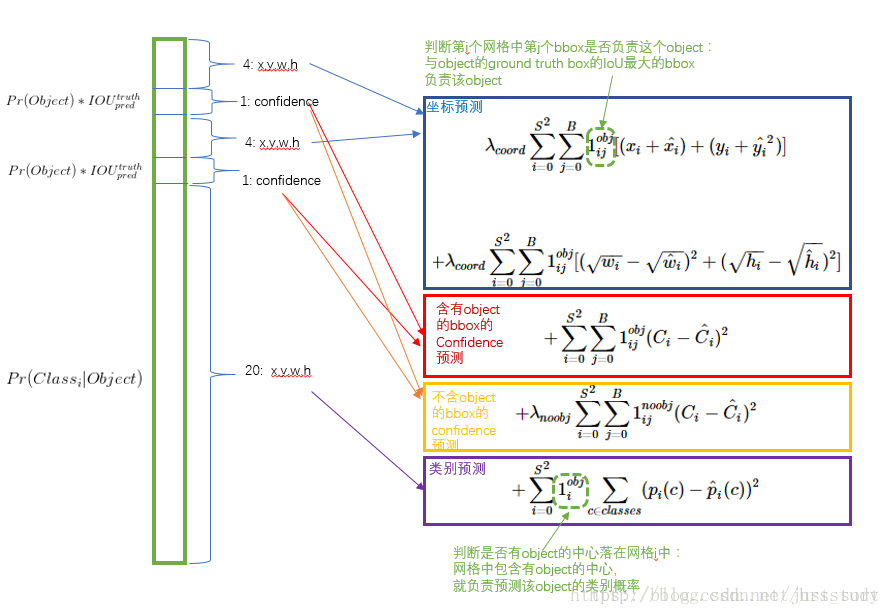
更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为 λcoord ,在pascal VOC训练中取5。(上图蓝色框)
对没有object的bbox的confidence loss,赋予小的loss weight,记为 λnoobj ,在pascal VOC训练中取0.5。(上图橙色框)
有object的bbox的confidence loss (上图红色框) 和类别的loss (上图紫色框)的loss weight正常取1。
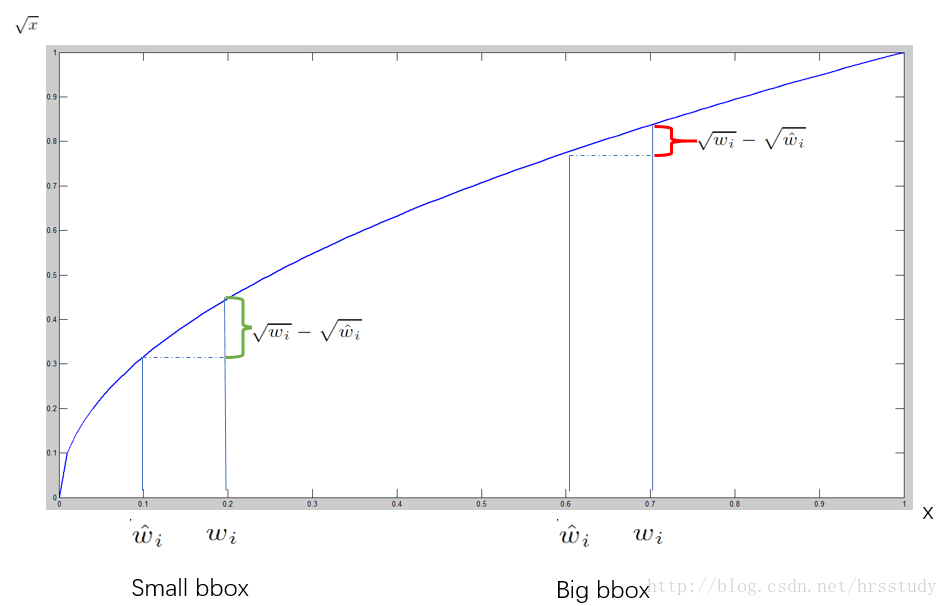
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏相同的尺寸对IOU的影响更大。而sum-square error loss中对同样的偏移loss是一样。
为了缓和这个问题,作者用了一个巧妙的办法,就是将box的width和height取平方根代替原本的height和width。 如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。
在 YOLO中,每个栅格预测多个bounding box,但在网络模型的训练中,希望每一个物体最后由一个bounding box predictor来负责预测。
因此,当前哪一个predictor预测的bounding box与ground truth box的IOU最大,这个 predictor就负责 predict object。
这会使得每个predictor可以专门的负责特定的物体检测。随着训练的进行,每一个 predictor对特定的物体尺寸、长宽比的物体的类别的预测会越来越好。
标签:loss 消失 text 归一化 title 因此 local sso big
原文地址:https://www.cnblogs.com/VegBird/p/12433329.html