标签:alpha 编辑 https ror char 通过 span 图片 width
要识别的图片:

代码:
from PIL import Image import pytesseract text=pytesseract.image_to_string(Image.open(‘denggao.jpeg‘),lang=‘chi_sim‘) print(text)
效果截图:

主要步骤:
1.需要两个库:pytesseract和PIL
(1)可以通过命令行安装
pip install PIL
pip install pytesseract
(2)如果你用的pycharm编辑器,就可以直接借助pycharm实现快速安装。
在pycharm的Settings设置页按照下面步骤操作 :
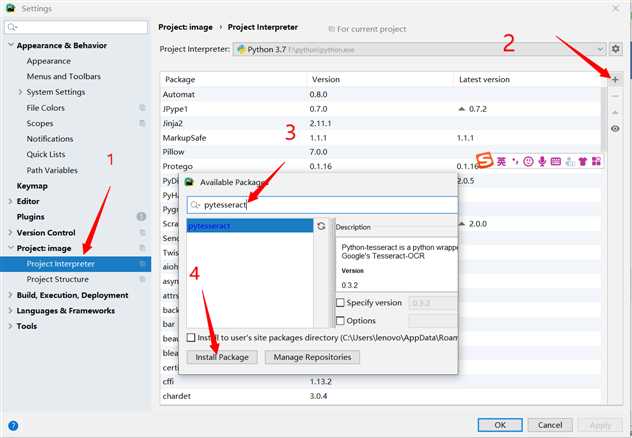
可以通过同样的步骤安装PIL
2.安装识别引擎tesseract-ocr
https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v5.0.0-alpha.20200223.exe
如有需求
附上各版本下载地址
https://github.com/UB-Mannheim/tesseract/wiki
3.识别中文,单独安装上识别引擎是无法识别中文的,需要另外下载一些东西
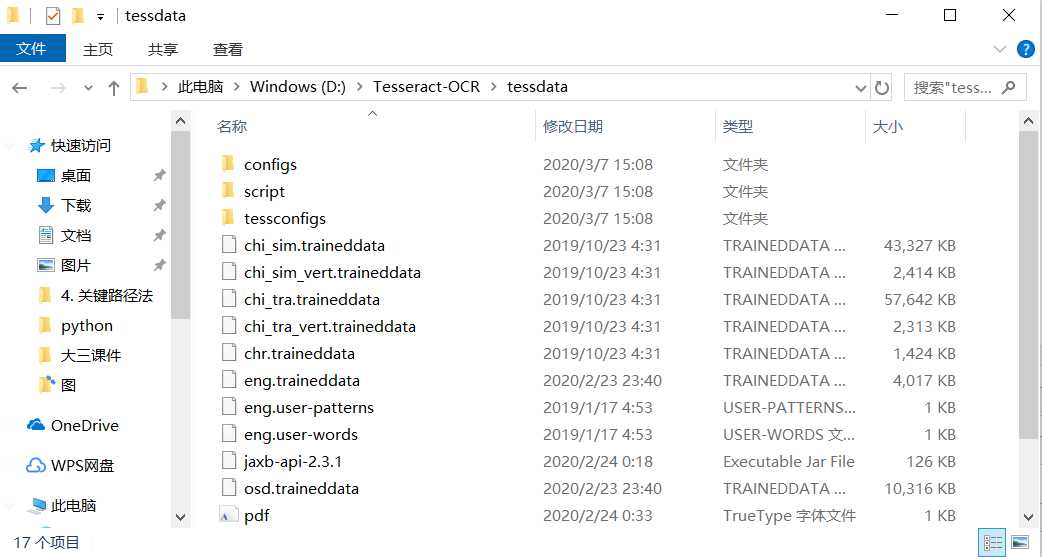
https://github.com/tesseract-ocr/tessdata
将里面的 chi_sim.traineddata、chi_sim_vert.traineddata、chi_tra.traineddata和chi_tra_vert.traineddata文件放入tesseract-ocr的tessdata目录下
4.修改pytesseract.py
到你的Python的Lib\site-packages\pytesseract中找到pytesseract.py并修改其中的tesseract_cmd
修改为:
tesseract_cmd = ‘D:/Tesseract-OCR/tesseract.exe‘
之后就可以运行了。
配置过程中遇到的错误:
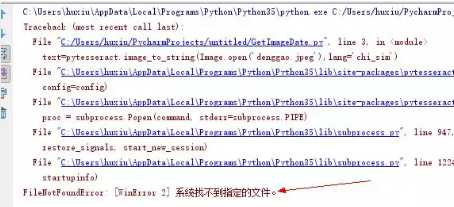
1.没有安装识别引擎会报这个错误:
2.识别引擎版本不对会报:
pytesseract.pytesseract.TesseractError: (1, "Error, unknown command line argument ‘-psm‘")
pytesseract+Tesseract-OCR图片文字识别
标签:alpha 编辑 https ror char 通过 span 图片 width
原文地址:https://www.cnblogs.com/liujinxin123/p/12434679.html