标签:red 而且 关联 第一步 独立 队列 文件中 角度 写入
零拷贝是网络传输当中很重要的一个概念,我们可以从Linux在网络传输中的设计变化中理解零拷贝的基本原理。
当服务器和客户端建立起socket连接之后,现在准备进行数据的传输。由于文件都存在于磁盘中,因此我们传输的流程是按照以下图一所示的过程进行传输的:
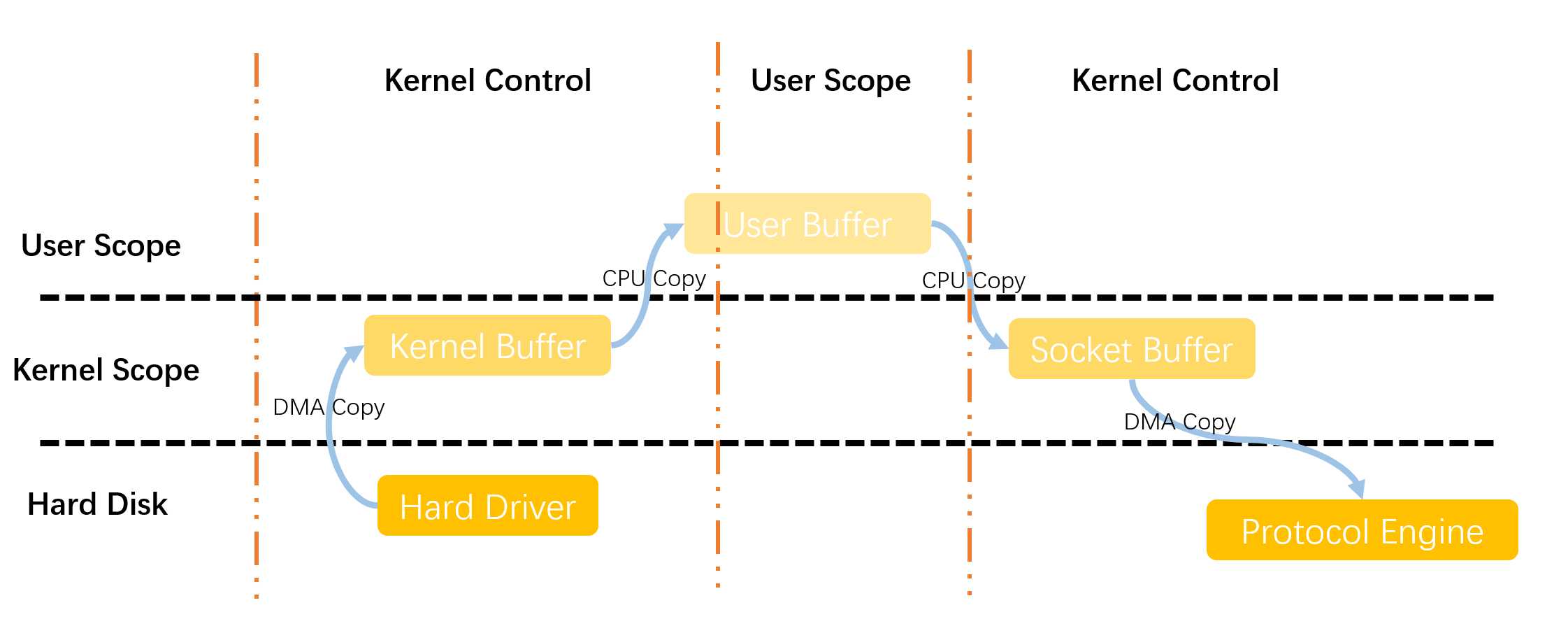
传统的数据传输是通过read和write这两个系统调用实现从磁盘中读取文件中的数据,以及将数据写入到到发送的通道中,因此我们解读以下上面图一究竟发生了什么:
- 由于用户使用read这个系统调用,导致操作系统由用户态切换至内核态的一次状态切换。在read系统调用中,首先文件从磁盘通过DMA的方式进行读取(读入到DMA中,内核缓冲区),完成一次DMA的复制
- 此时read系统调用返回,导致操作系统完成内核态切换至用户态的状态切换,同时读取的文件也会复制到用户态的缓冲区中,此时完成一次从内核缓冲区到用户缓冲区内的一次CPU复制。
- 此时用户使用write这个系统调用,有一次完成用户态切换至内核态的一次状态切换。在write系统调用中,将用户缓冲区的数据写入到内核态缓冲区,完成一次DMA的复制。不过这一次存放的缓冲区和第一步中存放的缓冲区不一样,这个缓冲区是专用的socket缓冲区
- 系统调用write返回,此时系统由内核态切换至用户态的切换。第四次复制发生在从socket内核缓冲区复制到协议引擎中的时候发生。(第四次复制发生的是过程实际上是和write是独立异步执行的!那么“为何要说是独立、异步?难道不是在write系统调用返回前数据已经被传送了?write系统调用的返回,并不意味着传输成功——它甚至无法保证传输的开始。调用的返回,只是表明以太网驱动程序在其传输队列中有空位,并已经接受我们的数据用于传输。可能有众多的数据排在我们的数据之前。除非驱动程序或硬件采用优先级队列的方法,各组数据是依照FIFO的次序被传输的)
总结以上的过程我们发现,使用传统的网络传输过程,经过了4次状态的切换,4次文件的复制(其中两次CPU复制两次DMA复制)。实际上从性能上来说,一次数据传输就消耗如此大,这样其实是有优化的空间的。
从以上的缺点我们可以看出,我们对于文件发送的流程优化可以考虑以下两方面——
这个思路上,可以采用其他的系统调用,让一次系统调用就能完成现在多个系统调用完成的事。
其实可以发现在这个发送文件的过程当中存在着很多完全一致的文件的副本,比如在write系统调用时,在用户空间的文件和socket缓冲区的文件是完全一致的。
面对以上发送数据时候出现的一些问题,MMAP解决问题的思路是从减少文件复制次数出发的。关于MMAP的想法是设置将内核缓冲区这一块地址设置为共享,那么这样一来,从内核缓冲区到用户缓冲区的文件复制这一步就减少了,以此进行优化。具体流程如下图所示。
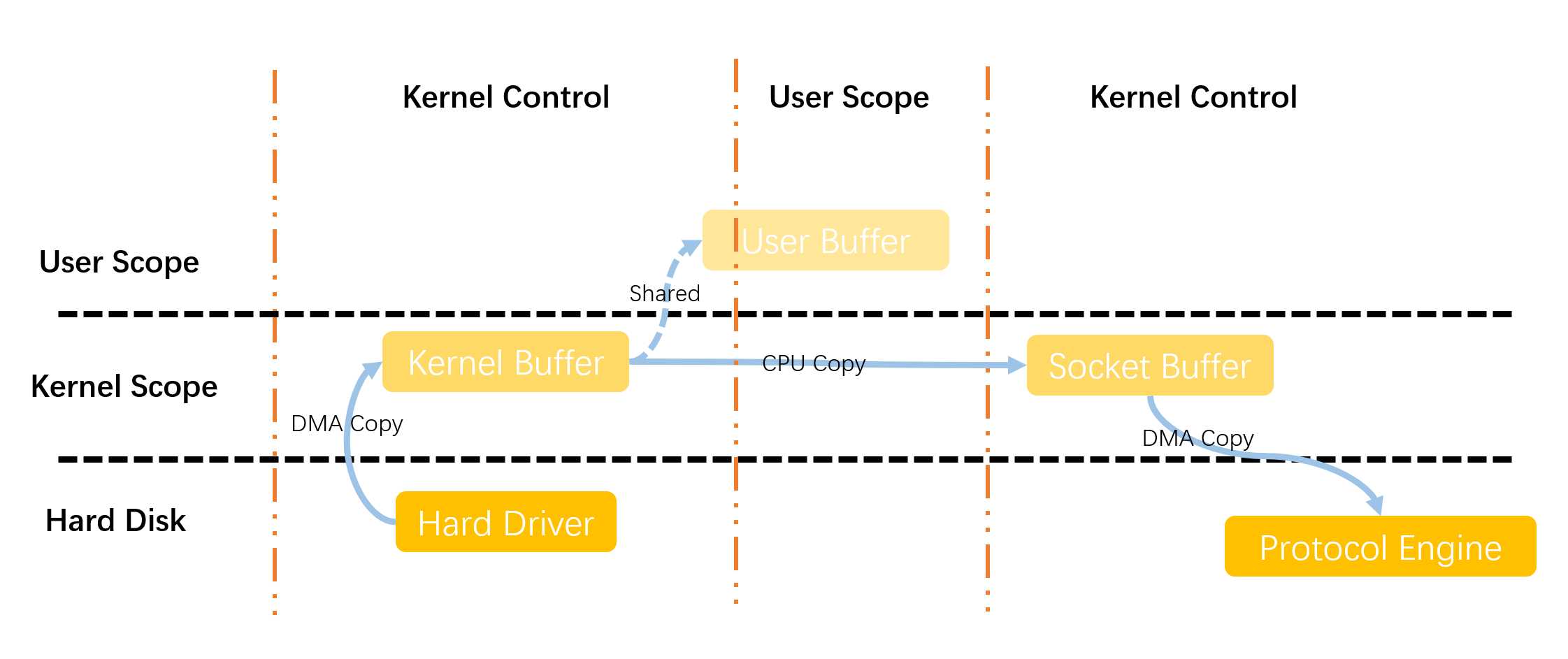
- 首先用户使用mmap系统调用,从用户态切换为内核态的一次状态切换。此时DMA会将磁盘中的内容读取到内核缓冲区中,完成一次DMA复制,然后将内核缓冲区中的文件和用户执行的进程进行关联
- 系统调用mmap返回,操作系统从内核态切换为用户态,然后此时用户缓冲区和内核缓冲区的文件共享数据。
- 对数据处理完成之后,用户开始调用write系统调用,操作系统从用户态切换为内核态。并将数据从内核态数据区直接复制到内核态socket缓冲区,完成一次CPU复制。
- 系统调用write返回,操作系统从内核态切换为用户态,数据从内核态socket缓冲区拷贝到协议引擎准备发送
总结以上的过程我们发现,使用mmap网络传输过程,经过了4次状态的切换,3次文件的复制(其中一次CPU复制两次DMA复制)。实际上从性能上来说,一次数据传输就消耗如此大,这样仍然是有优化的空间的。
那么MMAP是怎样做到将内核空间的缓冲区共享的呢?总体的思路是将文件的内存映射到进程地址空间中去,这样就实现了磁盘文件到进程地址空间中的一块地址区域一一对应,这样就让进程在访问文件的时候可以直接访问和修改文件,修改之后的脏数据将会被操作系统写回到文件磁盘中。同时磁盘文件的修改也会直接影响用户进程的访问。具体的对应关系如下:
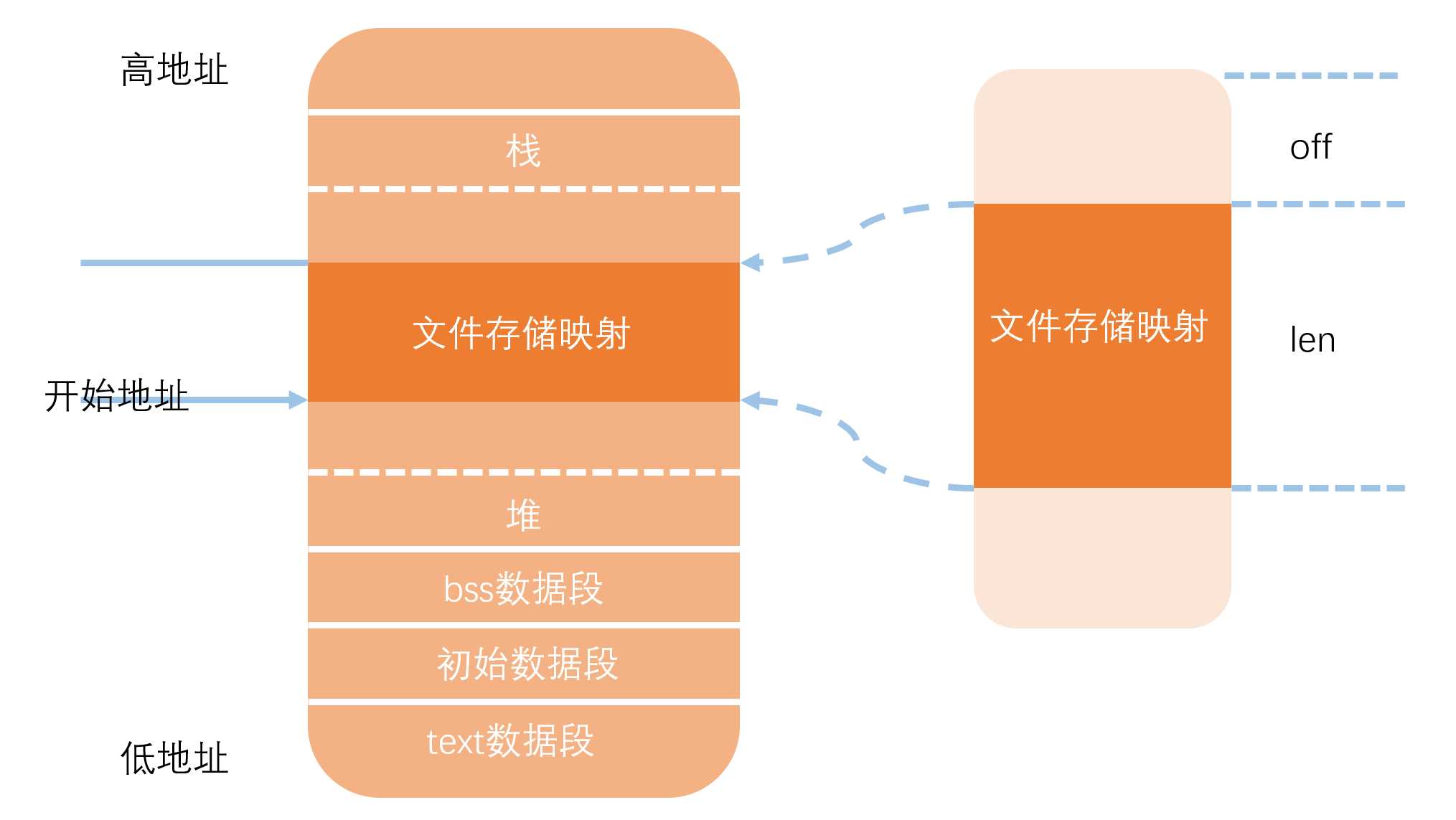
通过mmap系统调用实际上也就是通过文件共享的方式减少一次CPU复制,来提高文件传输的性能。但是这样处理也存在一些问题:
sendfile初始的思路是从减少上下文切换这一方面着手进行优化的,由于在传统的网络传输当中,使用到了read、write这两个系统调用,导致进程在执行过程中在用户态和内核态一直切换。因此sendfile将这两种系统调用直接和为一个sendfile,而且这种也同时减少了一次CPU复制。
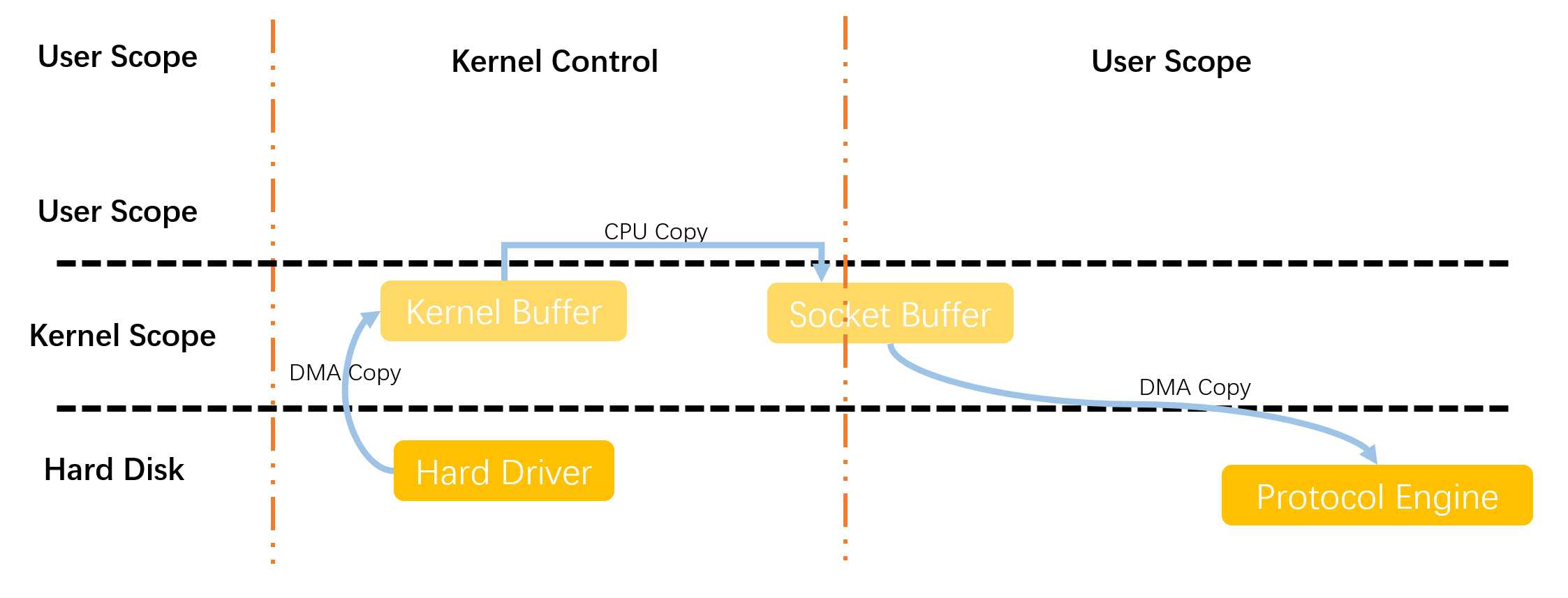
- 用户调用sendfile系统调用,完成一次从用户态到内核态的切换,将数据从磁盘通过DMA复制到内核缓冲区中,然后对数据进行处理之后将内核态的数据复制到socket缓冲区中
- 此时sendfile系统调用返回,完成一次从内核态到用户态的切换,并将socket缓冲区的数据复制到协议引擎中准备发送
由此看来,使用sendfile系统调用整体经过了2次状态的切换,3次文件的复制(其中一次CPU复制两次DMA复制)。
按理说事情到这里应该相当完美了,可是我们仔细分析一下上述的流程,不难发现其实在内核态中DMA缓冲区数据和socket缓冲区数据的文件内容一致的,这样说来也就是说,在这个过程当中那一次CPU也是多余的。
这里可以说一下为什么2.4之前的Linux版本需要多出的这一次CPU复制呢,其实这个很大程度上是受限于当时的硬件水平,当时的网络适配器不支持聚合操作,准确来说,就是传给socket缓冲区的必须是一个连续地址块的内容,而不能是分散的,因此需要这一次CPU复制将散落在内核中各处的文件聚合起来;在2.4版本之后网络适配器支持了聚合操作,那么在此基础之上linux的socket描述符也做了相应的改变以适应新的硬件特性
linux2.4版本后的sendfile流程如下——
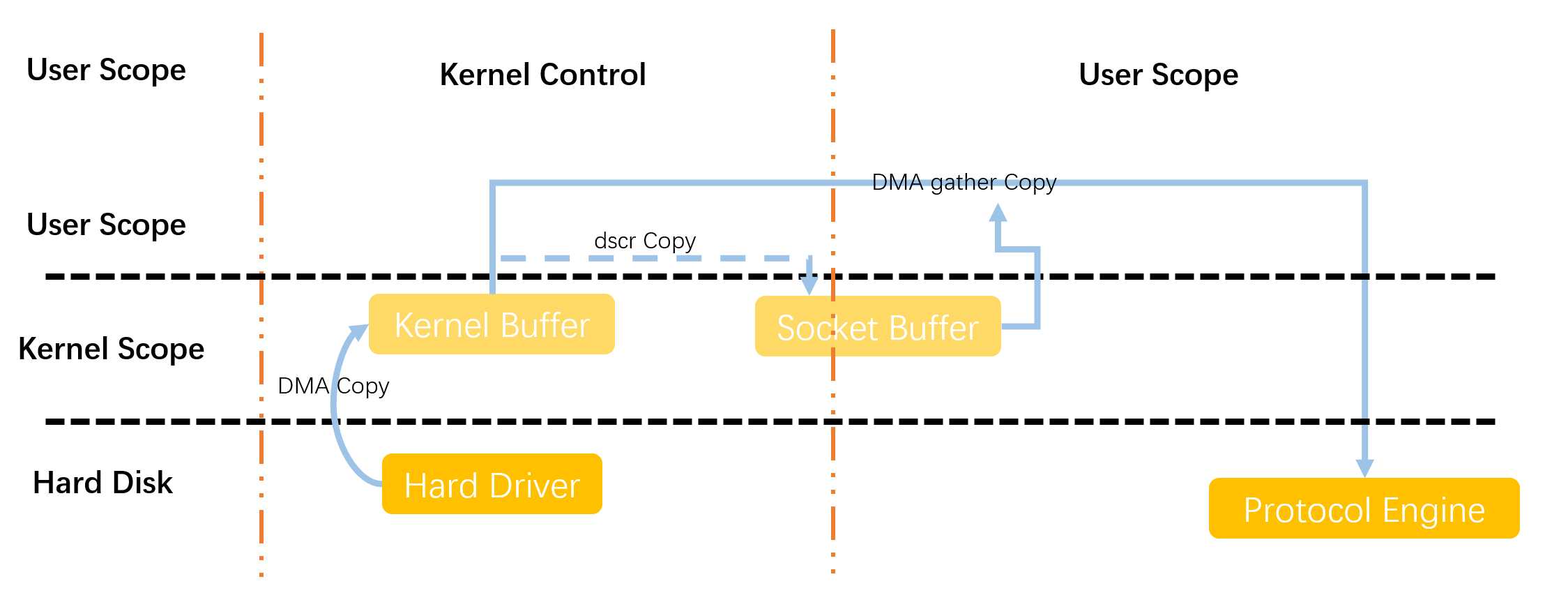
从图五中可以看出,简化了图四将DMA缓冲区复制到用户缓冲区的流程,而是只将文件中一些基本的属性和描述字段复制到socket缓冲区中,然后通过socket描述符的聚集功能完成文件的搜集。至此,已经完成零拷贝的设计。
可能大家会有疑问,为什么”零拷贝“的设计里面还是包含了两次DMA拷贝和一次文件的描述拷贝?其实这里所说的”零拷贝“是从操作系统的角度来说的,对于操作系统而言,在网络传输的流程当中不存在两个完全一样的文件,实际上就是零拷贝。
零拷贝带来的性能优势主要是以下几个方面——
标签:red 而且 关联 第一步 独立 队列 文件中 角度 写入
原文地址:https://www.cnblogs.com/micadai/p/12434664.html