标签:数据库 分布式文件系 要求 基于 长度 image 质量 form 网上
在PaaS层中一个复杂的通用应用就是大数据平台。大数据是如何一步一步融入云计算的呢?
数据都包含智慧 一开始这个大数据并不大。原来才有多少数据?现在大家都去看电子书,上网看新闻了,在我们80后小时候,信息量没有那么大,也就看看书、看看报,一个星期的报纸加起来才有多少字?如果你不在一个大城市,一个普通的学校的图书馆加起来也没几个书架,是后来随着信息化的到来,信息才会越来越多。
首先我们来看一下大数据里面的数据,就分三种类型,一种叫结构化的数据,一种叫非结构化的数据,还有一种叫半结构化的数据。
其实数据本身不是有用的,必须要经过一定的处理。例如你每天跑步带个手环收集的也是数据,网上这么多网页也是数据,我们称为Data。数据本身没有什么用处,但数据里面包含一个很重要的东西,叫做信息(Information)。
数据十分杂乱,经过梳理和清洗,才能够称为信息。信息会包含很多规律,我们需要从信息中将规律总结出来,称为知识(Knowledge),而知识改变命运。信息是很多的,但有人看到了信息相当于白看,但有人就从信息中看到了电商的未来,有人看到了直播的未来,所以人家就牛了。如果你没有从信息中提取出知识,天天看朋友圈也只能在互联网滚滚大潮中做个看客。
有了知识,然后利用这些知识去应用于实战,有的人会做得非常好,这个东西叫做智慧(Intelligence)。有知识并不一定有智慧,例如好多学者很有知识,已经发生的事情可以从各个角度分析得头头是道,但一到实干就歇菜,并不能转化成为智慧。而很多的创业家之所以伟大,就是通过获得的知识应用于实践,最后做了很大的生意。
所以数据的应用分这四个步骤:数据、信息、知识、智慧。
最终的阶段是很多商家都想要的。你看我收集了这么多的数据,能不能基于这些数据来帮我做下一步的决策,改善我的产品。例如让用户看视频的时候旁边弹出广告,正好是他想买的东西;再如让用户听音乐时,另外推荐一些他非常想听的其他音乐。
用户在我的应用或者网站上随便点点鼠标,输入文字对我来说都是数据,我就是要将其中某些东西提取出来、
指导实践、形成智慧,让用户陷入到我的应用里面不可自拔,上了我的网就不想离开,手不停地点、不停地买。
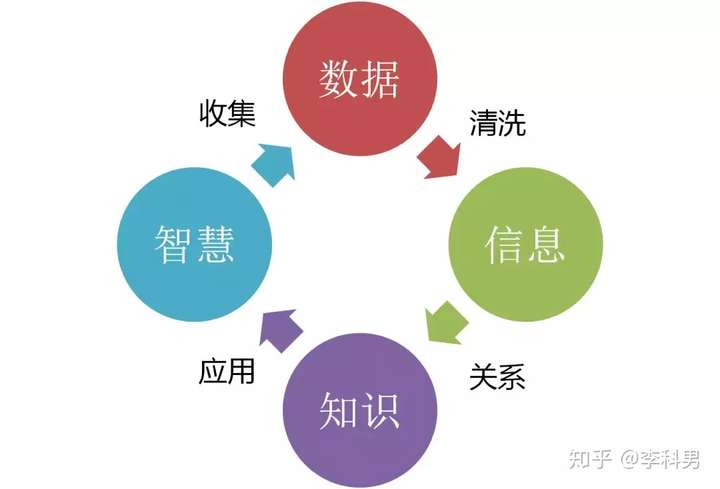
数据如何升华为智慧? 数据的处理分几个步骤,完成了才最后会有智慧。
第一个步骤叫数据的收集。首先得有数据,数据的收集有两个方式:
第二个步骤是数据的传输。一般会通过队列方式进行,因为数据量实在是太大了,数据必须经过处理才会有用。可系统处理不过来,只好排好队,慢慢处理。
第三个步骤是数据的存储。现在数据就是金钱,掌握了数据就相当于掌握了钱。要不然网站怎么知道你想买什么?就是因为它有你历史的交易的数据,这个信息可不能给别人,十分宝贵,所以需要存储下来。
第四个步骤是数据的处理和分析。上面存储的数据是原始数据,原始数据多是杂乱无章的,有很多垃圾数据在里面,因而需要清洗和过滤,得到一些高质量的数据。对于高质量的数据,就可以进行分析,从而对数据进行分类,或者发现数据之间的相互关系,得到知识。
比如盛传的沃尔玛超市的啤酒和尿布的故事,就是通过对人们的购买数据进行分析,发现了男人一般买尿布的时候,会同时购买啤酒,这样就发现了啤酒和尿布之间的相互关系,获得知识,然后应用到实践中,将啤酒和尿布的柜台弄的很近,就获得了智慧。
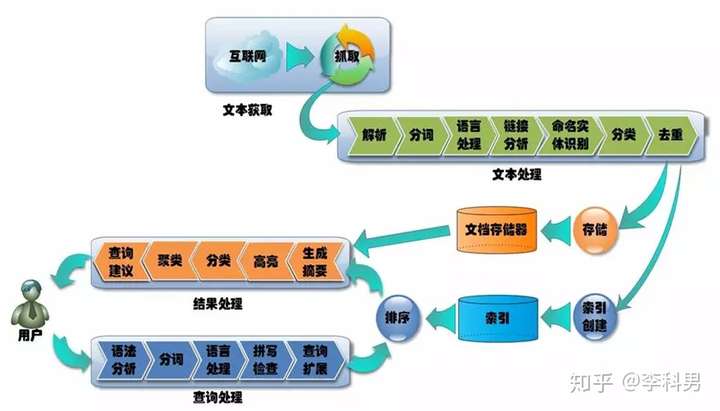
第五个步骤是对于数据的检索和挖掘。检索就是搜索,所谓外事不决问Google,内事不决问百度。内外两大搜索引擎都是将分析后的数据放入搜索引擎,因此人们想寻找信息的时候,一搜就有了。
另外就是挖掘,仅仅搜索出来已经不能满足人们的要求了,还需要从信息中挖掘出相互的关系。比如财经搜索,当搜索某个公司股票的时候,该公司的高管是不是也应该被挖掘出来呢?如果仅仅搜索出这个公司的股票发现涨的特别好,于是你就去买了,其实其高管发了一个声明,对股票十分不利,第二天就跌了,这不坑害广大股民么?所以通过各种算法挖掘数据中的关系,形成知识库,十分重要。
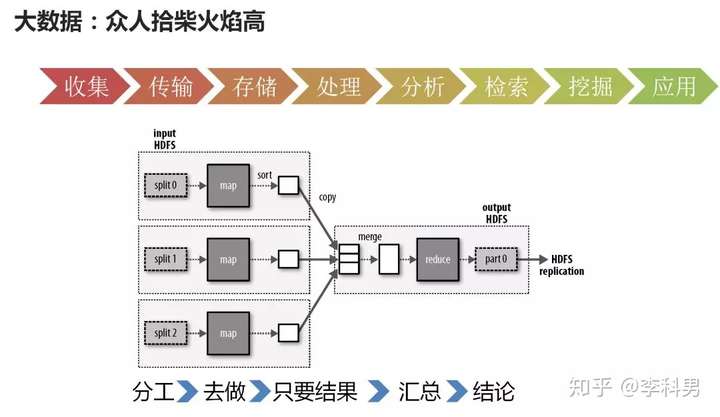
大数据时代,众人拾柴火焰高 当数据量很小时,很少的几台机器就能解决。慢慢的,当数据量越来越大,最牛的服务器都解决不了问题时,怎么办呢?这时就要聚合多台机器的力量,大家齐心协力一起把这个事搞定,众人拾柴火焰高。
对于数据的收集:就IoT来讲,外面部署这成千上万的检测设备,将大量的温度、湿度、监控、电力等数据统统收集上来;就互联网网页的搜索引擎来讲,需要将整个互联网所有的网页都下载下来。这显然一台机器做不到,需要多台机器组成网络爬虫系统,每台机器下载一部分,同时工作,才能在有限的时间内,将海量的网页下载完毕。
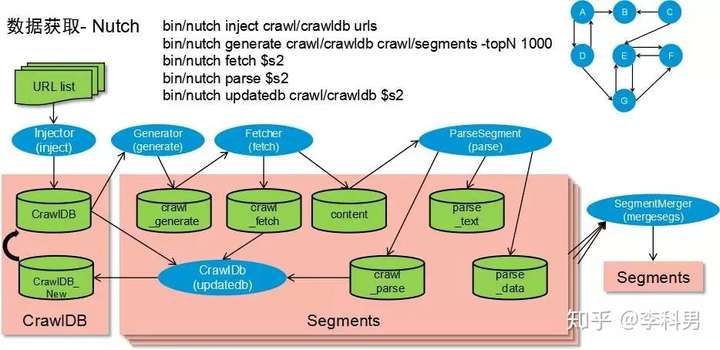
对于数据的传输:一个内存里面的队列肯定会被大量的数据挤爆掉,于是就产生了基于硬盘的分布式队列,这样队列可以多台机器同时传输,随你数据量多大,只要我的队列足够多,管道足够粗,就能够撑得住。
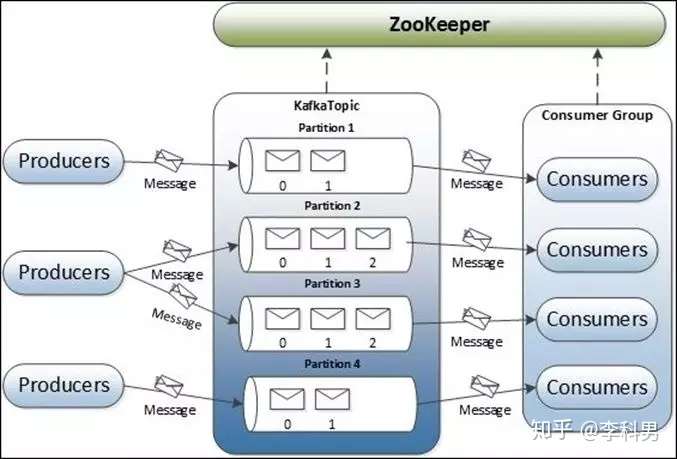
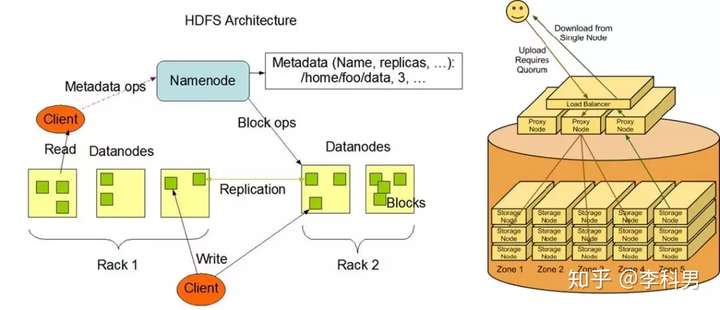
对于数据的存储:一台机器的文件系统肯定是放不下的,所以需要一个很大的分布式文件系统来做这件事情,把多台机器的硬盘打成一块大的文件系统。
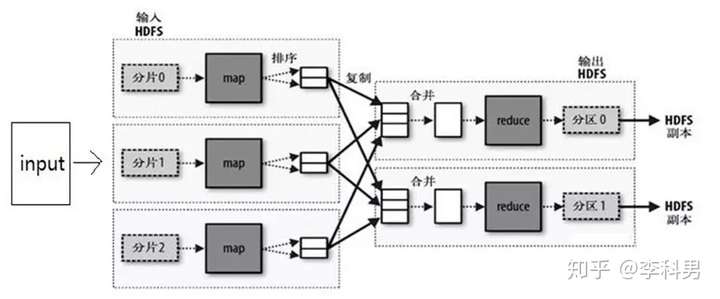
对于数据的分析:可能需要对大量的数据做分解、统计、汇总,一台机器肯定搞不定,处理到猴年马月也分析不完。于是就有分布式计算的方法,将大量的数据分成小份,每台机器处理一小份,多台机器并行处理,很快就能算完。例如著名的Terasort对1个TB的数据排序,相当于1000G,如果单机处理,怎么也要几个小时,但并行处理209秒就完成了。
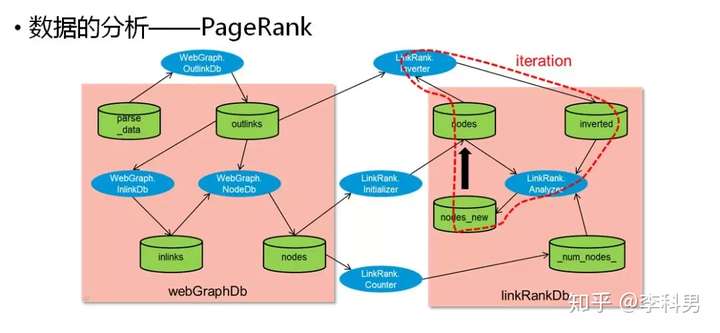
这些都是大数椐处理分析的工具。 所以说什么叫做大数据?说白了就是一台机器干不完,大家一起干。可是随着数据量越来越大,很多不大的公司都需要处理相当多的数据,这些小公司没有这么多机器可怎么办呢?
大数据需要云计算,云计算需要大数据
说到这里,大家想起云计算了吧。当想要干这些活时,需要很多的机器一块做,真的是想什么时候要就什么时候要,想要多少就要多少。
例如大数据分析公司的财务情况,可能一周分析一次,如果要把这一百台机器或者一千台机器都在那放着,一周用一次非常浪费。那能不能需要计算的时候,把这一千台机器拿出来;不算的时候,让这一千台机器去干别的事情?
谁能做这个事儿呢?只有云计算,可以为大数据的运算提供资源层的灵活性。而云计算也会部署大数据放到它的PaaS平台上,作为一个非常非常重要的通用应用。因为大数据平台能够使得多台机器一起干一个事儿,这个东西不是一般人能开发出来的,也不是一般人玩得转的,怎么也得雇个几十上百号人才能把这个玩起来。
所以说就像数据库一样,其实还是需要有一帮专业的人来玩这个东西。现在公有云上基本上都会有大数据的解决方案了,一个小公司需要大数据平台的时候,不需要采购一千台机器,只要到公有云上一点,这一千台机器都出来了,并且上面已经部署好了的大数据平台,只要把数据放进去算就可以了。
云计算需要大数据,大数据需要云计算,二者就这样结合了。
当然,现在的云计算各类也越来越多,有GPU云计算,FPGA云计算等,它们可以用来做机器学习,深度神经网络,并提供很多人工智能的服务,下一篇科普就介绍机器学习,神经网络,人工智能。
转载自:https://zhuanlan.zhihu.com/p/46827937
标签:数据库 分布式文件系 要求 基于 长度 image 质量 form 网上
原文地址:https://www.cnblogs.com/approx/p/12436717.html