标签:man 流式计算 bigdata 解决方案 服务器 分布式文件系统 配置 图片 --
Kafka是一种计算框架,结合了之前的MapReduce批处理和流式计算为一体,可以处理历史数据和实时数据。
流平台具有三个关键功能:
Kafka通常用于两大类应用程序:
另外几个概念:
Kafka提供了四个核心API:
Topics and Logs(主题和日志)
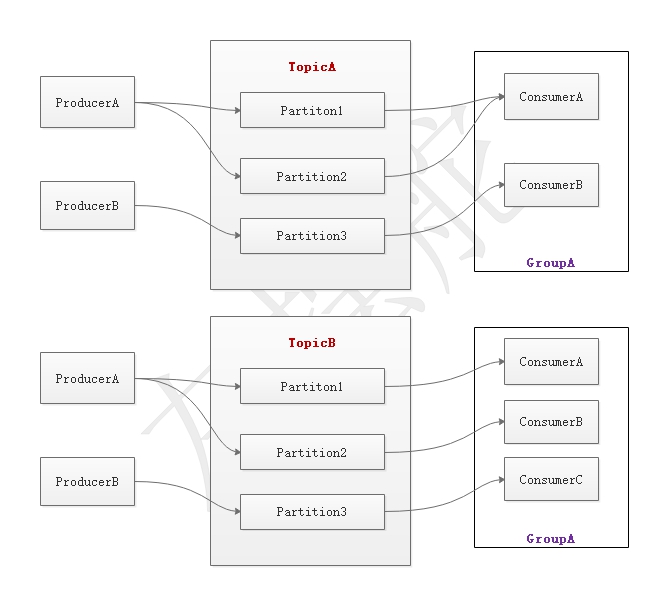
一个Topic有0个,1个或多个订阅者。一个Topic有1个或多个分区。另外还有个任务概念,每个任务可以处理多个分区。如下图所示:
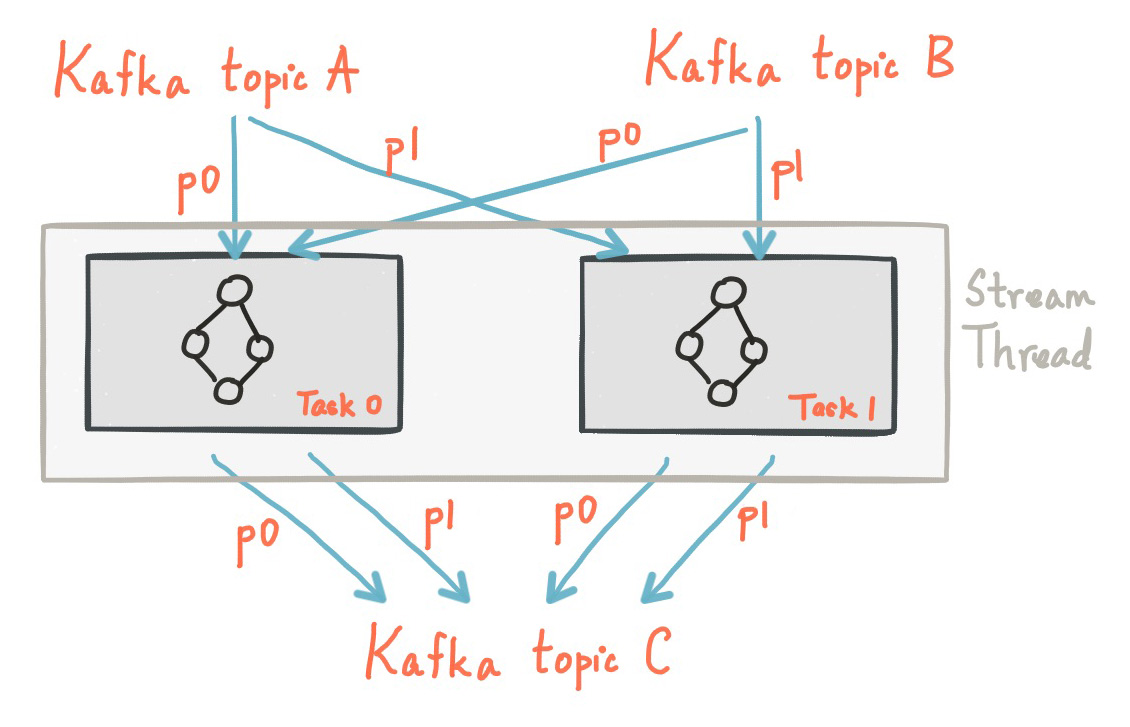
每个Topic维护着一个有序的Log,订阅者根据自己记录的偏移量来灵活读取Log。
Distribution
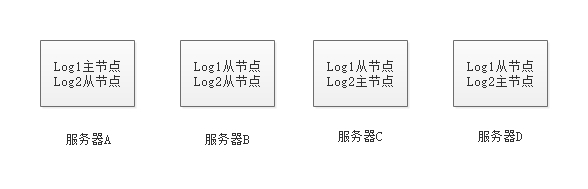
每个Log有一个主节点和多个从节点,这些节点分布到不同机器上,从节点同步主节点内容,当主节点挂了,会从从节点里面选取一个主节点继续运行。每个主节点机器上同时分布着其它机器的从节点,同时主节点也分布着其它Log的主节点,画个图脑补下:
Geo-Replication(地理复制)
要保证Kafka可靠,可以将服务部署到多个省,多个国家的云中心,在出问题的时候方便恢复。
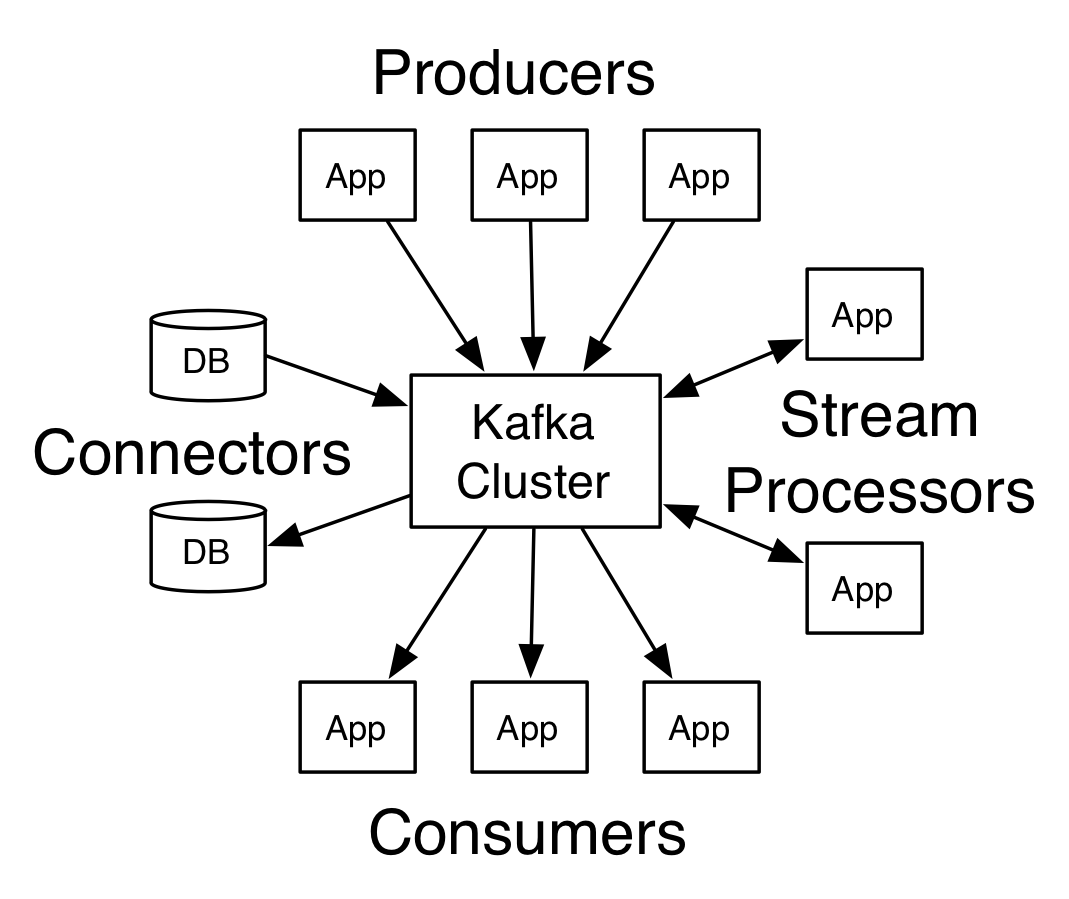
Producers(生产者)
Producer负责将数据发送到Topic里面。
Consumers(消费者)
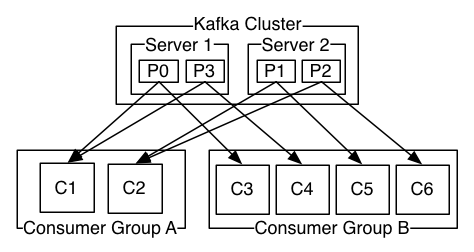
这里有个Consumer Group概念,每个Consumer Group里面有多个Consumer,Consumer Group负责订阅分区消息,并分配给Consumer。
Multi-tenancy(多租户)
可以制定一个多租户解决方案,通过配置哪些主题可以生成或消耗数据来启用多租户。
Guarantees(担保)
Kafka通过顺序的记录日志和允许n-1台服务器挂掉来保障服务的稳定。
Kafka as a Messaging System(Kafka作为消息传递系统)
Kafka同时兼容了队列传递和发布订阅传递。并且通过分区机制可以有序并行的给消费者分发消息。
Kafka as a Storage System(Kafka作为存储系统)
任何消费订阅消息都能存储到Kafka里面,并分发备份到不同机器上。所以Kafka可以看作是一种高性能,低延迟,日志存储的分布式文件系统。
Kafka for Stream Processing(用于流处理的Kafka)
Kafka不仅可以进行写入,读取和存储,还可以进行实时的流处理。简单的通过发布订阅APIs就能进行处理,复杂的有专门的 Streams API.
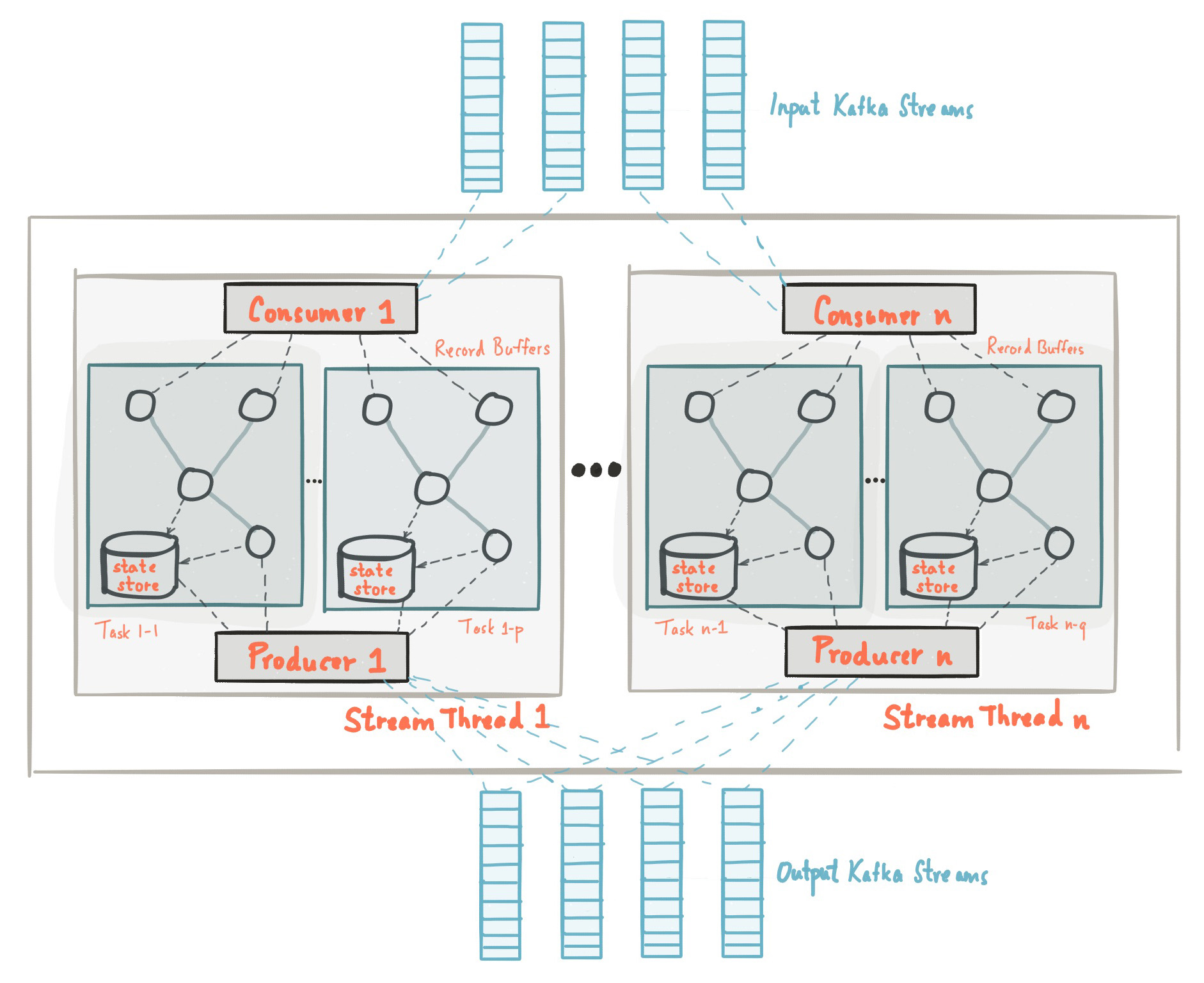
Putting the Pieces Together(把多种方案汇聚一身)
Kafka汇聚了队列,发布订阅,批处理,流处理和分布式存储技术。可以说很厉害。
标签:man 流式计算 bigdata 解决方案 服务器 分布式文件系统 配置 图片 --
原文地址:https://www.cnblogs.com/shun7man/p/12436729.html