标签:视图 数值 索引 输入 信号 时钟 disable default 十六
[toc]
数字电路系统设计:
Verilog HDL和VHDL的比较:
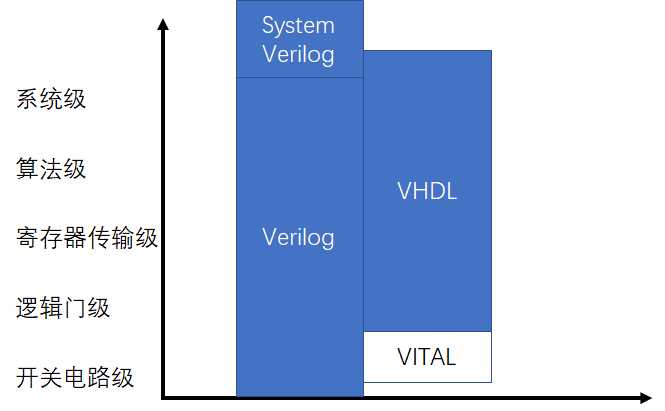
重点是Verilog简单啊,入门容易。
逻辑网表EDIF:
EDIF是电子设计交换格式(Electronic Design Interchange Format)的英文字头缩写。
EDIF综合了多种格式中的最佳特性,1985年的EDIF100版本提供了门阵列、半导体集成电路设计和布线自动化交换信息的格式,而后的EDIF200版本是不同EDA厂家之间交换设计数据的标准格式。CAD框架标准解决的是不同EDA厂家工具集成和实时通信问题,EDIF格式解决的是用不同EDA厂家工具完成设计的数据交流问题。
EDIF文件包含一系列的库(libraries),每个库包含一系列的单元(cells),每个单元具有1个或多个视图(views)。
这块不禁让人向导Concept HDL啊,library、cell、views。不会之前好难,会了之后真香。
视图使用原理图(Schematic)、版图(layout)、行为(Behaviour)和文档(Document)等格式(View Type)来描述。每个视图具有一个接口(interface)和一个内容(contents),通过它们来清晰定义视图。Cell单元还通过(view map)属性和其他View视图相连。
HDL设计流程图:
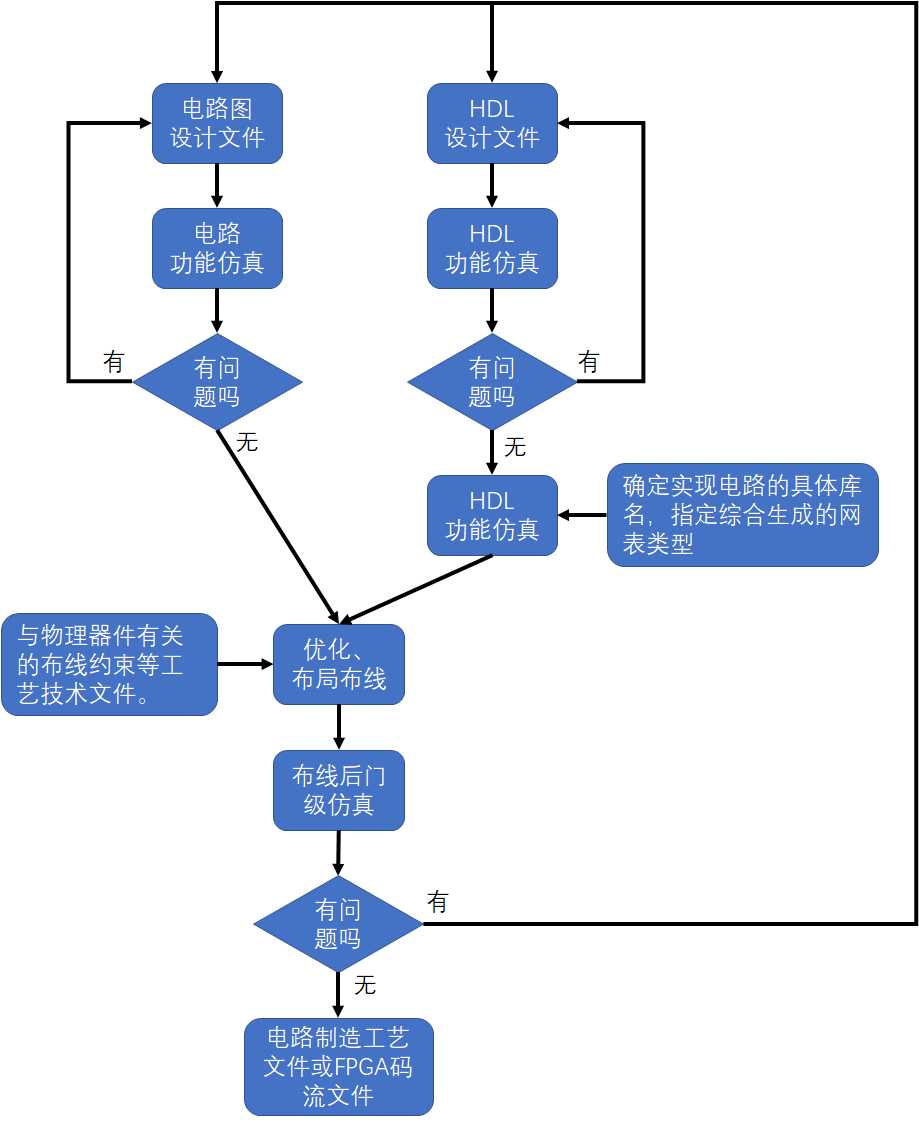
Verilog既是一种行为描述语言,也是一种结构描述语言。
Verilog模型:
Verilog模型可以是实际电路的不同级别的抽象,这些抽象的级别和他们所对应的模型类型共有以下五种。
Verilog语言本身非常适合算法级和RTL级的模型设计。
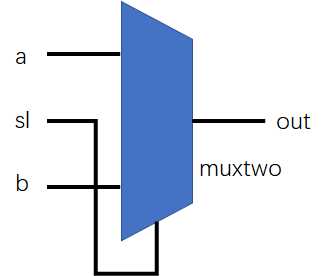
示例1
module muxtwo(out,a,b,sl)
input a,b,sl;
output out;
reg out;
always@(sl or a or b)
if (! sl) out = a;
else out =b;
endmodule
示例2
module muxtwo(out,a,b,sl)
input a,b,sl;
output out;
wire nsl,sela,selb;
assign nsl = ~sl;//阻塞赋值
assign sela = a&nsl;
assign selb = b&sl;
assign out = sela|selb;
endmodule
wire型变量赋值表示某个逻辑输出连接到这个线上面了。
wire形变量,体现了Verilog结构描述的部分。
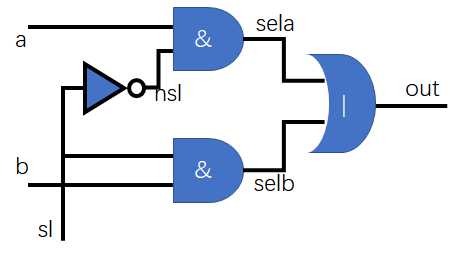
示例3
module muxtwo(out,a,b,sl)
input a,b,sl;
output out;
not u1(nsl,sl);
and #1 u2(sela,a,nsl);
and #2 u3(selb,b,sl);
or #3 u4(out,sela,selb);
endmodule
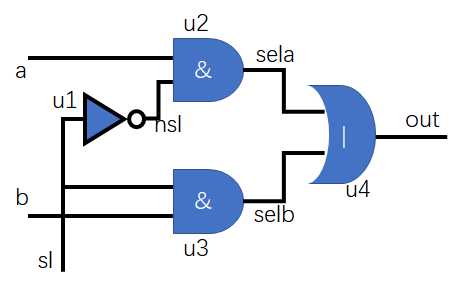
把示例1或者示例2转换为示例3的过程成为综合,示例3很容易跟某种工艺基本元件对应起来。
后续需要理解的部分:
- 符合何种风格的Verilog模块是可以综合的。
- 何种风格的模块是不可以综合的。
- 不可以综合的Verilog模块有什么作用等。
前面讲过,综合后产生门级电路网表,
示例4
module adder(cout,sum,a,b,cin);
input [2:0] a,b;//[MSB:LSB],所以是3bit
input cin;
output cout;
output [2:0] sum;
assign {cout,sum} = a+b+cin;
//{,}是什么运算符?起拼接的作用 如 a = {b[5],b[4:0]},意思为 b的最高位和b的低五位拼接起来,组成的a为6位
endmodule
做了一个3bit的加法器。
示例5
module compare(equal,a,b);
output equal;
input [1:0] a,b;//[MSB:LSB],所以是2bit
assign equal = (a==b)?1:0;
/*如果a、b两个输入信号相等,输出为1,否则为0*/
endmodule
做了一个2bit数比较器。
示例6
module trist2(out,in,enable);
output out;
input in,enable;
bufif1 mybuf(out,in.enable);
endmodule
pic need to be inserted
内部套了一个实例化的三态门选择器,
示例7
module trist1(sout,sin,ena);
output sout;
input sin,ena;
mytri tri_inst(.out(sout),.in(sin),.enable(ena));
endmodule
module mytri(out,in,enable);
output out;
input in,enable;
assign out = enable?in:‘bz;//‘bz是高阻?
endmodule
模块引用示例,.表示被引用模块的端口。名称必须与被引用模块的端口定义一致,小括号中表示与该端口连接的线路(wire型变量)。
以上三个例子都是可以综合的。
Verilog的基本设计单元是“模块”(block)。一个模块是由两部分组成的,一部分描述接口,另一部分描述逻辑功能,即定义输入是如何影响输出的。栗子如下:
module block (a,b,c,d);
input a,b;
output c,d;
assign c= a | b ;
assign d= a & b;
endmodule
模块的端口声明了模块的输入输出口。其格式如下: module 模块名(口1,口2,口3,口4, ………);
模块的内容包括I/O说明、内部信号声明、功能定义。
I/O说明的格式如下:
module module_name(input port1,input port2,…output port1,output port2… );
内部信号说明:
reg [width-1 : 0] R变量1,R变量2 。。。。;
wire [width-1 : 0] W变量1,W变量2 。。。。;
功能定义:
模块中最重要的部分是逻辑功能定义部分。有三种方法可在模块中产生逻辑。
用“assign”声明语句,如:
assign a = b & c;
用实例元件,如:
and and_inst( q, a, b );
用“always”块,如:
always @(posedge clk or posedge clr)
begin
if(clr) q <= 0;
else if(en) q <= d;
end
四种基本数据类型:
数字
整数
整数常量的四种表示形式:
- 二进制整数(b或B)
- 十进制整数(d或D)
- 十六进制整数(h或H)
- 八进制整数(o或O)
实际上常用的知识前三种。。
数字表达方式:
- <位宽><进制><数字>这是一种全面的描述方式。
- <进制><数字>在这种描述方式中,数字的位宽采用缺省位宽(这由具体的机器系统 决定,但至少32位)。
- <数字>在这种描述方式中,采用缺省进制十进制。
x和z值
在数字电路中,x代表不定值,z代表高阻值。一个x可以用来定义十六进制数的四位二进制数的状态,八进制数的三位,二进制数的一位。z的表示方式同x类似。z还有一种表达方式是可以写作?。在使用case表达式时建议使用这种写法,以提高程序的可读性。见下例:
4‘b10x0 //位宽为4的二进制数从低位数起第二位为不定值 4‘b101z //位宽为4的二进制数从低位数起第一位为高阻值 12‘dz //位宽为12的十进制数其值为高阻值(第一种表达方式) 12‘d? //位宽为12的十进制数其值为高阻值(第二种表达方式) 8‘h4x //位宽为8的十六进制数其低四位值为不定值
对于0、x、z,可以表示十进制数的全部位;赋全0、全x或者全z可采用‘b0、‘bx或者‘bz的方式;
顺带,说道赋值,赋全1可采用赋~0或赋-1的方式较为简洁。
负数
一个数字可以被定义为负数,只需在位宽表达式前加一个减号,减号必须写在数字定义表达式的最前 面。注意减号不可以放在位宽和进制之间也不可以放在进制和具体的数之间。见下例:
-8‘d5 //这个表达式代表5的补数(用八位二进制数表示) 8‘d-5 //非法格式
下划线
下划线可以用来分隔开数的表达以提高程序可读性。但不可以用在位宽和进制处,只能用在具体的数 字之间。见下例:
16‘b1010_1011_1111_1010 //合法格式 8‘b_0011_1010 //非法格式
参数(parameter)型
看着类似宏定义!!不太一样,可以使用#()将参数传递到module里面。
在Verilog HDL中用parameter来定义常量,parameter型数据是一种常数型的数据,其说明格式如下:
parameter 参数名1=表达式,参数名2=表达式, …, 参数名n=表达式;
模块间传递参数:
module Decode(A,F);
parameter Width=1, Polarity=1;
……………
endmodule
module Top;
wire[3:0] A4;
wire[4:0] A5;
wire[15:0] F16;
wire[31:0] F32;
Decode #(4,0) D1(A4,F16);//其中的#(4,0)向实例化的Decode模块内部传递两个参数值
Decode #(5) D2(A5,F32);//其中的#(5)向实例化的Decode模块内部传递一个参数值
endmodule
神奇!defparam语句在一个模块中改变另一个模块的参数:
module Test;
wire W;
Top T ( );
endmodule
module Top;
wire W
Block B1 ( );
Block B2 ( );
endmodule
module Block;
Parameter P = 0;
endmodule
module Annotate;
defparam//Test模块里面实例化了一个Top模块为T,T里面实例化的Block模块B1、B2里面的参数都可以更改;
//注意原始的模块原型prototype申明里面的参数未改动
Test.T.B1.P = 2,
Test.T.B2.P = 3;
endmodule
两个驱动源的表格:
| wire/tri | 0 | 1 | x | z |
|---|---|---|---|---|
| 0 | 0 | x | x | 0 |
| 1 | x | 1 | x | 1 |
| x | x | x | x | x |
| z | 0 | 1 | x | z |
wire型
wire型数据常用来表示用于以assign关键字指定的组合逻辑信号。Verilog程序模块中输入输出信号类型缺省时自动定义为wire型。wire型信号可以用作任何方程式的输入,也可以用作“assign”语句或实例元件的输出。
wire型信号的格式同reg型信号的很类似。其格式如下:
wire [n-1:0] 数据名1,数据名2,…数据名i; //共有i条总线,每条总线内有n条线路
wire [n:1] 数据名1,数据名2,…数据名i;
栗子:
wire a; //定义了一个一位的wire型数据
wire [7:0] b; //定义了一个八位的wire型数据
wire [4:1] c, d; //定义了二个四位的wire型数据
reg型
寄存器是数据储存单元的抽象。reg类型数据的缺省初始值为不定值,x。
reg型数据常用来表示用于 “always”模块内的指定信号, 常代表触发器。 通常, 在设计中要由“always”块通过使用行为描述语句来表达逻辑关系。在“always”块内被赋值的每一个信号都必须定义成reg型。
reg型数据的格式如下:
reg [n-1:0] 数据名1,数据名2,… 数据名i;
reg [n:1] 数据名1,数据名2,… 数据名i;
栗子
reg rega; //定义了一个一位的名为rega的reg型数据
reg [3:0] regb; //定义了一个四位的名为regb的reg型数据
reg [4:1] regc, regd; //定义了两个四位的名为regc和regd的reg型数据
memory型
当一个reg型数据是一个表达式中的操作数时,它的值被当作是无符号值,即正值。例如:当一个四位的寄存器用作表达式中的操作数时,如果开始寄存器被赋以值-1,则在表达式中进行运算时,其值被认为是+15。
数组中的每一个单元通过一个数组索引进行寻址。在Verilog语言中没有多维数组存在。其格式如下:
reg [n-1:0] 存储器名[m-1:0];
reg [n-1:0] 存储器名[m:1];
算术运算符:+、-、*、/、%
取反~
| 原bit | ~原bit |
|---|---|
| 0 | 1 |
| 1 | 0 |
| x | x |
按位与&
| & | 0 | 1 | x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | x |
| x | 0 | x | x |
按位或|
| | | 0 | 1 | x |
|---|---|---|---|
| 0 | 0 | 1 | x |
| 1 | 1 | 1 | 1 |
| x | x | 1 | x |
按位异或^(XOR)
| ^ | 0 | 1 | x |
|---|---|---|---|
| 0 | 0 | 1 | x |
| 1 | 1 | 0 | x |
| x | x | x | x |
按位同或^~
| ^~ | 0 | 1 | x |
|---|---|---|---|
| 0 | 1 | 0 | x |
| 1 | 0 | 1 | x |
| x | x | x | x |
不同长度的数据进行位运算
自动的将两者按右端对齐.位数少的操作数会在相应的高位用0填满,以使两个操作数按位进行操作.
逻辑运算符:!、&&、||
逻辑运算符中"&&"和"||"的优先级别低于关系运算符,"!" 高于算术运算符。不确定的加括号准没错。
关系运算符:>、<、>=、<=。
等式运算符: ==、!、===、!==
Case等式运算符:
| === | 0 | 1 | x | z |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 |
| x | 0 | 0 | 1 | 0 |
| z | 0 | 0 | 0 | 1 |
逻辑等式运算符:
| == | 0 | 1 | x | z |
|---|---|---|---|---|
| 0 | 1 | 0 | x | x |
| 1 | 0 | 1 | x | x |
| x | x | x | x | x |
| z | x | x | x | x |
a >> n 或 a << n;
a代表要进行移位的操作数,n代表要移几位。这两种移位运算都用0来填补移出的空位。
位拼接运算符;
{信号1的某几位,信号2的某几位,..,..,信号n的某几位}
位拼接还可以用重复法来简化表达式。见下例:
{4} //这等同于{w,w,w,w}
栗子:
reg [3:0] B;
reg C;
C = &B;
//相当于:
C =( (B[0]&B[1]) & B[2] ) & B[3];
略
略
两种赋值方式:
verilog主要的模块之间都是并行执行的,例如各个always之间、always与assign之间、assign之间,如果你在一个always中要对a赋值,而在另一个always中要使用a的值,这时候就要注意了,两者并行的,处理先后不能确定。
块语句有两种,一种是begin_end语句,通常用来标识顺序执行的语句,用它来标识的块称为顺序块。一种是fork_join语句,通常用来标识并行执行的语句, 用它来标识的块称为并行块。
顺序块
这里面的内容都是顺序执行的,比如b=a; c=b,先执行一条,再执行下一条,那就是c=a了如果里面有两组if/else,就是先执行前一组,再执行后一组。但是如果是非阻塞,那就要特殊对待,多个非阻塞赋值是在一个块结束时一起执行的,比如b<=a; c<=b,那就跟之前不同了,当执行c<=b 时b还没有变化成a的值,因此这个赋值的结果是b被赋值前的值,这两条语句其实是独立的、并行的。好处是放得先后顺序没关系,只要在一个块内,随便写。
顺序块有以下特点:
顺序块的格式如下:
begin
//语句1;
//语句2;
//......
//语句n;
end
//或者
begin:块名
//块内声明语句
//语句1;
//语句2;
//......
//语句n;
end
并行块
并行块有以下四个特点:
并行块的格式如下:
fork//fork真有意思,分叉,fork()函数生成子进程也是分叉!!join,是又汇合了啊。。
//语句1;
//语句2;
//......
//语句n;
join
//或者
fork:块名
//块内声明语句
//语句1;
//语句2;
//......
//语句n;
join
块名
在VerilgHDL语言中,可以给每个块取一个名字,这样做的原因有以下几点。
起始时间和结束时间
在并行块和顺序块中都有一个起始时间和结束时间的概念。对于顺序块,起始时间就是第一条语句开始被执行的时间,结束时间就是最后一条语句执行完的时间。而对于并行块来说,起始时间对于块内所有的语句是相同的,即程序流程控制进入该块的时间,其结束时间是按时间排序在最后的语句执行完的时间。
六点说明:
一般形式如下:
case(表达式) <case分支项> endcase
casez(表达式)<case分支项> endcase
casex(表达式)<case分支项> endcase
case, casez, casex 的真值表:
| case | 0 | 1 | x | z |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 |
| x | 0 | 0 | 1 | |
| z | 0 | 0 | 0 | 1 |
| casez | 0 | 1 | x | z |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 1 |
| x | 0 | 0 | 1 | 1 |
| z | 1 | 1 | 1 | 1 |
| casex | 0 | 1 | x | z |
|---|---|---|---|---|
| 0 | 1 | 0 | 1 | 1 |
| 1 | 0 | 1 | 1 | 1 |
| x | 1 | 1 | 1 | 1 |
| z | 1 | 1 | 1 | 1 |
栗子:
//有锁存器
always @(al or d)
begin
if(al) a<=d;
end
//无锁存器
always @(al or d)
begin
if(al) a<=d;
else q<=0;
end
//****************************************
//有锁存器
always @(sel[1:0] or a or b)
case (sel[1:0])
2‘b00: q<=a;
2‘b11: q<=b;
endcase
//无锁存器
always @(sel[1:0] or a or b)
case (sel[1:0])
2‘b00: q<=a;
2‘b11: q<=b;
default: q<=‘b0;
endcase
避免偶然生成锁存器的错误。如果用到if语句,最好写上else项。如果用case语句,最好写上default项。遵循上面两条原则,就可以避免发生这种错误,使设计者更加明确设计目标,同时也增强了Verilog程序的可读性。
四类循环语句:
forever 连续执行的语句。
forever循环语句常用于产生周期性的波形,用来作为仿真测试信号。它与always语句不同处在于不能独立写在程序中,而必须写在initial块中。
repeat 连续执行一条语句n次。
repeat(次数表达式) 语句;
while 执行一条语句直到某个条件不满足。如果一开始条件不满足则一次都不执行。
while(表达式) 语句;
for 通过以下三个步骤来决定语句的循环执行。
四种结构说明语句:
initial 说明语句
一个模块中可以有多个initial块,它们都是并行运行的。initial块常用于测试文件和虚拟模块的编写,用来产生仿真测试信号和设置信号记录等仿真环境。
always 说明语句
always@(敏感事件列表) 用于描述时序逻辑
敏感事件上升沿 posedge,下降沿 negedge,或电平敏感事件列表中可以包含多个敏感事件,但不可以同时包括电平敏感事件和边沿敏感事件; 也不可以同时包括同一个信号的上升沿和下降沿,这两个事件可以合并为一个电平敏感事件。
凡是always块内输出,都要定义成reg型的。 由这一点也可以看出,定义成reg型的不一定全是寄存器。
沿触发的always块常常描述时序逻辑, 如果符合可综合风格要求可用综合工具自动转换为表示时序逻辑的寄存器组和门级逻辑,而电平触发的always块常常用来描述组合逻辑和带锁存器的组合逻辑,如果符合可综合风格要求可转换为表示组合逻辑的门级逻辑或带锁存器的组合逻辑。一个模块中可以有多个always块,它们都是并行运行的。
task和function说明语句不同点
任务和函数有些不同,主要的不同有以下四点:
栗子:
定义一任务或函数对一个16位的字进行操作让高字节与低字节互换,把它变为另一个字(假定这个任务或函数名为: switch_bytes)。
//任务,返回的新字Byte是通过输出端口的变量实现
switch_bytes(old_word,new_word);
//函数,返回的新字Byte是通过函数本身返回值实现
new_word = switch_bytes(old_word);
抄一些网上的说明:
task 说明语句
抄一些网上对task的说明:
function 说明语句
与任务相比较函数的使用有较多的约束,下面给出的是函数的使用规则:
预处理命令以符号“ `”开头(注意这个符号是不同于单引号“ ‘”的)。
Verilog和c语言不同且需要着重理解的点:
八个基本的门类型GATATYPE:
Code:
module flop
(
input data,clock,clear;
output q,qb;
)
nand #10 nd1(a,data,clock,clear),
nd2(b,ndata,clock),
nd4(d,c,b,clear),
nd5(e,c,nclock),
nd6(f,d,nclock),
nd8(qb,q,f,clear);
nand #9 nd3(c,a,d),
nd7(q,e,qb);
not #10 iv1(ndata,data),
iv2(nclock,clock);
endmodule

想要了解D flip-flop触发器,需要先看一下D latch锁存器,最好能先看看SR 锁存器,既然都看了SR锁存器了,顺带把555定时器也看一下最好。最能能一块把触发器flip-flop、锁存器latch、寄存器register之间的区别和联系一块屡清楚。
上一小结编写的flop模块引用如下:
栗子:
module hardreg(d,clk,clrb,q);
input clk,clrb;
input[3:0] d;
output[3:0] q;
flop f1(d[0],clk,clrb,q[0],),
f2(d[1],clk,clrb,q[1],),
f3(d[2],clk,clrb,q[2],),
f4(d[3],clk,clrb,q[3],);
endmodule
对于数字系统的设计人员来说,只要了解UDP的作用就可以了,而对微电子行业的基本逻辑元器件设计工程师,必须深入了解UDP的描述,才能把所设计的基本逻辑元件,通过EDA工具呈现给系统设计工程师。
待补充
待补充
【重点待补充】
目前,用门级和RTL级抽象描述的Verilog HDL模块可以用综合器转换成标准的逻辑网表;用算法级描述的Verilog HDL模块,只有部分综合器能把它转换成标准的逻辑网表;而用系统级描述的模块,目前尚未有综合器能把它转换成标准的逻辑网表,往往只用于系统仿真。
待补充
待补充
待补充
待补充
待补充
待补充
待补充
待补充
待补充
待补充
有限状态机(Finite-State Machine,FSM),又成为有限状态自动机,简称状态机,是表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型。笔者常在电机控制、通信协议解析等应用场景下应用FSM。 本文所讲的是基于硬件描述语言Verilog HDL的有限状态机的编写技巧及规范。众所周知FPGA以其并行性和可重构性为世人所知,而在当今的电子世界,基本所有的器件都是串行的,所以作为控制单元或者是可编程单元的FPGA需要进行并行转串行与外界进行通信、控制等,而有限状态机以其简单实用、结构清晰而恰如其分的充当着这个角色。
【重点待补充】
---简化的RISC CPU设计简介---
八个基本部件:
1)时钟发生器 2)指令寄存器 3)累加器 4)RISC CPU算术逻辑运算单元 5)数据控制器 6)状态控制器 7)程序计数器 8)地址多路器
【非常重要,多练习!!】
标签:视图 数值 索引 输入 信号 时钟 disable default 十六
原文地址:https://www.cnblogs.com/dluff/p/12440040.html