标签:空间 访问 other sum 组成 oca roc The http
计算机组成原理,CPU缓存和局部性原理
https://golang.org/s/go11sched
http://lessisbetter.site/2019/03/10/golang-scheduler-1-history/
1. Single global mutex (Sched.Lock) and centralized state. The mutex protects all goroutine-related operations (creation, completion, rescheduling, etc).
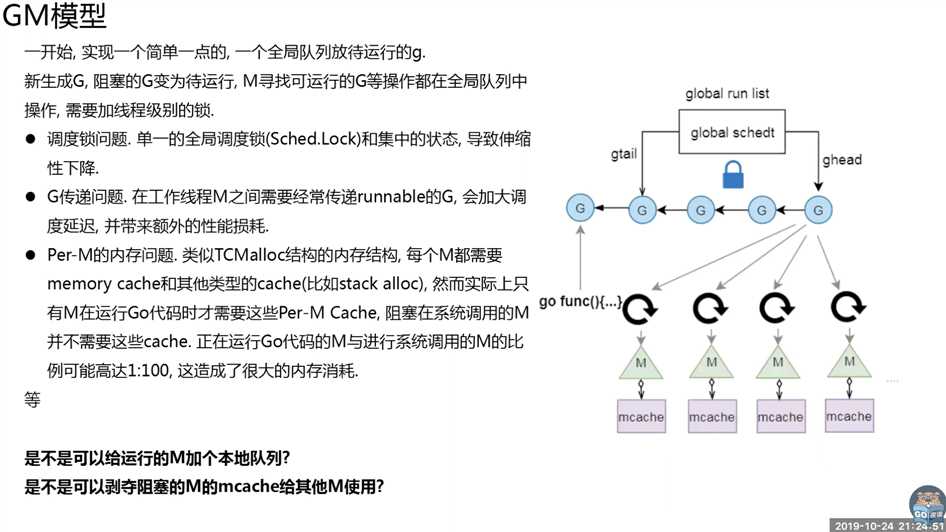
创建、销毁、调度G都需要每个M获取锁,这就形成了激烈的锁竞争。
解释:
从源码中可以看到很多schedlock()的调用。比如,G状态的修改需要防止并发修改。
https://sourcegraph.com/github.com/golang/go@release-branch.go1/-/blob/src/pkg/runtime/proc.c#L471
https://sourcegraph.com/github.com/golang/go@release-branch.go1/-/blob/src/pkg/runtime/proc.c#L252
优化思路:
很自然的就能想到,把锁的粒度细化来提高减少锁竞争,也就是把全局队列拆除局部队列。
具体实施:
具体实施的时候会有一下几个问题。
2. Goroutine (G) hand-off (G.nextg). Worker threads (M‘s) frequently hand-off runnable goroutines between each other, this may lead to increased latencies and additional overheads. Every M must be able to execute any runnable G, in particular the M that just created the G.
M转移G会造成延迟和额外的系统负载。// 参考附录1的图示来讲解
比如当G中包含创建新协程的时候,M创建了G’,为了继续执行G,需要把G’交给M’执行,也造成了很差的局部性,因为G’和G是相关的,最好放在M上执行,而不是其他M’。
3. Per-M memory cache (M.mcache). Memory cache and other caches (stack alloc) are associated with all M‘s, while they need to be associated only with M‘s running Go code (an M blocked inside of syscall does not need mcache). A ratio between M‘s running Go code and all M‘s can be as high as 1:100. This leads to excessive resource consumption (each MCache can suck up up to 2M) and poor data locality.
M中的mcache是预先分配用来存放小对象的内存。
当M阻塞时,mcache内存是没有用到的。而M阻塞与M运行的比例大概是100:1,所以大部分M的mcache都是浪费的,我们可以考虑剥夺阻塞M的mcache给其他M用。// 附录1图片
解释:mcache其实就是预先分配的一点内存用于存放小对象。 // 附录2
1. mcache:每个运行期的goroutine都会绑定的一个mcache(具体来讲是绑定的GMP并发模型中的P,所以可以无锁分配mspan,后续还会说到),mcache会分配goroutine运行中所需要的内存空间(即mspan)。
2. 为了避免多个goroutine申请内存时不断的加锁,`为每个goroutine分配了span内存块的缓存`,这个缓存即是mcache,每个goroutine都会绑定的一个mcache,各个goroutine申请内存时不存在锁竞争的情况。
3. 我们再来看看mcache具体的结构:mcache中的span链表分为两组,一组是包含指针类型的对象,另一组是不包含指针类型的对象。为什么分开呢?
4. 对于 <=32k的对象,将直接通过mcache分配。4. Aggressive thread blocking/unblocking. In presence of syscalls worker threads are frequently blocked and unblocked. This adds a lot of overhead.
系统调用导致频繁的线程阻塞和取消阻塞操作增加了系统开销。
解释:
GM时,GM的状态基本是一致的,G阻塞一定会导致内核线程M阻塞。M阻塞和唤醒就会造成系统开销。
优化思路:
很自然可以想到,G阻塞时,想办法让M可以被继续使用。
部分解决:
引入P解决了异步系统调用情况下的 阻塞线程和取消阻塞线程 的系统开销。但是没有解决同步系统调用情况下阻塞M的问题。// 附录3
更具体的阻塞场景:Go调度器如何处理goroutine阻塞的情况? // TODO: 这里需要去了解channel的机制。
Q: 为什么还要保留全局队列。// 类似地方政府和中央政府,大家有事都找中央政府,协调不过来。
A: 简短回答. 提供本地队列到全局队列的负载均衡。
A: 如果只有本地队列,本地队列空了会P空闲,本地队列满了会其他P送G。对于这种情况有2种方案。
Q: go启动的线程数量
可以使用go tool 打印调度器的日志。
http://lessisbetter.site/2019/03/26/golang-scheduler-2-macro-view/
https://colobu.com/2016/04/19/Scheduler-Tracing-In-Go/
Scheduler Tracing In Go
我们在做系统改进时,每当引入一种解决方案时,除了关注其优点,还需要关注新方案引入了哪些新问题,在解决旧问题和引入新问题之间找到平衡点。
标签:空间 访问 other sum 组成 oca roc The http
原文地址:https://www.cnblogs.com/yudidi/p/12439430.html