标签:targe git learning 方法 简单 快速 original ssi 跳转

摘要:BERT因为效果好和适用范围广两大优点,所以在NLP领域具有里程碑意义。实际项目中主要使用BERT来做文本分类任务,其实就是给文本打标签。因为原生态BERT预训练模型动辄几百兆甚至上千兆的大小,模型训练速度非常慢,对于BERT模型线上化非常不友好。本篇研究目前比较火的BERT最新派生产品ALBERT来完成BERT线上化服务。ALBERT使用参数减少技术来降低内存消耗从而最终达到提高BERT的训练速度,并且在主要基准测试中均名列前茅,可谓跑的快,还跑的好。希望对需要将BERT线上化感兴趣的小伙伴有些许帮助。
目录
01 项目背景介绍
02 从BERT到ALBERT
03 万里第一步:先跑通模型
04 多分类任务实践
总结
01 项目背景介绍
原生态BERT预训练模型动辄几百兆甚至上千兆的大小,训练速度非常慢,对于模型线上化非常不友好。为了实现BERT模型线上化问题,其实就是如何又快有好的训练模型,经调研目前超火的BERT最新派生产品ALBERT项目能很好的解决上述问题。
ALBERT是由论文《ALBERT:
A Lite BERT For Self-Supervised Learningof Language
Representations》提出来的。通常情况下增加预训练模型大小可以提升模型在下游任务中的性能,但是因为“GPU/TPU内存的限制、更长的训练时间以及意想不到的模型退化”等问题,作者提出了ALBERT模型。
论文下载地址:
https://arxiv.org/pdf/1909.11942.pdf
通俗的理解ALBERT就是参数数量更少的轻量级BERT模型。ALBERT是BERT最新派生产品,虽然轻量,但是效果并没打折,在主要基准测试中均名列前茅。
02 从BERT到ALBERT
1. ALBERT出现背景
自从深度学习引爆计算机视觉领域之后,提升模型性能最简单也最有效的一个方法就是增加网络深度。下图中拿图片分类任务举例,可以看出随着网络层数不断增加,模型的效果也会有很大提升:
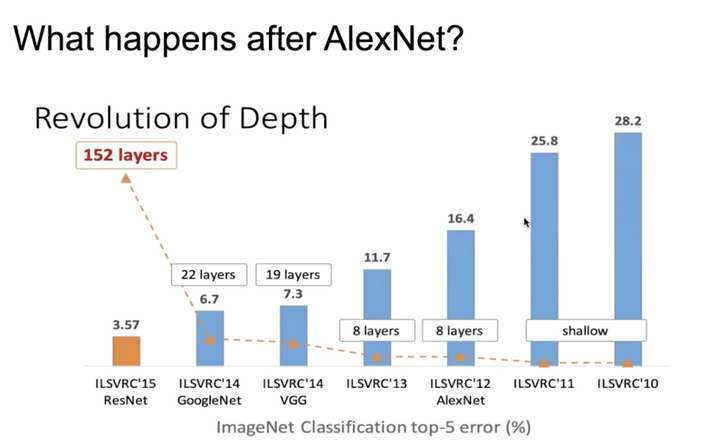 图1 网络层数增加模型效果提升
图1 网络层数增加模型效果提升
同样的情况也出现在BERT上,随着网络变深变宽使得模型的效果得到提升:
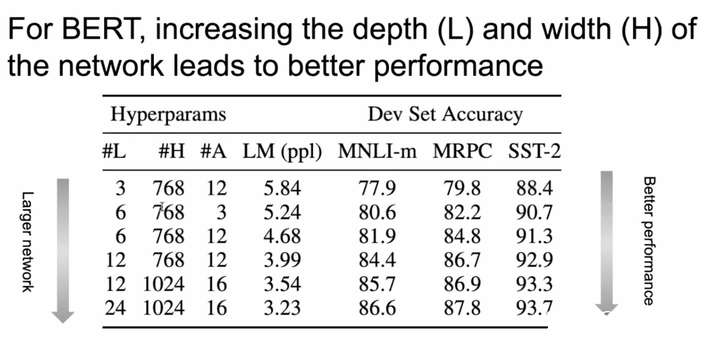 图2 BERT随着网络变深变宽模型效果得到提升
图2 BERT随着网络变深变宽模型效果得到提升
但是网络变深变宽带来一个显著的问题:参数爆炸。这里看下不同规模参数的BERT模型参数量的变“胖”之路:
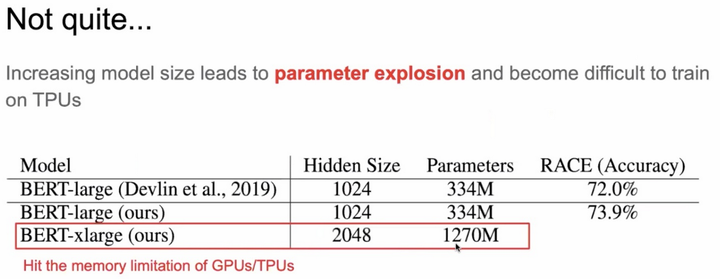 图3 BERT参数爆炸问题
图3 BERT参数爆炸问题
如何做到,让BERT不那么“胖”,但是效果依旧好是目前学术界的研究重点,也是如何将BERT线上化的重点工作之一。这也是ALBERT要做的事情。
2. BERT“胖”在哪里
想让BERT变瘦,先要知道“肉”长在哪里。BERT使用Transformer作为特征抽取器,这是BERT参数的来源。之前广告行业中那些趣事系列4:详解从配角到C位出道的Transformer很深入的剖析了Transformer,有兴趣的小伙伴可以回头看看。
Transformer的参数来源主要有大块:第一块是token embedding映射模块,参数量占比为20%,第二块是attention层和前向反馈层FFN,参数量占比为80%。
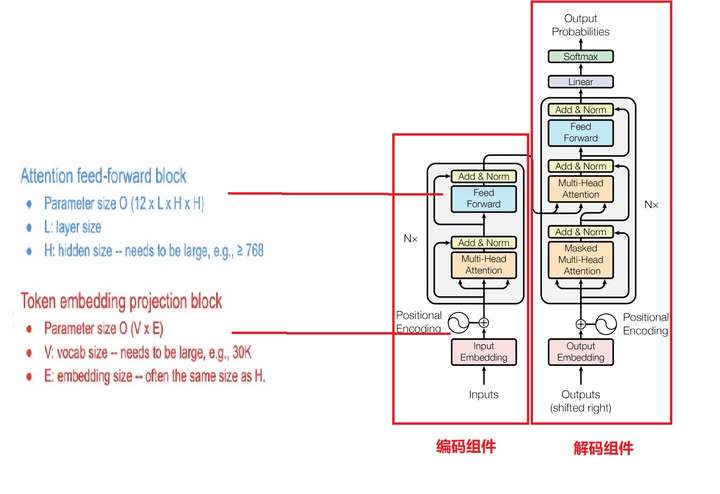 图4 Transformer结构图和BERT参数来源
图4 Transformer结构图和BERT参数来源
3. ALBERT优化策略
策略一、对embedding参数因式分解(Factorized embedding parameterization)
BERT将词的one-hot向量映射到高维空间,参数量是O(VXH),ALBERT则采用因式分解的方式先将词的one-hot向量映射到低维空间(大小为E),然后再映射回一个高维的空间(大小为H),这样使用的参数仅仅是O(VXE+EXH),如果E<<H的时候参数量会减少很多。这里就一定程度上减少了上面说的BERT第一部分参数token
embedding的部分。
可以通过因式分解减少参数量的原因是token
embedding是上下文独立的,通过one-hot向量转化成dense向量。而第二部分的attention和FFN作为隐藏层是上下文依赖的,包含更多信息。所以通过一个小于H的E做中介将词的one-hot向量先经过一个低维的embedding矩阵,然后再映射回高维的embedding矩阵是可行的。下图中红色方框显示了因式分解部分:
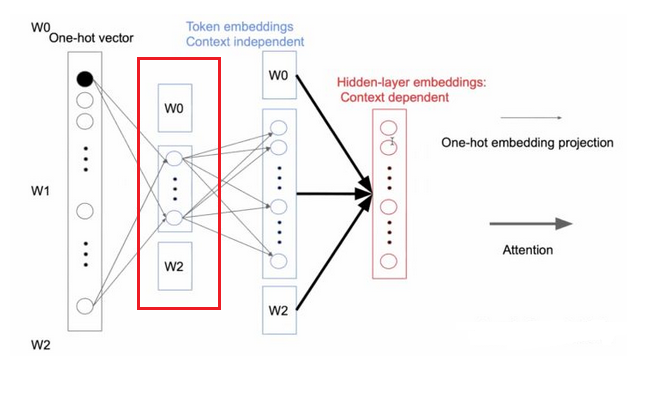 图5 因式分解降低参数量
图5 因式分解降低参数量
查看token embedding因式分解效果情况:总体来看降低了17%的模型参数,但是模型效果仅仅降低了不到1%。
 图6 因式分解降低参数量效果
图6 因式分解降低参数量效果
策略二、共享层与层之间的参数(Cross-layer parameter sharing)
通过对Transformer各层参数可视化分析发现各层参数类似,都是在[CLS]token和对角线上分配更多的注意力,所以可以使用跨层的参数共享方案。
通常来说,跨层的参数共享对应Transformer编码器中的结构有两种方案:一种是attention模块的参数共享,另一种是前馈神经网络层FFN的参数共享。具体的效果如下图所示:
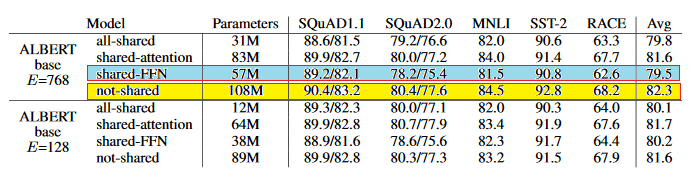 图7 使用共享参数对模型参数量和效果的影响
图7 使用共享参数对模型参数量和效果的影响
当映射到低维空间E=768时,对比不共享参数和共享FFN层的参数可以看出,参数减少了近50%,这也是导致模型效果下降的主要原因。而共享attention层的参数则对模型效果影响较小。
策略三、构建自学习任务-句子连贯性预测
通过改造NSP(Next Sentence Prediction)任务,增强网络学习句子的连续型来提高预训练任务。
广告行业中那些趣事系列3:NLP中的巨星BERT重点讲解了BERT模型,其中提到BERT是近几年NLP领域杰出成果的集大成者,本身的创新主要是随机屏蔽的语言模型Masked LM和下一句预测Next Sentence Prediction。有兴趣的小伙伴可以倒回去再好好看下。
NSP任务本身是一个二分类任务,目的是预测两句话是否是连续的语句。NSP实际包含两个子任务,分别是主题预测和关系一致性预测。NSP任务选择同一文档中连续的两个句子作为正样本,选择不同文档的句子作为负样本。因为来自不同的文档,差异性可能非常大。为了提升模型预测连续型句子的能力,ALBERT提出了新的任务SOP(SenteceOrder
Prediction),正样本获取方式和NSP相同,负样本则将正样本的语句顺序颠倒。
SOP和NSP效果展示如下图所示:
 图8 SOP和NSP效果展示
图8 SOP和NSP效果展示
从图中可以看出NSP任务无法预测SOP类任务,但是SOP可以预测NSP任务。整体来看,SOP任务的模型效果也优于NSP任务。
策略四、去掉dropout
dropout主要是为了防止过拟合,但实际MLM一般不容易过拟合。去掉dropout还可以较少中间变量从而有效提升模型训练过程中内存的利用率。
 图9 dropout效果影响
图9 dropout效果影响
其他策略:网络宽度和深度对模型效果的影响
1. 网络深度是否越深越好
对比ALBERT在不同深度下的效果可以发现:随着层数加深,不同NLP任务的模型效果是有一定提升。但是这种情况并不是绝对的,有些任务效果反而会下降。
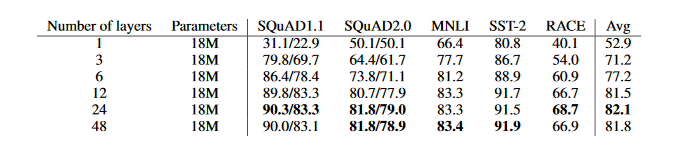 图10 网络深度的影响
图10 网络深度的影响
2. 网络宽度是否越宽越好
对比深度为3的ALBERT-large模型下不同网络宽度的模型效果情况可以发现:模型宽度的影响和深度类似,随着网络宽度增加,不同NLP任务的模型效果是有一定提升。某些任务也会存在效果下降的情况。
 图11 网络宽度的影响
图11 网络宽度的影响
总体来看,ALBERT的实质是使用参数减少技术来降低内存消耗从而最终达到提高BERT的训练速度,主要优化了以下几个方面:
03 万里第一步:先跑通模型
因为实际项目中主要是识别中文,所以主要是使用ALBERT中文版本ALBERT_zh,项目的github地址:https://github.com/brightmart/albert_zh。
记得之前看过一个图片很有意思,能很好的描述此刻我的心情:
 图12 第一步先跑通模型
图12 第一步先跑通模型
对于我这种“拿来主义者”来说,再牛逼的模型第一步永远都是先跑通它,至于优化的先放一放。跑通它不仅能提升自信心,最实际的作用就是能快速实现项目上线。因为我需要完成文本分类任务,所以通过上面的github地址下载项目后,在集群上跳转到albert_zh目录下,执行sh
run_classifier_lcqmc.sh命令即可跑起来。因为项目没有句子分类任务,只有个类似的句子关系判断任务,所以先跑通这个任务,后期再根据这个任务的代码来改就行了。
run_classifier_lcqmc.sh脚本中总体分成两大块,第一块是模型运行的准备工作,第二块就是模型运行。下面是模型的第一块,其中涉及获取数据、预训练模型、设备以及模型相关的参数等等。
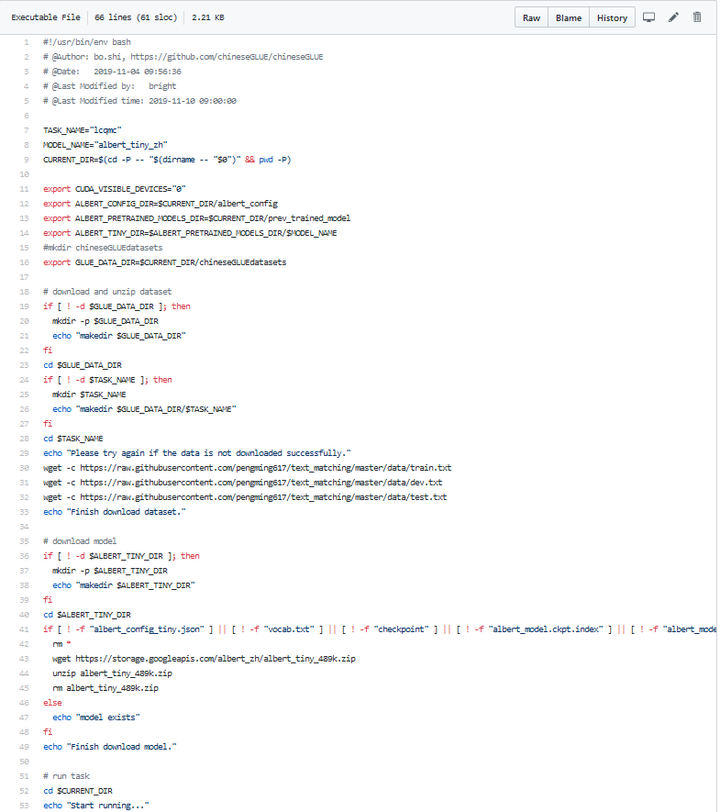 图13 模型运行准备工作
图13 模型运行准备工作
第二块就是负责模型运行,主要就是python运行程序的指令以及需要的相关参数配置。
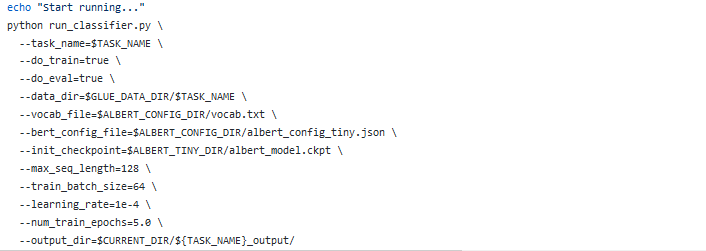 图14 模型运行
图14 模型运行
总结下,这里重点讲了如何运行成功ALBERT_zh本身提供的一个句子关系判断任务。这个demo是和我们实际项目中文本分类任务很相似的任务,下面就是通过改造这个脚本以及执行的代码来完成我们的实际项目文本分类。
04 多分类任务实践
项目改造的github地址如下:https://github.com/wilsonlsm006/albert_zh。
将原项目fork下来,这里我增加了两个文件run_classifier_multiclass.sh和run_classifier_multiclass.py。这是用来执行文本分类的任务脚本以及代码。改造的原理其实也比较简单,这里大致讲解下。
项目原来提供的句子关系判断任务的数据格式是:id,text_a,text_b,label,任务其实就是来判断两句话到底有没有关系。正样本举例如下:
text_a:成龙大哥代言的一刀传奇好玩么?
text_b:成龙大哥还代言过其他传奇么?
label:1
负样本则可能是这样的:
text_a:成龙大哥代言的一刀传奇好玩么?
text_b:成都市内哪个景点最好玩?
label:0
通过上面两个正负样本的例子大家应该能了解什么是句子关系判断任务,其实就是有监督学习的分类任务。我们实际项目主要通过BERT来做文本分类,识别一句话属于哪个标签,对应到上面的任务其实就是只有text_a,label。因为任务类型一致,所以修改代码的策略就是重点分析有text_b的代码的部分。具体脚本和代码修改就是上面说的两个文件,有需要的小伙伴自取。这里需要注意的是原来的数据文件是tsv格式,我这边是csv格式,数据输入有点点不同,模型其他的都没动。
总结
实际项目中需要将BERT线上化需要使模型又快又好的训练,所以经过调研使用目前BERT最新的派生产品ALBERT。ALBERT通过因式分解和共享层与层之间的参数减少了模型参数量,提升了参数效率;通过SOP替代NOP,增强了网络学习句子的连续性的能力,提升了自监督学习任务的能力;通过去掉dropout可以节省很多临时变量,有效提升模型训练过程中内存的利用率,提升了模型的效率,减少了训练数据的规模。最后将项目中的句子关系判断任务改造成我们实际项目中的文本分类任务用于实际业务需求。可以说是有理论,帮助小伙伴们理解ALBERT为啥训练快了,效果还不错。也有实践,如果需要使用ALBERT做文本分类任务,直接用我改造好的脚本和代码跑起来就行。
喜欢本类型文章的小伙伴可以关注我的微信公众号:数据拾光者。有任何干货我会首先发布在微信公众号,还会同步在知乎、头条、简书、csdn等平台。也欢迎小伙伴多交流。如果有问题,可以在微信公众号随时Q我哈。

广告行业中那些趣事系列6:BERT线上化ALBERT优化原理及项目实践(附github)
标签:targe git learning 方法 简单 快速 original ssi 跳转
原文地址:https://www.cnblogs.com/wilson0068/p/12444111.html