标签:values 转换 理解 重命名 调用 null 两种 size sha
pandas是常用的数据分析库,用于处理表格型或者异质性数据,主要有两种数据类型:Series和DataFrame。
本文采用的是Jupyter notebook , 导入库语句:import pandas as pd
Series是一维数据型对象,粗略的理解,有一点似于C语言中的数组值values+可重新命名的index,即索引,可以认为是一个长度固定的字典。是DataFrame的组成部分。
DataFrame是二维结构,是一张表,有两条轴,axis=0(index行)与 axis=1(columns列) 。与R语言的数据框类似,每一个列(属性列)数据类型可不同,分析的范围较广。
Series的创建比较简单,可将列表类型、字典类型直接转换,或者调用numpy中的arange生成。
DataFrame的创建常用是用字典类型,键转换为columns,或者调用numpy.arange.reshape()生成数据,在创建时可创建列名的列表,调用columns进行赋值。
二者共同之处在于,index是否重命名,默认为从0开始,步长为1的递增数列。
例如:
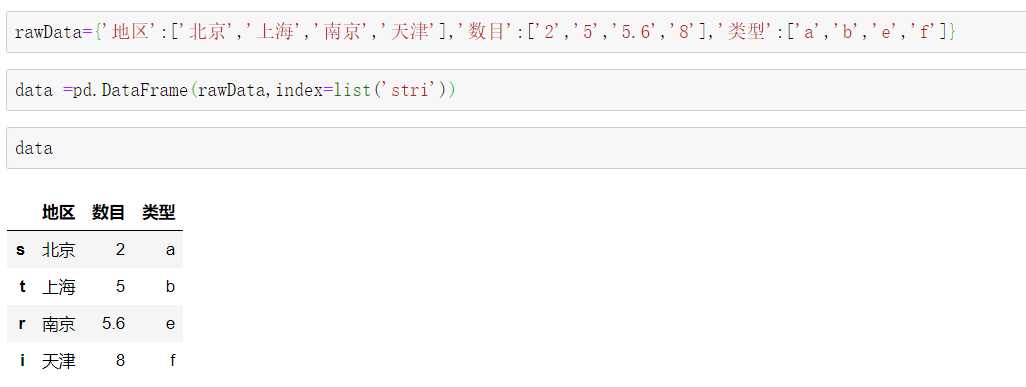
另:在创建过程中可能会出现数据缺失(NA),可用isnull或者notnull来进行检测,返回值为True或False。
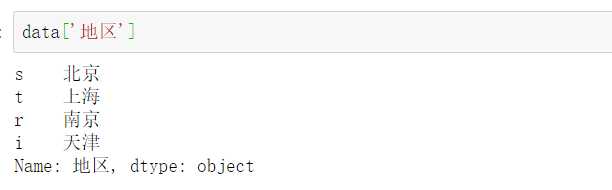
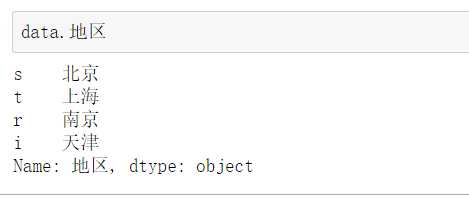
方式1::‘索引’,即用 [] 调用索引和列名直接检索。
若对行也有要求:
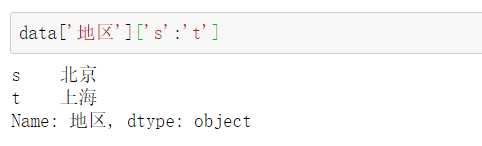
特别说明:Series切片包含尾部!与列表切片不同!
方式2:条件(如=、!=)布尔值进行过滤的检索

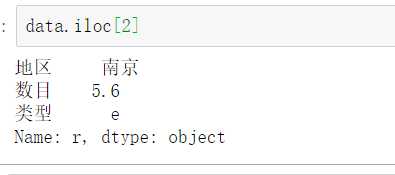
调用函数:loc(轴标签 即名称)和iloc函数(整数标签 即序列号)进行选取。
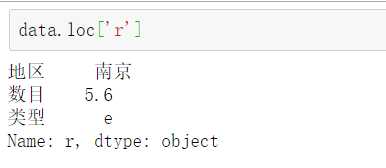
南京序列号为2,则用iloc同样可以检索到:
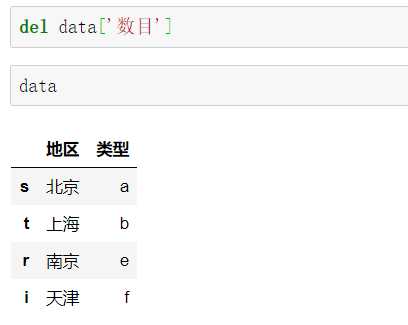
删去一个属性列
特别说明:从DataFrame选取的列是数据的视图,对Series的操作会反映到DataFrame中。
方式2:运用drop函数
说明:
a.默认是删除索引行,若要删除列,则需设置参数axis=1。
b.默认返回的是新对象,原数据没有发生更改。
c.设置inplace=True ,修改的是原数据。
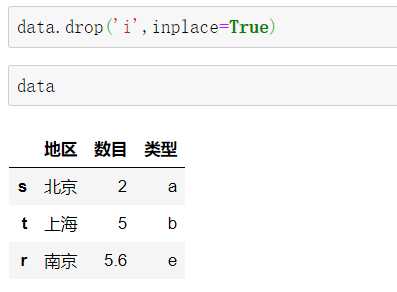
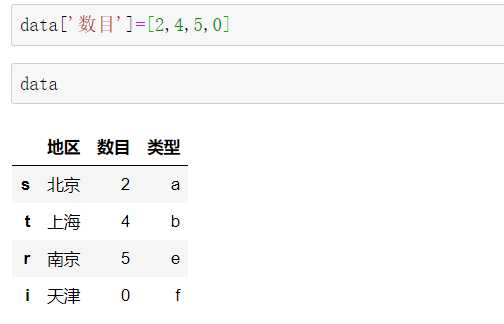
一旦索引对象确定,是不可变的,用户不可以进行修改。
例1:
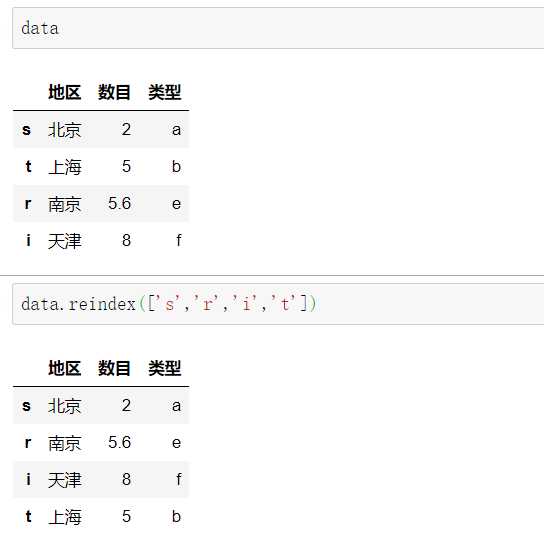
例2:
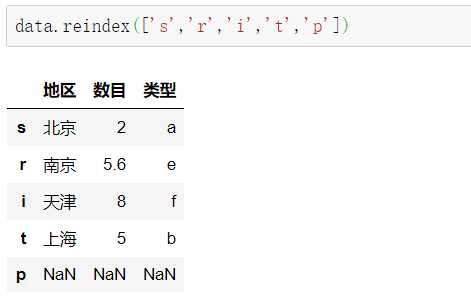
特别注意:此时的原data并没有发生改变。
标签:values 转换 理解 重命名 调用 null 两种 size sha
原文地址:https://www.cnblogs.com/sept/p/12443141.html