标签:blank 类方法 ros 你好 www discount mic pytho nta
本文主要讨论的是以航空公司的会员数据,用RFM的思想结合聚类分析,挖掘不同客户群的价值并制定不同的营销策略。流程大致为:1.用Pandas对数据进行预处理; 2.用Matplotlb进行数据可视化和数据探索;3.用Sklearn来对客户聚类
2020年的新年假期对于大部分小伙伴来说是漫长和乏味的,而对于J来说,应该是类似的,但又是微妙的。不能和小伙伴聚会,没人带我去探险,也没教练带我打篮球,还要在家整天被老的。应付完家里的事,J以为可以静下心来,看书搓大招的时候,又会时不时有老阿姨满脸亲切低问:“老许,你要老婆不要?”结果放假前,信心满满,1、2、3点的小目标一个也没完成。终于有个还算清闲的周末了,J咬咬牙就继续写期了文章。
推荐一本《Python数据分析与挖掘实战》,文章以案例的方式讨论常规的数据挖掘问题,和常见统计、机器学习的算法的使用。第一次接触这本书还是在黄老师的数据挖掘课,那时候老师比较严格,大家都不敢选,还好J学分够了,可以自信的去蹭课了。虽然理论知识忘得差不多了,不过工具、理论、业务,还是从最简单的工具入手比较适合我。说朝花夕拾对咱这种小年轻来说可不适合,不过重温一下还是值得的,当时是R版的,换个工具再走一遍也好。哦,对了,我记得当时提班里的同学完成一个什么作业来着,题目不记得了,不过可是靠这个换来了两个女同学请我的一顿饭和一杯奶茶呢!(骄傲得瑟脸)
本文内容的数据和内容,主要来自第7章的航空公司客户价值分析,想跟这走一遍的小伙伴可以去看原书,找数据和代码。老师好像说要回收教程的呀,可为啥我R版的还在。。。
航空公司客户价值分析案例的流程,包括大致如下:
我们的数据集,主要包含客户基本信息,乘机信息,积分信息3类信息,一共44个字段。其中比较重要的如下:
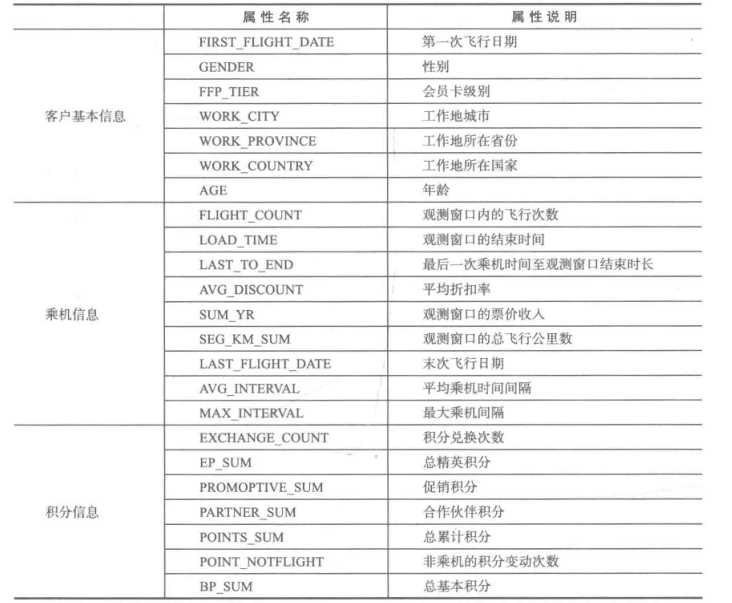
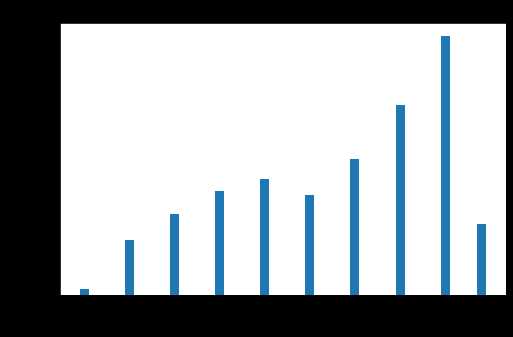
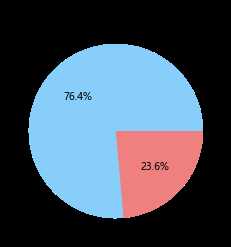

选取客户基本信息中的入会时间、性别、会员卡级别和年龄的字段进行探索分析,我们就会对该航空公司的会员有个大致的了解。会员的人数在2012年的增幅最大,男性占到了75%,会员的级别集中在4级,年龄集中在30-50岁之间。
乘机信息是和客户价值关联最密切的信息,其中客户最近一次乘坐公司飞机距观测窗口结束的时长(观测窗口j结束时间2014年4月1日,单位为天),
飞行次数,总飞行里程数分别可以对应一个用户的R,F,M的信息。
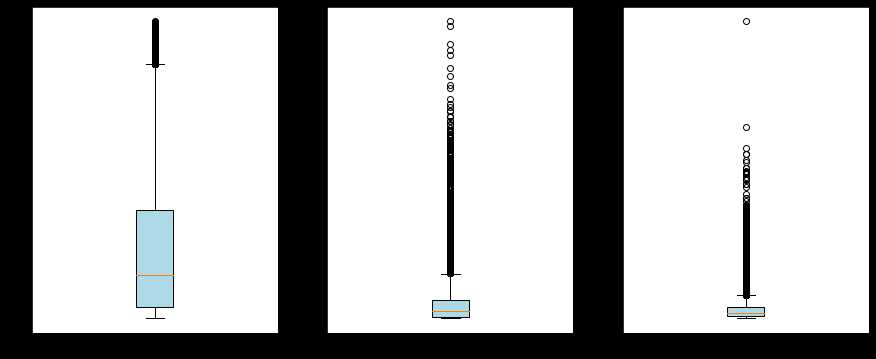
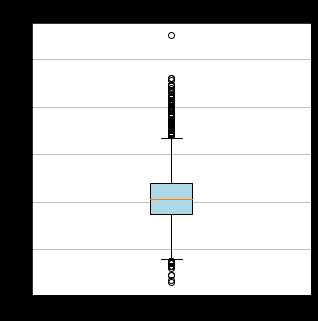
该公司客户的最近一次乘机时间大多距离目当前窗口的时长集中在50-300天的区间内,活跃度满不错的,不过也能看到一部分会员的时长已经超过600天,已经有流失的可能。而飞行次数和总飞行里程数的分布比较类似,主要集中在箱体内,而箱体外的部分,2个指标似乎也比较相似,可能是同一类的高价值消费者。
对于积分相关的信息,我们主要看的是积分的兑换次数和总累积积分。

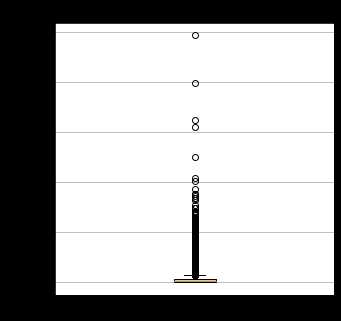
绝大多数的积分主要集中在0-10次以内,表明公司对于积分的玩法似乎并不是很重视,绝大部分的会员都没有兑换积分的意识。而总累积积分的分布和飞行次数和飞行里程的分布比较接近,一定程度上可以用另外2个属性来代替。
我们选择最近一次乘坐公司飞机距观测窗口结束的时长,飞行次数,总飞行里程数,积分的兑换次数,总累积积分,入会年份和客户年龄进行不同特征间的相关性分析,其中主要用的是皮尔逊相关系数。
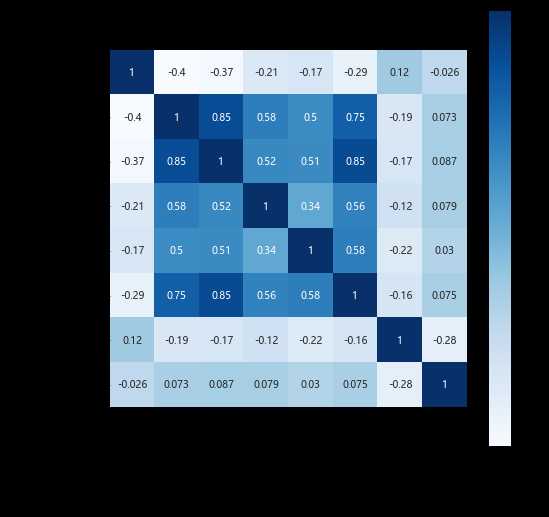
可以看到年龄和入会月份和其他的乘机信息似乎并没有很强的相关性,可以考虑舍弃这部分信息。而飞行总里程,飞行次数,累积积分间果然有比较强的相关性,因此,舍弃其中的部分特征或是用一些特征来代替和补充一些信息。
观察数据我们发现,存在票价为空,或是票价为0,或是折扣率为0且总飞行公里数为0的异常数据,还有J新发现的2014年2月29日的蜜汁数据(黑人问号脸)。

data = pd.read_csv(datafile,encoding=‘utf-8‘) data = data[data[‘SUM_YR_1‘].notnull()*data[‘SUM_YR_2‘].notnull()] #票价非空值才保留 #只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。 index1 = data[‘SUM_YR_1‘] != 0 index2 = data[‘SUM_YR_2‘] != 0 index3 = (data[‘SEG_KM_SUM‘] == 0) & (data[‘avg_discount‘] == 0) #该规则是“与” data = data[index1 | index2 | index3] #该规则是“或” data.loc[data[data["LAST_FLIGHT_DATE"] == "2014/2/29 0:00:00"].index,"LAST_FLIGHT_DATE"] = "2014/2/28" #0229的错误日期处理
因此,对于整个数据集,我们做了以下的清洗行为:
识别客户价值应用最广泛的模型是通过3个指标:
来进行客户细分,识别高价值的客户,简称RFM模型。
在RFM模型中,消费金额表示在一段时间内,客户购买该企业产品金额的总和。由于航空价受到运输距离、航位等级等多种因素影响,同样消费金额的不同旅客对航空公司的价值是不同的。所以消费金额这个指标并不适用于航空公司的客户价值分析。我们选择客户在一定时间内累积的飞行里程M和客户在一定时间内乘坐舱位所对应的折扣系数的平均值C,两个指标代替消费金额。
本案例将客户关系长度L、消费时间间隔R、消费频率F、飞行里程M、折扣系数的平均值C五个指标作为航空公司识别客户价值,记为LRFMC模型。
原始数据中属性太多,根据航空公司客户价值LRFMC模型,选择与LRFMC指标相关的6个属性:FFP_DATE、LOAD_TIME、FLIGHT_COUNT、avg_discount、SEG_KM_SUM、LAST_TO_END。
1)L=LOAD_TIME-FFP_DATE(需要手动构造)
会员入会时间距观测窗口结束的月数=观测窗口的结束时间-入会时间【单位:天】
2)R=LAST_TO_END
客户最近一次乘坐公司飞机距观测窗口结束的月数=最后一次乘机时间至观察窗口末端时长【单位:天】
客户在观测窗口内乘坐公司飞机的次数=观测窗口的总飞行次数【单位:月】
客户在观测时间内在公司累计的飞行里程=观测窗口的总飞行公里数【单位:公里】
5)C=AVG_DISCOUNT
客户在观测时间内乘坐舱位多对应的折扣系数的平均值=平均折扣率【单位:无】
考虑我们会使用聚类,而聚类的方法为K-Means聚类,涉及到距离的定义,默认为欧拉距离。特征的量纲会严重影响我们的聚类结果,我们有必要对原始数据进行标准化。由于特征大多符合正态分布,就默认使用Z-score方法。
L = pd.to_datetime(data["LOAD_TIME"]) - pd.to_datetime(data["LAST_FLIGHT_DATE"]) data_features = pd.concat([L.dt.days,data[[‘LAST_TO_END‘,‘FLIGHT_COUNT‘,‘SEG_KM_SUM‘,‘avg_discount‘]]],axis = 1) data_features.columns = ["L","R","F","M","C"] data_features = (data_features - data_features.mean(axis = 0))/(data_features.std(axis = 0)) #简洁的语句实现了标准化变换,类似地可以实现任何想要的变换。 data_features.columns=[‘Z‘+i for i in data_features.columns] #表头重命名。
标准化后的字段对应为ZL,ZR,ZF,ZM,ZC。
客户价值分析模型构建主要由两部分构成,第一部分根据航空公司客户5个指标的数据,对客户进行聚类分群。第二部分结合业务对每个客户群进行特征分析,分析客户价值,并对每个客户群进行排名。
from sklearn.cluster import KMeans k = 5 kmodel = KMeans(n_clusters = k, n_jobs = 4,random_state=123,init="k-means++") #n_jobs是并行数,一般等于CPU数较好 kmodel.fit(data_features) #训练模型 cluster_center = pd.DataFrame(kmodel.cluster_centers_,columns=data_features.columns) #查看聚类中心 cluster_center.index = pd.Series(kmodel.labels_ ).drop_duplicates().values cluster_count = pd.Series(kmodel.labels_ ).value_counts() cluster_count.name = "count" cluster_center = pd.concat([cluster_center,cluster_count],axis=1) cluster_center.index = ["客户群"+str(i + 1) for i in cluster_center.index] cluster_center.sort_index(inplace=True) cluster_center
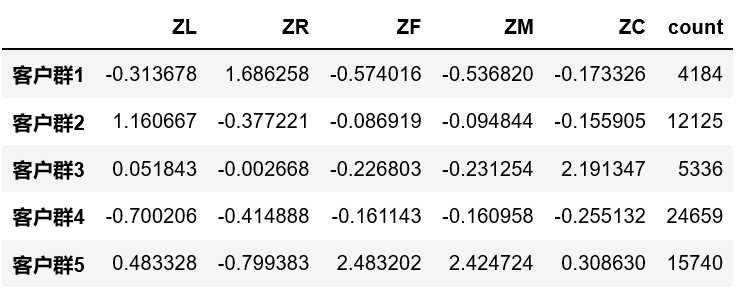
我们把客户聚类成5类,并输出各类客户群的聚类中心和每类客户群的人数。
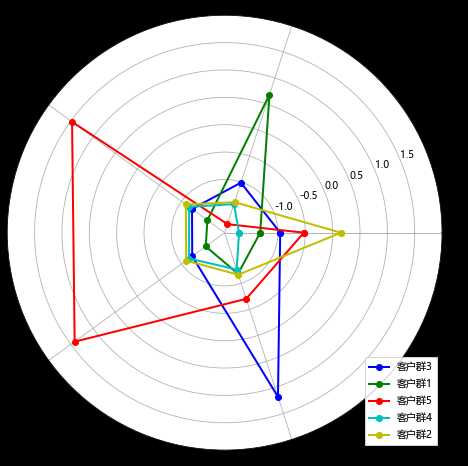
labels = data.columns #标签 k = 5 #数据个数 color = [‘b‘, ‘g‘, ‘r‘, ‘c‘, ‘y‘] #指定颜色 label = [‘ZL‘, ‘ZR‘, ‘ZF‘, ‘ZM‘, ‘ZC‘] angles = np.linspace(0, 2*np.pi, k, endpoint=False) kmodel = KMeans(n_clusters = k, n_jobs = 4,random_state=123,init="k-means++") #n_jobs是并行数,一般等于CPU数较好 kmodel.fit(data_features) #训练模型 cluster_center = pd.DataFrame(kmodel.cluster_centers_,columns=data_features.columns) #查看聚类中心 cluster_center.index = pd.Series(kmodel.labels_ ).drop_duplicates().values cluster_count = pd.Series(kmodel.labels_ ).value_counts() cluster_center.index = ["客户群"+str(i + 1) for i in cluster_center.index] legen = cluster_center.index cluster_center = np.concatenate((cluster_center, cluster_center[["ZL"]]), axis=1) # 闭合 angles = np.linspace(0, 2*np.pi, k, endpoint=False) angles = np.concatenate((angles, [angles[0]])) fig = plt.figure(figsize=(8,8)) ax = fig.add_subplot(111, polar=True) #polar参数!! for i in range(len(legen)): ax.plot(angles, cluster_center[i], ‘o-‘, color = color[i], label = legen[i], linewidth=2)# 画线 ax.set_rgrids(np.arange(0.01, 3.5, 0.5), np.arange(-1, 2.5, 0.5), fontproperties="Microsoft Yahei") ax.set_thetagrids(angles * 180/np.pi, label, fontproperties="Microsoft Yahei") plt.legend(loc = 4) plt.show()
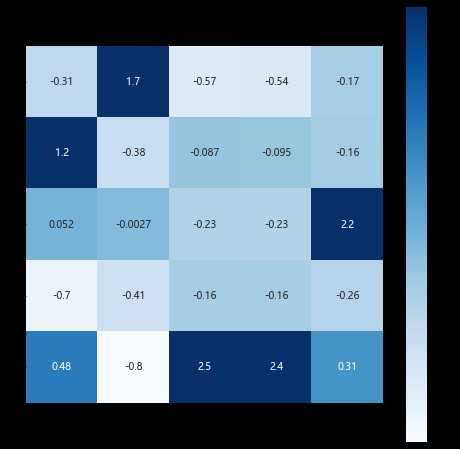
import seaborn as sns plt.subplots(figsize = (8,8)) sns.heatmap(cluster_center,cmap="Blues",annot=True,vmax=1,square=True)
针对聚类结果进行特征分析,其中
| 客户群 | 排名 | 排名含义 |
| 客户群5 | 1 | 重要保持客户 |
| 客户群3 | 2 | 重要发展客户 |
| 客户群2 | 3 | 重要挽留客户 |
| 客户群4 | 4 | 一般客户 |
| 客户群1 | 5 | 低价值客户 |
K-Means聚类在训练时有两个问题需要解决:1)初始聚类中心的选择;2)聚类簇数的选择
关于聚类中心的选择K-Means++可以一定程度解决;关于聚类簇数的判断,可以用肘方法解决。(聚类算法的细节,轮廓系数有时间下次在讨论好了)
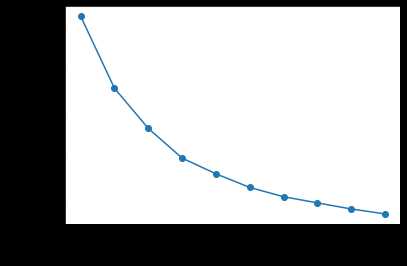
观察聚类簇数和簇内误差平方和的关系图,我们发现聚成3-6类都??,所以我们选择聚成5类还算合理。而关于聚类的质量我们可以使用轮廓系数来进行判断。等下次吧。
distortions =[] for i in range(1,11): km = KMeans(n_clusters=i,n_init=10,max_iter=300,random_state=0) km.fit(data_features) distortions.append(km.inertia_) plt.plot(range(1,11),distortions,marker = "o") plt.xlabel("Number of clusters") plt.ylabel("Distortion") plt.show()
pease&love
J某人对自己说的话
整个冬天呀,J的身上总是带着点疲惫,老是被推着去做些事情。希望春天到了,能早点醒一醒。今年的flag,1)体重有6个月保持在75kg以下,腿粗点ok,但是身上的肉有点松了。这还得了。2)看完2本书。3)在6月前学会用吉他表演一首周董的歌。5)一次短暂的旅行
留给J的时间恐怕不多了吧。不知不觉已经,已经25了!!!!!那今年也许是J的最后一年喽。J一直在摆脱的东西,剩下的一年有可能丢掉吗?
1)谁会想到满脸仍是少年感的J,也许就会被绑上约束我一辈子的东西。会失去什么呀?地铁时,因为对面女生在偷瞄自己而暗暗高兴?坐大巴时,临坐小姐姐不经意的靠到我后,幻想孩子要上哪所幼稚园?还是那个决绝决绝的夏天,说出那句话,然后任性的再也不说一句话呢?
2)不管未来是什么颜色的,J都希望自己能够成为像野原广志一样的男人,即使脚很臭,还有32年房贷,却可以和5岁的臭小孩争吵。我会说他的妈妈是个妖怪小气老太婆,而他也可以回嘴我的老婆是三层轮胎游泳圈。
3)J一直都是幸运男孩,所以还会一直幸运下去吧。
给陈小姐的留言
你说要看我写的文章,EMMMMM,我觉得还是也给你留两句话吧。不管你看完什么感受,都不许生气,不许不开心哦。
1)我们的相识其实多少会有点微妙吧。虽然咱们见面的次数不算多,但每次我都试图去了解你,也会告诉你J是什么样的。但是J有时候也会有挫败感的,因为很多时候次,J都感觉你好像在躲避些什么?也会打击到我的极致性哦。想象一下,J是一台发报机,在发着勾引你的信号,而你给我的反馈是你没有完全的接收到我的魅力,甚至是不想接收。所以你觉得疲惫时,还是希望你能show me,ok?因为当我感觉到别人因为我而疲惫时,我呀,会更疲惫的。
2)J是个恋爱新手,J也会永远是恋爱新手。严格的说,J也没追过女孩子,所以很庆幸J还有机会在你的身上实施我曾经私底下策划的小小阴谋。当一对情人从别人身旁走过时,别人可能会说这种男生怎么配得上这种女生。而我希望你是那样得女生,快告诉你,你就是那样的女生。也许是我的了解不够吧,对于一个交集并不算多的女孩子,J没有办法一看到你,眼里就闪烁着光,所以J希望你务必持续向我展现你的魅力,让J保持恋爱新手的热情。
3)而关于J自己呀,如果说一般男孩子是宝藏男孩的话,那J得算ONE PIECE。就是蜜汁自信,翻开我的封面,你会看到星辰大海哦!
标签:blank 类方法 ros 你好 www discount mic pytho nta
原文地址:https://www.cnblogs.com/307825064j/p/12446136.html
