标签:numpy 问题 plot nts 就是 lib 决定 备份 gre
Python代码实现
一·分类模型
1.sklearn.metrics中包含常用的评价指标:
#准确率 accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
参数:
#精确率 precision_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’, sample_weight=None) #召回率 recall_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’, sample_weight=None)
#F1
f1_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’, sample_weight=None)
参数:
接上篇文章的案例实践代码如下:
1 # 读取相应的库 2 from sklearn import datasets 3 from sklearn.model_selection import train_test_split 4 from sklearn.neighbors import KNeighborsClassifier 5 import numpy as np 6 7 # 读取数据 X, y 8 iris = datasets.load_iris() 9 X = iris.data 10 y = iris.target 11 12 # 把数据分成训练数据和测试数据 13 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=20) 14 15 # 构建KNN模型, K值为3、 并做训练 16 clf = KNeighborsClassifier(n_neighbors=3) 17 clf.fit(X_train, y_train) 18 19 # 计算准确率 20 from sklearn.metrics import accuracy_score 21 correct = np.count_nonzero((clf.predict(X_test)==y_test)==True) 22 print ("Accuracy is: %.3f" %(correct/len(X_test))) # Accuracy is: # output:0.921 23 # 把鸢尾花识别转换为二分类问题 24 y_train_binary = y_train.copy() #备份训练集的预测值y 25 y_test_binary = y_test.copy() #备份测试集的预测值y 26 #y值不是1就将其赋值为0,也就是预测值y只可能是1和0,把原来的三分类问题转成了2分类问题。 27 y_train_binary[y_train_binary != 1] = 0 28 y_test_binary[y_test_binary != 1] = 0 29 # 用KNN进行学习 30 knn = KNeighborsClassifier(n_neighbors=3) 31 knn.fit(X_train, y_train_binary) 32 y_pred = knn.predict(X_test) 33 from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score 34 # 准确率 35 print(‘准确率:{:.3f}‘.format(accuracy_score(y_test_binary, y_pred))) 36 # 精确率 37 print(‘精确率:{:.3f}‘.format(precision_score(y_test_binary, y_pred))) 38 # 召回率 39 print(‘召回率:{:.3f}‘.format(recall_score(y_test_binary, y_pred))) 40 # F1值 41 print(‘F1值:{:.3f}‘.format(f1_score(y_test_binary, y_pred))) 42 #output 准确率:0.921 43 #output 精确率:0.867 44 #output 召回率:0.929 45 #output F1值:0.897
2、sklearn关于P-R曲线的函数
1)求PR曲线的Recall值和Precision值 precision_recall_curve()
sklearn.metrics.precision_recall_curve(y_true, probas_pred, pos_label=None, sample_weight=None)
AP的计算,此处参考的是PASCAL VOC CHALLENGE的2010年之前计算方法。首先设定一组阈值,[0, 0.1, 0.2, …, 1]。然后对于recall大于每一个阈值(比如recall>0.3),我们都会得到一个对应的最大precision。这样,我们就计算出了11个precision。AP即为这11个precision的平均值。这种方法英文叫做11-point interpolated average precision。?
当然PASCAL VOC CHALLENGE自2010年后就换了另一种计算方法。新的计算方法假设这N个样本中有M个正例,那么我们会得到M个recall值(1/M, 2/M, ..., M/M),对于每个recall值r,我们可以计算出对应(r‘ >= r)的最大precision,然后对这M个precision值取平均即得到最后的AP值。
2)如何用sklearn绘制PR曲线
1 from sklearn.metrics import precision_recall_curve,average_precision_score 2 import matplotlib.pyplot as plt 3 precision, recall, _ = precision_recall_curve(y_test_binary, y_pred) 4 plt.step(recall, precision, color=‘b‘, alpha=0.2,where=‘post‘) 5 plt.fill_between(recall, precision, step=‘post‘, alpha=0.2, color=‘b‘) 6 plt.xlabel(‘Recall‘) 7 plt.ylabel(‘Precision‘) 8 plt.ylim([0.0, 1.05]) 9 plt.xlim([0.0, 1.0]) 10 plt.title(‘2-class Precision-Recall curve: AP={:.3f}‘.format(average_precision_score(y_test_binary, y_pred)))
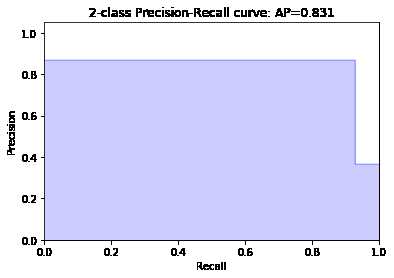
3、sklearn关于ROC曲线的函数
1) roc_curve() 求fpr和tpr的值
sklearn.metrics.roc_curve(y_true, y_score, pos_label=None, sample_weight=None, drop_intermediate=True)
2)roc_auc_score() 求AUC值
roc_auc_score(y_true, y_score, average=’macro’, sample_weight=None)
3)如何绘制ROC曲线
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from itertools import cycle 4 from sklearn import svm, datasets 5 from sklearn.metrics import roc_curve, auc 6 from sklearn.model_selection import train_test_split 7 from sklearn.preprocessing import label_binarize 8 from sklearn.multiclass import OneVsRestClassifier 9 from scipy import interp 10 # Import some data to play with 11 iris = datasets.load_iris() 12 X = iris.data 13 y = iris.target 14 # Binarize the output 15 y = label_binarize(y, classes=[0, 1, 2]) 16 n_classes = y.shape[1] 17 # Add noisy features to make the problem harder 18 random_state = np.random.RandomState(0) 19 n_samples, n_features = X.shape 20 X = np.c_[X, random_state.randn(n_samples, 200 * n_features)] 21 # shuffle and split training and test sets 22 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.5,random_state=0) 23 # Learn to predict each class against the other 24 classifier = OneVsRestClassifier(svm.SVC(kernel=‘linear‘, probability=True,random_state=random_state)) 25 y_score = classifier.fit(X_train, y_train).decision_function(X_test) 26 # Compute ROC curve and ROC area for each class 27 fpr = dict() 28 tpr = dict() 29 roc_auc = dict() 30 for i in range(n_classes): 31 fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i]) 32 roc_auc[i] = auc(fpr[i], tpr[i]) 33 34 # Compute micro-average ROC curve and ROC area 35 fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel()) 36 roc_auc["micro"] = auc(fpr["micro"], tpr["micro"]) 37 plt.figure() 38 lw = 2 39 plt.plot(fpr[2], tpr[2], color=‘darkorange‘,lw=lw, label=‘ROC curve (area = %0.2f)‘ % roc_auc[2]) 40 plt.plot([0, 1], [0, 1], color=‘navy‘, lw=lw, linestyle=‘--‘) 41 plt.xlim([0.0, 1.0]) 42 plt.ylim([0.0, 1.05]) 43 plt.xlabel(‘False Positive Rate‘) 44 plt.ylabel(‘True Positive Rate‘) 45 plt.title(‘Receiver operating characteristic example‘) 46 plt.legend(loc="lower right") 47 plt.show()
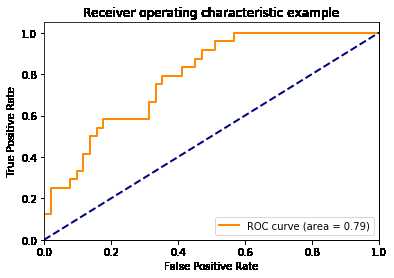
4、在sklearn使用混淆矩阵
得到混淆矩阵confusion_matrix()
sklearn.metrics.confusion_matrix(y_true, y_pred, labels=None, sample_weight=None)
参数:
输出:
一个矩阵,shape=[y中的类型数,y中的类型数]
二·回归模型
1 """ 2 # 利用 diabetes数据集来学习线性回归 3 # diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况。 4 # 数据集中的特征值总共10项, 如下: 5 # 年龄 6 # 性别 7 #体质指数 8 #血压 9 #s1,s2,s3,s4,s4,s6 (六种血清的化验数据) 10 #但请注意,以上的数据是经过特殊处理, 10个数据中的每个都做了均值中心化处理,然后又用标准差乘以个体数量调整了数值范围。 11 #验证就会发现任何一列的所有数值平方和为1. 12 """ 13 import matplotlib.pyplot as plt 14 import numpy as np 15 from sklearn import datasets, linear_model 16 from sklearn.metrics import mean_squared_error, r2_score 17 # Load the diabetes dataset 18 diabetes = datasets.load_diabetes() 19 # Use only one feature 20 # 增加一个维度,得到一个体质指数数组[[1],[2],...[442]] 21 diabetes_X = diabetes.data[:, np.newaxis,2] 22 print(diabetes_X) 23 # Split the data into training/testing sets 24 diabetes_X_train = diabetes_X[:-20] 25 diabetes_X_test = diabetes_X[-20:] 26 # Split the targets into training/testing sets 27 diabetes_y_train = diabetes.target[:-20] 28 diabetes_y_test = diabetes.target[-20:] 29 # Create linear regression object 30 regr = linear_model.LinearRegression() 31 # Train the model using the training sets 32 regr.fit(diabetes_X_train, diabetes_y_train) 33 # Make predictions using the testing set 34 diabetes_y_pred = regr.predict(diabetes_X_test) 35 # The coefficients 36 # 查看相关系数 37 print(‘Coefficients: \n‘, regr.coef_) 38 #output Coefficients: [938.23786125] 39 # The mean squared error 40 # 均方差 41 # 查看残差平方的均值(mean square error,MSE) 42 print("Mean squared error: %.2f" 43 % mean_squared_error(diabetes_y_test, diabetes_y_pred)) 44 # output Mean squared error: 2548.07 45 # Explained variance score: 1 is perfect prediction 46 # R2 决定系数(拟合优度) 47 # 模型越好:r2→1 48 # 模型越差:r2→0 49 print(‘Variance score: %.2f‘ % r2_score(diabetes_y_test, diabetes_y_pred)) 50 #output Variance score: 0.47 51 # Plot outputs 52 plt.scatter(diabetes_X_test, diabetes_y_test, color=‘black‘) 53 plt.plot(diabetes_X_test, diabetes_y_pred, color=‘blue‘, linewidth=3) 54 plt.xticks(()) 55 plt.yticks(()) 56 plt.show()
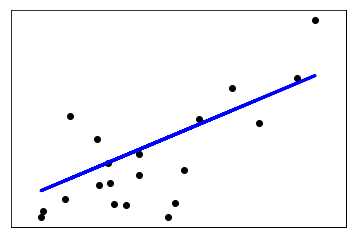
标签:numpy 问题 plot nts 就是 lib 决定 备份 gre
原文地址:https://www.cnblogs.com/mindy-snail/p/12450873.html