标签:mamicode head tab 异常 收集 整理 计算 需要 upd
今天发现大家对NSQ等组件的集群原理还不了解,所以这遍文章对一些常见组件的集群原理做一个汇总整理。我会不定期更新,增加一些新的组件或修改错误。
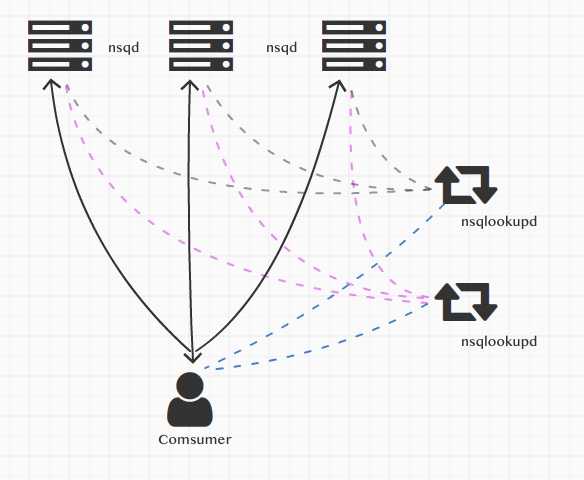
NSQ集群比较简单,主要包含4个部分,一是生产者(图上没画)、二是nsq实例(nsqd)、三是服务发现nsqlookupd、四是消费者(Comsumer)。
这4个部分的工作方式如下:
针对上述特性说明,我们可以得出以下结论或支撑系统高可用的方案:
ES集群涉及数据迁移、负载均衡和HA等,所以会比NSQ集群更复杂些,下面我们通过一张图来简单介绍下:
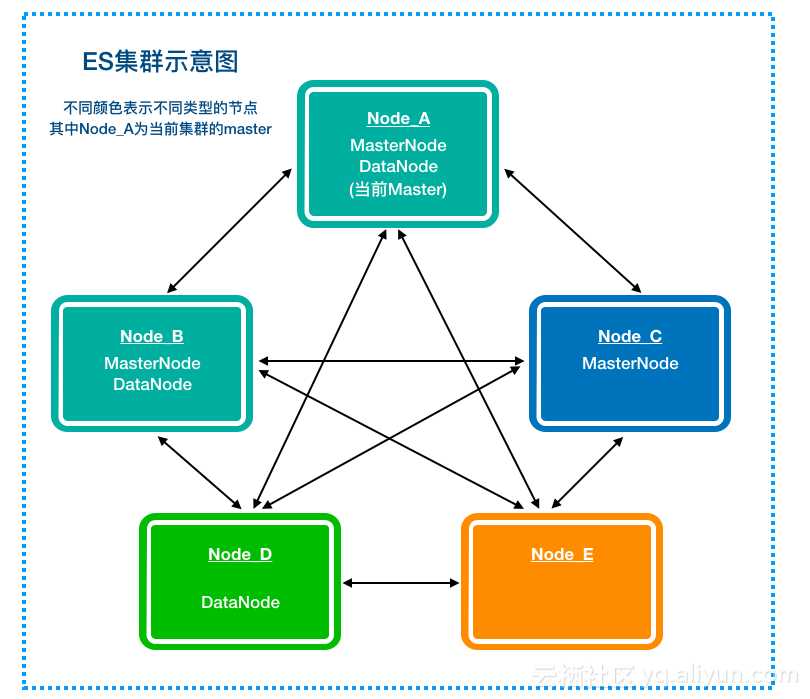
ES的节点可以通过两组配置项来决定每个节点类型,即"node.master: true/false"和"node.data: true/false",具体类型如下表:
| node.master | node.data | 是否参与选主 | 是否保存数据 | 是否参与计算 | 对应上图节点 |
|---|---|---|---|---|---|
| true | true | 是 | 是 | 是 | Node A/B |
| true | false | 是 | 否 | 是 | Node C |
| false | true | 否 | 是 | 是 | Node D |
| false | false | 否 | 否 | 是 | Node E |
特殊的,像Node E这种又不参与选主,又不保存数据的节点,也是有用的,它可以用来处理用户请求。所有的节点都可以接收并处理用户请求。具体逻辑见后续章节。
ES集群还支持其他的节点类型,在此不展开讨论。
集群内所有节点理论上两两相连(网络异常时允许部分节点之间通讯中断,保证最终整个集群是拓扑连续的即可)。每个节点都会保存与其相连的其他节点的信息,用于选主和路由。节点之间通过Gossip谣言传播算法实现数据交换和最终一致性,具体的原理细节这里就不讨论了。
ES支持数据分片和分片副本:
分片分布在哪个节点上是不固定的,随着集群的数据变化和节点的增加删除,分片会在不同节点之间移动。这个由master主节点来负责协调。具体参见“master主节点”章节。
集群所有节点均可接收用户请求。
2.1章节提到每个节点会保存其他节点的信息,所以当一个用户请求到来时,当前节点负责解析用户请求,并从本地节点列表中选择有相关分片的节点(数据分片往往被打散到不同的节点)将请求转发过去。
对于写请求:
对于读请求:
主节点是由集群自动选举出来的。
集群内有且只能有一个master主节点,它负责集群的协调工作,比如新节点加入、分片的转移等。
根据2.1章节的描述,只有node.master配置为true的节点才有可能成为主节点。
集群选举
关于脑裂
当集群存在两个或以上的master时,我们称之为脑裂。这种情况会导致集群的一致性受到威胁。
略有遗憾的是ES存在小概率的脑裂问题。比如当Node A发起选举,Node X投了一票;但选举迟迟未成功,接着又有个节点发起了一轮投票,刚好这时Node X发现Node B的版本更高,又投了一票给Node B。于是Node X投出了两票,条件契合的情况下,Node A/B可能同时认为自己被选上。这种情况可以通过引入选举周期来解决,同一周期一个节点只投一票,最终选择周期最新的节点为主。
特别注意:只有两个节点的集群,一旦通讯异常,master就选不出来了,因为拿不到总节点数/2 + 1的票数
类似的,当集群有超过半数的节点宕机,集群将变的不可用。
当有节点需要加入集群时,通过给它配置discovery.zen.ping.unicast.hosts: [xx.xx.xx.xx, yy.yy.yy.yy]参数来完成自动发现,加入集群。原理是节点会向上述hosts列表发送请求,寻找master,然后join master。该hosts建议配置成所有的主候选节点。
节点需要退出时,先标记待退出状态,待master将分片全部移走时,才能退出集群。
标签:mamicode head tab 异常 收集 整理 计算 需要 upd
原文地址:https://www.cnblogs.com/JoZSM/p/12455719.html