标签:限制 结构图 知识 https 应用 特殊情况 依次 机制 上进
??这几天写了四篇TCP系列的博客,这一篇是第五篇,也预计是这段时间的最后一篇了,写完这篇我就要开始进行网络层的研究了。若对于我其他TCP方面的博客感兴趣,可以去我个人博客的计算机网络这一分类中查阅。这篇博客就来谈一谈TCP是通过哪些手段,来保证可靠数据传输的。
??研究TCP如何保证可靠数据传输之前,我们先来列举一下网络传输存在什么问题,只有发现了问题,才能对症下药,找出应对的方法。TCP是依靠网络层的IP协议来发送数据,而IP协议是一个不可靠的协议,它仅仅只是尽最大努力传输,但是并不保证数据能够完好地到达,甚至不能保证数据能否到达。同时,网络中允许传输的最大单元(MTU)是有限制的,一般为1500个字节。所以,TCP为了发送比这个大的数据,需要将数据拆分成一个个数据段进行发送。正因为这些原因,网络传输将存在以下问题:
0变成1,或者1变成0;??TCP的实现基本上就是围绕上面三个问题,以及如何提高传输速率实现的。下面我们就来说一说TCP为了应对上面这些问题,做了哪些事情。
??我们先来讨论第一个问题,数据发生损坏。检验数据是否损坏的方式就是数据校验,以下是TCP报文的格式,可以看到其中有一个16位的字段,叫做校验和,这就是接收方用来校验数据是否出错的部分。
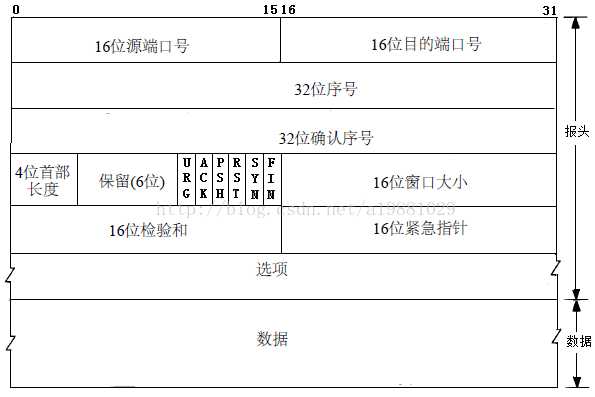
??这个字段的名称叫做校验和,因为TCP对数据校验的方式就是校验和算法,这个算法的过程如下:
0,然后将数据部分以16位为一个单位,进行拆分;17位,则将17位加到第一位(其实就是补码和运算,也称为回卷),最终相加的结果取反(0变成1,1变成0),然后放入校验和字段;0,则认为数据没有出错;??这样是如何起到校验的作用呢?其实很简单,假设在数据传输的过程中,数据没有出错,则在发送端和接收端,求出的结果都是一样的。而校验和字段,就是这个结果的反码,也就是说,结果中为1的位,在反码中就为0,而结果中为0的位,在反码中就是1。也就是说,在数据没有出错的情况下,这个结果与校验和字段相加,一定是全1,而此时再取反,就是0了。所以只要最终求得的结果不是0,接收方就认为数据出错(出错后将如何处理,我暂时没有找到相关的资料,惭愧)。
??但是,上面这个算法一定可以校验出数据是否出错吗?答案是不能。因为这个校验的根本,其实不过是将数据求和,然后判断这个和有没有改变而已。而我们都知道,1+2 == 2+1,1 + 4 == 2 + 3,仅仅依靠求和,根本无法保证数据的没有发生改变。只要数据的多处都发生了错误,而且相互抵消,这种算法将无法察觉。但是TCP依然采用了这种算法,我个人认为原因是实现简单,而且网络中数据出错的概率不高,而多处出错并相互抵消的概率就更小了,所以这种算法的可靠性还是比较高的。
??TCP解决数据丢失的方法就是超时重传。TCP将维护一个计时器,并设置一个超时时间,当发送一个TCP报文段后,没有在超时时间之内得到ACK报文,则发送方将认为数据丢失,于是将重传丢失的报文段,直至接收。由于TCP使用的是流水线传输,在同一时间内,可能有多个已经发送但没有接收到ACK的报文段,所以按理来讲,TCP将维护多个计时器,为每一个报文段绑定一个,但是这样做将产生较大的开销,而且对于计时器的管理也很复杂。所以在TCP中,实际上只会维护一个计时器,记录的是当前最早被发送,但是还没有接收到ACK报文的报文段。当这个报文段超时,发送方将重传报文段,并重启计时器;若收到这个报文段的ACK报文,同样重启计时器,不过此时最早被发出但还没有被确认的报文段已经发生了改变,此时记录的就是这个新的报文段的传输时间。除此之外,触发快速重传时,计时器也会重新启动。关于TCP的流水线传输,可以参考我的这一篇博客:https://www.cnblogs.com/tuyang1129/p/12450978.html。
??这里就有一个复杂的问题了,这个超时时间将要如何设定?不难想到,这个超时时间应该要略大于数据的往返时间(RTT),比如数据从发送到接收到ACK报文,共用了200ms,那超时时间应该略大于这个值,比如400ms。但是网络是不稳定的,对于每一个报文,因为所通过的路径不同,网络拥塞程度的不同,往返时间或多或少都会发生改变。所以对于这个超时时间,应该基于平均RTT进行计算。但是直接统计求平均值就太粗糙了,对于TCP来说,有一套复杂的算法来计算这个超时时间。
??要计算RTT的大致平均值,首先得有样本值,假设样本RTT定义为SampleRTT。TCP程序在运行期间,可能会在任意时刻测量一次SampleRTT,即测量一个报文从发出到接收ACK所用的时间,然后将它用于计算RTT的加权平均值。然后过一段时间再进行一次,并将新测出的SampleRTT用于更新加权平均值。假设这个加权平均值RTT定义为EstimatedRTT,在TCP规范中,计算EstimatedRTT的公式为:
EstimatedRTT = (1- α)*EstimatedRTT + α * SampleRTT(公式一)
??其中SampleRTT就是最新测得的样本RTT,通过以上公式就能动态地确定RTT的加权平均值。由于越晚测量的SampleRTT,越接近网络中当前的状况,所以在更新EstimatedRTT的过程中,最新的SampleRTT应该要占据更多的比重,所以在TCP规范中,建议将α的值设定为1/8,所以上面的公式就是:
EstimatedRTT = 0.875 * EstimatedRTT + 0.125 * SampleRTT
??而SampleRTT与EstimatedRTT的波动图如下所示:
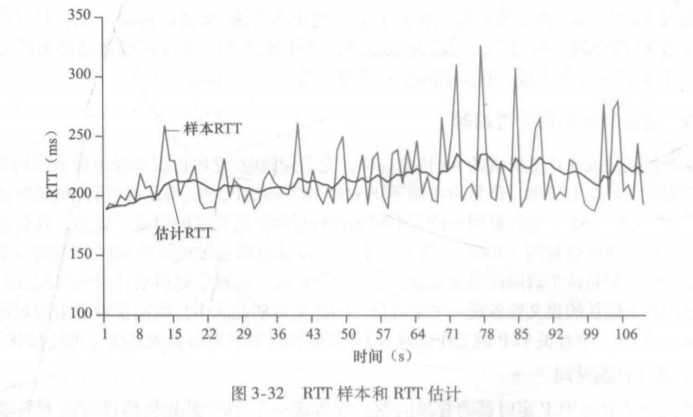
??除了求RTT的加权平均值,网络中RTT的变化情况也是很有必要的,毕竟从上图可以看出,样本RTT的波动十分剧烈,只有EstimatedRTT,还不足以让我们准确的估算超时时间。所以我们需要求出SampleRTT与EstimatedRTT的偏离程度,也就是类似于方差,根据方差,来动态地设置超时时间。假设这个方差定义为DevRTT,则TCP规范中定义DevRTT的计算公式如下:
DevRTT = (1 - β)* DevRTT + β * | SampleRTT - EstimatedRTT |(公式二)
??由上面公式可以看出,如果SampleRTT 的波动很大,DevRTT的值就会很大,反之就会很小。而在TCP规范中β的推荐值是0.25。我们现在知道了RTT的加权平均值,也知道了RTT的波动情况,现在就该考虑怎么设置超时时间了。不难想到,超时时间应该需要比RTT的加权平均值,也就是EstimatedRTT要大一些,让大部分报文段的RTT都小于这个值,以免频繁超时重传。那应该大多少呢?这样考虑,当网络波动较为剧烈时,表示实际RTT应该会离EstimatedRTT远一些,而波动较小时,实际RTT应该会接近于EstimatedRTT,而这个波动情况的数值,我们已经计算过了,就是上一个公式中的DevRTT,所以假设超时时间定义为TimeoutInterval,TCP规范推荐使用以下方式来计算它的值:
TimeoutInterval = EstimatedRTT + 4 * DevRTT(公式三)
??这样,不论是加权平均值还是网络的波动情况就都考虑到了。而TCP规范中推荐的初始TimeoutInterval为1s(当时从书上看到这部分内容,才深刻体会到了数学的强大,真真的将理论应用于实际)。当然,对于超时时间的计算,还有两个特例:
RTT时,不会选择重传的报文段作为样本,这是因为,当发生超时事件时,发送方并不知道数据是因为丢失还是因为网络延迟而超时。若报文段是因为延迟而超时,则重传报文后,这时延迟的ACK报文到达,发送方将误以为重传的分组被正确接收,于是将测出一个错误的SampleRTT 。??总之,TCP的超时重传机制,很好地解决了网络中发生数据丢包的问题。而且,为了提高效率,TCP还有一种快速重传机制,可以根据特定情况,在超时前就判断报文段丢失,然后进行重传,不过这里就不详细叙述了。
??第三个问题就是数据的乱序到达问题。由于网络的限制,TCP必须将较大的数据拆分成一个个较小的报文段,封装成TCP报文段,逐个传输。由于网络传输的不确定性(比如所通过的路径不同,某个报文段丢失然后重传等),这些报文段完全有可能不是按照顺序到达。所以,为了在接收方能够完整的接收数据,并能按序将这些报文组合起来,TCP必须有一种机制解决这个问题。
??TCP所使用的方法就是为每一个TCP报文段分配一个序号,每个报文段的序号依次增加,这样接收方就可以根据序号,来确定接收到的报文段是整个数据中的哪一部分,以及是否接收到了所有的部分。从上面那张TCP报文结构图中我们可以看到,其中有一个32位的序号字段。但是,TCP对报文段的编号可不是0,1,2,3....这么简单,下面我们就来说说TCP是如何实现这种序号机制的。
??首先我们要明确一个点,TCP是对字节进行编号,而不是对报文段进行编号。TCP对需要发送的数据的每一个字节都赋予了一个编号,比如第一个字节为0号,第二个为1号,以此类推。而每一个报文段一般都不止封装一个字节的数据,所以在TCP报文段中,封装的是这个报文段的数据中,第一个字节的序号。举个例子,比如说发送方要发送250字节的数据,假设初始序号从0开始,则这250个字节的序号分别是0-249。再假设每一个报文段最多允许封装100个字节的数据,所以第一个报文段将封装第1到100个字节,这些字节的序号为0-99,所以第一个报文段会将0放入它首部中的序号部分;而第二个报文段封装100-199号字节,所以它的序号为100;而第三个报文段封装200-249号字节,所以它的序号为200。以上就是TCP发送方对序号的处理方法。
??下面来说一说TCP的接收方如何在这种序号机制中工作。同样以上面三个报文段举例,假设发送方将上面三个报文段发出,接收方接收到第一个报文段,发现这个报文的序号是0,同时包含100个字节的数据,于是接收方将会向发送方确认已经接收到这个报文,而确认的方式就是使用TCP首部中的确认序号字段。接收方接收到序号为0,长度为100个字节的报文段后,将会在ACK报文的确认序号中填入100,表示自己已经接收到序号小于100的全部字节,希望下一个接收到的报文段的序号是100;而第二个报文段按序到达,序号为100,长度为100字节,于是接收方再次回送ACK报文,此时确认序号将为200,表示自己接收到200以前的全部字节,希望下一条报文的序号是200;然后接收到序号为200,长度为50字节的报文段,将回送确认序号为250的ACK报文。
??以上是按顺序接收到报文段的情况,假设在上面的情况中,三条报文到达的先后顺序是0 -> 200 -> 100,也就是顺序被打乱,则将发生以下情况:
0,长度100字节的报文段,回送确认号为100的ACK报文;200,长度为50字节 的报文段,此时接收方希望接收到的是100号报文,于是判断发生了乱序到达的情况,不向上层交付这一段数据,而是将其放入接收缓存;100,长度为100的报文段,100正是接收方期待接收到的报文段序号,于是将其接收并交付给上层,同时发现在接收缓存中存在序号为200的报文段,这正是接收方期待接收到的下一条报文,于是将其取出,交付上层,同时向发送方发送ACK报文,ACK的确认序号为250,表示自己已经接收到250之前的所有字节,下一条期望到达的报文的序号是250;??通过上面的机制,接收方成功解决了数据乱序到达的问题。当然,对于这种序号机制的使用,其实不止这么简单,这其中还牵涉到TCP的流水线传输机制,若想要了解,可以参考我的另外一篇博客——https://www.cnblogs.com/tuyang1129/p/12450978.html。
??这里还有一个问题,在上面的例子中,我假设序号是从0开始,但是实际情况并非如此。在实际的实现中,序号一般是一个通过特殊算法计算出的随机值,这样做的原因有两点:
TCP连接的序号都是从0开始,那么假设客户端先向服务器发送了一个报文,还没有确认接收后,立即断开连接;但是在断开后,它们立刻又建立了一个连接,而此时,第一次发送出去的报文段才刚到达服务器,那会发生什么情况。服务器会以为这是新建立的连接发送的数据,而由于两次连接的初始序号都是0,接收方将会把这个报文段接收。为了减小类似情况发生的概率,TCP采用随机初始序号,这样两次连接的初始序号将大概率不同,再发生这种情况时,接收方也不会接收这个报文段;??流量控制与拥塞控制,严格来讲并不是TCP的可靠传输机制,但是也算是有点关系,所以我还是提一下。
TCP的接收方会维持一个接收缓存,用以接收发送方发送的数据。但是,接收缓存不是无限大的,若接收缓存被占满,此时再接收到数据,将无法进行接收,只能将其丢弃。于是,为了减少这种情况的发生,TCP接收方需要告知发送方,自己最多还能接收多少数据,TCP发送方根据这个信息,有选择的发送数据,这就是流量控制;??这两种机制中,流量控制相对简单。我们可以看到,在TCP的报文格式中,有一个叫做窗口大小的部分,这部分就是接收方告诉发送方,自己当前最多还能接收多少数据,而发送方将发送小于这个窗口大小的数据长度。但是有一种特殊情况,若这个窗口大小为0,表示当前窗口已满,正常情况下发送方将无法发送数据,但是在实际情况中,发送方还是会发送一个字节的数据到接收方,作为一种试探。因为接收方一般不会主动向发送方发送报文,这个窗口大小一般是携带在ACK报文中,若此时窗口大小为0,发送方将不再发送数据,接收方也就无法向发送方发送ACK报文,此时就算缓存被清理,发送方也不会知晓。所以即使这个窗口大小为0,发送方仍然需要发送数据,进行试探,若缓存已经被清理,通过试探报文的ACK报文,发送方就能知晓。
??拥塞控制是TCP中相对复杂的一种机制,不是三言两语说的清楚的,这部分内容我专门写了一篇的博客进行说明,感兴趣的可以阅读一下:https://www.cnblogs.com/tuyang1129/p/12439862.html。
??对于TCP可靠传输的描述就介绍到这里。上面的内容是对TCP可靠传输原理的基本介绍,但是具体实现可能会在这些基础上进行改进和优化。TCP的各种机制相辅相成,若是对于TCP没有太多了解,可能有些介绍会看不太懂,所以若想真正搞懂TCP以及其他计算机网络的相关知识,建议买一本书系统地研究。希望我的这篇博客对看到的人有所帮助,若博客内容有误,希望可以指正。
??《计算机网络——自顶向下方法(原书第七版)》
标签:限制 结构图 知识 https 应用 特殊情况 依次 机制 上进
原文地址:https://www.cnblogs.com/tuyang1129/p/12458592.html